
1.ToTTo:表から文を抽出する能力を測るためのデータセット(1/2)まとめ
・自然言語生成は元の文章に存在しない幻覚のような文章を生成してしまう事がまだある
・既存のデータセットでは幻覚の原因がデータノイズなのかモデルの欠点なのか特定が困難
・ToTToは注釈の精度が高いためモデルの幻覚を評価するために使用可能な新しいデータセット
2.ToTToとは?
以下、ai.googleblog.comより「ToTTo: A Controlled Table-to-Text Generation Dataset」の意訳です。元記事の投稿は2021年1月15日、Ankur ParikhさんとXuezhi Wangさんによる投稿です。
表形式データを扱うモデルは過去にもTAPASなどが発表されていましたが、様々な手法があるので優劣を図るためにはデータセット/ベンチマークが必要になりますね、と言う事でToTToの登場となります。
ToTToはTable-To-Textの簡潔な表記との事です。どうみてもoが一つ多いですが、totが動詞としては「合計を決定する」の意味を持つので、これとのひっかけもあるのかな、と思います。余談ですがtotalって「tot」の派生語なんですね。
更にtotは名詞としても「ちびっこ、小児、飲み物の一杯」などの意味があるようなので、もしかして黒柳徹子さんの「窓際のトットちゃん」ってこれから来たのかな、と思ったのですが、あのトットは舌足らずで発音しきれなかった徹子だそうです。
って事でそこから連想したアイキャッチ画像のクレジットはPhoto by Juan Encalada on Unsplash
ここ数年、テキストの要約などのタスクに使用される自然言語生成の研究は、目覚ましい進歩を遂げました。しかし、高レベルの流暢さは達成してはいますが、ニューラルネットワークを使ったシステムは幻覚(hallucination:ハルーシネーション、つまり、理解は可能だが翻訳元の文意に忠実ではない文章を生成してしまう)を起こしやすい可能性があり、高い精度を必要とする多くのアプリケーションでこれらのシステムを採用する事の妨げとなる可能性があります。
Wikibioデータセットでの事例を考えてみましょう。以下では、ベルギーのサッカー選手であるConstant Vanden Stock選手について書かれたウィキペディア情報ボックスを要約することを目的としたタスクで、ニューラルネットワークの基本モデルが、彼がアメリカのフィギュアスケート選手であると誤って要約しています。

生成されたテキストの元コンテンツへの忠実性を評価する事は困難な場合がありますが、元コンテンツが構造化されている場合(表形式など)は、多くの場合簡単です。
更に、構造化データは、推論と数値推論のためのモデルの能力をテストすることもできます。ただし、既存の大規模な構造化データセットはノイズが多いことが多く(例えば、参照文を表形式のデータから完全に推測できない)、モデル開発における幻覚の測定には信頼性がありません。
論文「ToTTo: A Controlled Table-To-Text Generation Dataset」では、モデルの幻覚を評価するために使用できる制御されたテキスト生成タスクとともに、新しい注釈プロセス(文の改訂を介して)を使用して作成されたオープンドメインのテーブルからテキストへの生成データセットを提示します。
ToTTo(Table-To-Textの簡潔表記)は、121,000のトレーニングサンプルと、開発およびテスト用のそれぞれ7,500のサンプルで構成されています。注釈の精度が高いため、このデータセットは、高精度のテキスト生成の研究のための挑戦的なベンチマークとして適しています。データセットとコードは、GitHubリポジトリでオープンソースとして公開されています。
表から文章の生成
ToTToにより、制御された生成タスクを導入できます。
具体的なタスクとしては、テーブルに記載されている内容を意識して、セルの内容を要約する単一の文の説明を作成するタスクです。ここでは、選択されたセルを含む特定のWikipediaテーブルがタスクの元ソースとして使用されます。
以下の例では、数値的推論、分野を特定しない多くの語彙に対応する能力、様々なテーブル構造など、タスクによってもたらされる多くの課題のいくつかを示しています。
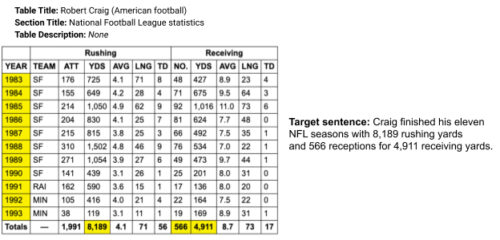
ToTToデータセットの使用例
元テーブルと強調表示されたセルのセット(左)が与えられると、タスクの目標は「ターゲット文」(右)などの1つの説明文を生成することです。
ターゲット文を生成するには、数値推論(NFLの11シーズン)とNFLに関する理解が必要になることに注意してください。
注釈付けプロセス
表形式のデータから自然な文章でありながら明確なターゲット文を取得するように注釈付けプロセスを設計することは、重要な課題です。
WikibioやRotoWireのような多くのデータセットは、人の手を介さずに生成したテキストを経験則的にテーブルとペアにします。
このやり方は、幻覚が主にデータノイズによるものなのか、モデルの欠点によるものなのかを解明するのを困難にするノイズの多いプロセスです。
一方、注釈付け作業者にターゲット文を最初から作成して貰う事もできます。これはテーブルに忠実ですが、結果として得られるターゲットは、構造やスタイルの点で多様性に欠けることがよくあります。
対照的に、ToTToは、注釈付け作業者が既存のWikipediaの文を段階的に修正する新しいデータ注釈付け戦略を使用して構築されています。これにより、興味深く多様な言語特性を含む、クリーンで自然なターゲット文が得られます。
データの収集と注釈付けのプロセスは、Wikipediaからテーブルを収集することから始まります。
ここで、特定のテーブルは、経験則に従ってサポートページの文脈から収集された要約文とペアになっています。例えば、ページテキストと表の間の単語の重複や、表形式のデータを参照するハイパーリンクなどをヒントにこれを行います。
しかし、この要約文は、表でサポートされていない情報が含まれている場合があります。また表内にのみ存在する先行詞や代名詞が含まれている場合があります。
次に、注釈付け作業者は、要約文を捕捉するテーブル内のセルを強調表示し、テーブルで補足されていない要約文内のフレーズを削除します。
また、文を文脈に依存しない独立文(例えば、代名詞を正しく置き換え)に修正し、必要に応じて正しい文法に修正します。
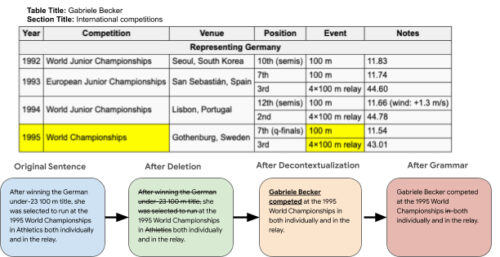
注釈付け作業者が上記のタスクで高い合意を得ていることを示します。セルの強調表示は0.856Fleiss Kappa、最後のターゲット文は67.0BLEUのスコアを示しています。
3.ToTTo:表から文を抽出する能力を測るためのデータセット(1/2)関連リンク
1)ai.googleblog.com
ToTTo: A Controlled Table-to-Text Generation Dataset
2)arxiv.org
ToTTo: A Controlled Table-To-Text Generation Dataset
3)github.com
google-research-datasets / ToTTo

