
1.DALL·E:文章から画像を作成(3/3)まとめ
・DALL·EはGPT-3同様、説明と手がかりを与えるだけで追加学習なしで様々なタスクを実行可
・視覚IQテストでは簡単な類推問題は解く事ができたが複雑な問題は解く事ができなかった
・地理的知識、時間的知識もいくつかの点で驚くほど正確だが幾つかの点では間違う
2.DALL·Eの機能の検証
以下、openai.comより「DALL·E: Creating Images from Text」の意訳です。元記事の投稿は2021年1月5日、Aditya Rameshさん、Mikhail Pavlovさん、Gabriel Gohさん、Scott Grayさん、Mark Chenさん、Rewon Childさん、Vedant Misraさん、Pamela Mishkinさん、Gretchen Kruegerさん、Sandhini Agarwalさん、Ilya Sutskeverさん、Justin Jay Wangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Erik Mclean on UnsplashにWebBigDataがダリの顔を合成
ゼロショットの視覚的推論
GPT-3は、説明と手がかりを与えるだけでさまざまなタスクを実行するように指示できます。追加のトレーニングなしで、入力文で指示された事に対する回答を生成できます。
例えば、「公園で犬を散歩している男(a person walking his dog in the park)」というフレーズのフランス語への翻訳指示には、GPT-3はフランス語で「un homme qui promène son chien dans le parc」と答えます。
この機能は、ゼロショット推論(zero-shot reasoning)と呼ばれます。DALL·Eはこの機能をビジュアル領域に拡張しました。正しい方法で入力された指示を受けた時に、画像から画像への変換タスクをいくつか実行できることがわかりました。
(スマートフォンの場合はフリックで左右にスライドできます。)


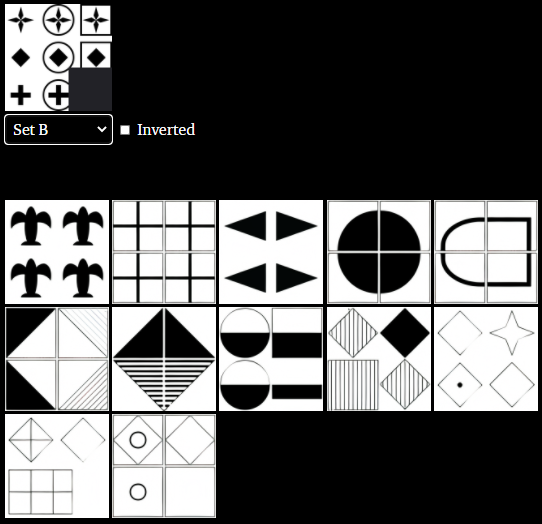
このような機能が出現するとは予想していなかったため、ニューラルネットワークやトレーニング手順を変更してそれを促進することはしませんでした。これらの結果に動機付けられて、20世紀に広く使用された視覚IQテストであるRavenのプログレッシブ行列でテストすることにより、類推問題に対するDALL·Eの適性を測定しました。
選択問題として扱うのではなく、DALL·Eに各画像の右下隅を完成させ、視覚的に一致している場合はその完成が正しいと見なしてテストしました。DALL・Eは以下のSet Bのような単純なパターンや基本的な幾何学的推論の継続を伴う行列配置の問題は解くことができる場合がありました。非常に難しいパターンはほとんどを正しく解く事ができませんでした。
地理的知識
DALL·Eは地理的事実、有名な地理的目印、およびその近隣について学習している事がわかります。これらの概念に関する知識は、いくつかの点で驚くほど正確であり、他の点では欠陥があります。




時間的知識
空間によって変化する概念に関するDALL·Eの知識を探求することに加えて、時間とともに変化する概念に関するDALL·Eの知識も探求しました。
入力画像
20世紀の電話の変遷の写真
(a photo of a phone from the 20s)
出力画像


従来の研究と今回のアプローチの要約
DALL·Eは、テキストと画像の両方を1280トークンの単一入力(テキスト用に256、画像用に1024)として受信し、それらすべてを自動回帰的にモデル化する、単純なデコーダーのみのtransformerです。64層のself-attentionレイヤーのそれぞれにあるattention マスクにより、各画像トークンは全てのテキストトークンに参加できます。
DALL·Eは、テキストトークンには標準的なマスクを使用し、画像トークンにはsparse attentionと、レイヤーに応じて、行、列、または畳み込みattentionパターンのいずれかを使用します。アーキテクチャとトレーニング手順の詳細については、次の論文で提供する予定です。
テキストから画像を合成するアプローチは、テキストのembeddingsで調整されたGANを使用するアプローチを採用したReed et. alの先駆的な研究以来、活発な研究分野となっています。
embeddingsは、CLIPとは異なり、対照的な損失を使用して事前トレーニングされたエンコーダーによって生成されます。StackGANおよびStackGAN++は、マルチスケールGANを使用して、画像の解像度を拡大し、視覚的な忠実度を向上させます。
AttnGANは、テキストと画像の特徴表現の間にattention を組み込み、補助的な目的として、テキストと画像の対照的な特徴表現のマッチング損失を提案します。
これは、オフラインで行われるCLIPを使用した再ランク付けと比較すると興味深いものです。他の研究では、トレーニング中に追加の教師ソースを組み込んで、画質を向上させます。
最後に、Nguyen et. alとCho et. alの研究では、事前にトレーニングされたマルチモーダル識別モデルを活用する、画像生成のためのサンプリングベースの戦略を検討しています。
VQVAE-2で使用されている棄却サンプリング(rejection sampling)と同様に、CLIPを使用して、全てのインタラクティブビジュアルの各説明文の512サンプルの上位32を再ランク付けします。この手順は、一種の言語ガイド付き検索と見なすこともでき、サンプルの品質に劇的な影響を与える可能性があります。
犬の散歩をするバレリーナ姿の大根の赤ちゃんのイラスト[2048画像中のベスト8] (an illustration of a baby daikon radish in a tutu walking a dog[best 8 of 2048])


3.DALL·E:文章から画像を作成(3/3)関連リンク
1)openai.com
DALL·E: Creating Images from Text

