
1.エンドツーエンドモデルによる多言語リアルタイム音声認識(2/2)まとめ
・多言語モデルはトレーニングセット内に頻繁に表れる言語の特徴表現からより多くの影響を受ける
・利用可能なデータが多い言語から多くの影響を受けてしまうので言語情報を入力に加えた
・残留アダプター形式で特定言語には対応するアダプタのみが適用されるように調整を行った
2.残留アダプターモジュールとは?
以下、ai.googleblog.comより「Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model」の意訳です。元記事の投稿は2019年9月30日、Arindrima DattaさんとAnjuli Kannanさんによる投稿です。
大規模データの課題
多言語モデルのトレーニングに大量の実世界のデータを使用する際、言語によって利用可能な学習用データの量に偏りがある事が事態をより複雑にします。
言語の使用者の人数分布が大きく異なる事と、現在の音声関連商品の成熟度合を考えると、言語ごとに利用可能な転記データの量が異なることは驚くことではありません。
その結果、多言語モデルは、トレーニングセット内に頻繁に表れる言語の特徴表現からより多くの影響を受ける傾向があります。この偏りは、従来のASRシステムとは異なり、追加の言語内テキストデータにアクセスできず、音声トレーニングデータのみから言語の語彙特性を学習するE2Eモデルでより顕著です。
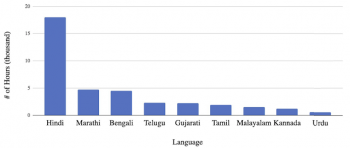
9つの言語のトレーニングデータのヒストグラム。利用可能なデータの大きな差を示しています。
アーキテクチャを幾つか変更して、この問題に対処しました。最初に、トレーニングデータの言語設定を元に追加の言語識別子を入力として提供しました。例えば、個人のスマートフォンに設定されている言語設定の情報などです。この信号は、ワンホットの特徴表現ベクトルとしてオーディオ入力と結合されます。
モデルが言語の曖昧さを取り除くためだけでなく、必要に応じてデータ量の不均衡解決に役立つ「個別の言語」の「個別の特徴」を学習するために、言語ベクトルを使用できると仮定しています。
グローバルモデル内に言語固有の特徴表現を持つアイデアに基づいて、残留アダプターモジュール(residual adapter modules)の形式で言語毎に追加のパラメーターを割り当てることにより、ネットワークアーキテクチャをさらに強化しました。アダプターは、グローバルモデルのパラメーター効率を維持しながら、各言語がグローバルモデルを微調整し、パフォーマンスを向上させるのに役立ちました。
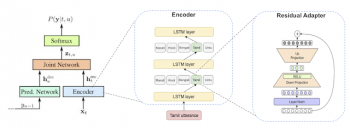
左図:言語識別子を持つ多言語RNN-Tアーキテクチャ。中央図:エンコーダー内の残留アダプター(Residual adapters)。タミル語の発話の場合、タミル語のアダプタのみが各アクティベーションに適用されます。右図:残留アダプターモジュールのアーキテクチャの詳細。 詳細については、私達の論文をご覧ください。
これら全ての要素を組み合わせることで、多言語モデルは単一言語認識エンジンよりも優れており、特にカンナダ語やウルドゥー語のようなデータ不足の言語で大幅に改善されています。更に、ストリーミングE2Eモデルであるため、トレーニング時もサービス提供時もシンプルな実装が可能になり、パーソナルアシスタントなどの素早く応答する事が重要な低遅延アプリケーションでも使用する事ができます。この成果に基づいて、他の言語グループ向けの多言語ASRに関する研究を継続し、広がり続ける多様なユーザーの支援に役立てたいと考えています。
謝辞
この研究への貢献に感謝します。
Tara N. Sainath, Eugene Weinstein, Bo Li, Shubham Toshniwal, Ron Weiss, Bhuvana Ramabhadran, Yonghui Wu, Ankur Bapna, Zhifeng Chen, Seungji Lee, Meysam Bastani, Mikaela Grace, Pedro Moreno, Yanzhang (Ryan) He, Khe Chai Sim。
3.エンドツーエンドモデルによる多言語リアルタイム音声認識(2/2)関連リンク
1)ai.googleblog.com
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
2)arxiv.org
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Learning multiple visual domains with residual adapters

コメント