
1.GO:グラフ最適化用強化学習(3/3)まとめ
・GOはオフライントレーニングとわずかな微調整で初見のグラフにも一般化可能
・全タスクを一度に最適化するマルチタスクGOはシングルタスクGOより7.8%速度が向上
・フレームワークの最適化問題の多くが慎重に設計された学習アプローチで効率的に解決可
2.グラフ最適化用強化学習の性能
以下、ai.googleblog.comより「End-to-End, Transferable Deep RL for Graph Optimization」の意訳です。元記事の投稿は2020年12月17日、Yanqi ZhouさんとSudip Royさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Max Bender on Unsplash
一般化:
GOは、オフラインの事前トレーニングとそれに続く初見のグラフへの微調整を使用して、初見のグラフに一般化できます。事前トレーニング中に、トレーニングセットから抽出した異種グラフのサブセットでGOをトレーニングします。次のグラフに切り替える前に、このようなグラフを使ってバッチごとに1000ステップだけGOをトレーニングします。次に、この事前トレーニング済みモデルは、学習時に除外していたグラフで50ステップ未満(通常は1分未満)で微調整されます(GO-generalization + finetune)。
除外していたグラフのGO-generalization + finetuneは、すべてのデータセットで一貫して人間のエキスパートによる手動配置とHDPの両方を上回り、平均してGO-oneと一致します。
また、トレーニング時に除外していたグラフで微調整することなく、事前トレーニング済みモデルのみで直接推論を実行し、これにGO-generalization-zeroshotという名前を付けます。この微調整されていないモデルのパフォーマンスは、GO-generalization + finetuneよりもわずかに劣りますが、エキスパートの配置やHDPよりもわずかに優れています。これは、グラフembeddingと学習されたポリシーの両方が効率的に転移され、モデルが初見データに一般化できていることを示しています。
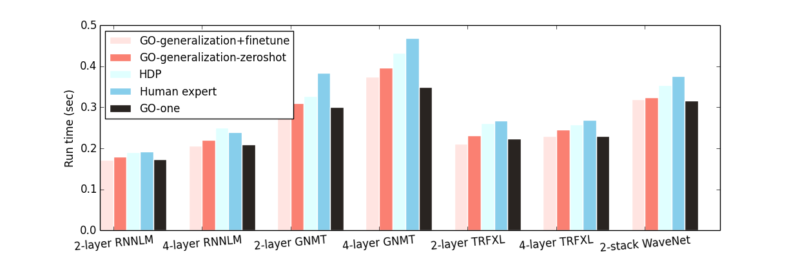
異種作業のグラフ全体の一般化
この図は、6つ(Inception-v3、AmoebaNet、リカレントニューラルネットワーク言語モデル(RNNLM)、Googleニューラル機械翻訳(GNMT)、Transformer-XL(TRFXL)、WaveNet)のうち5つ(検証用に1つを取り除きます)のグラフを使用してトレーニングした場合の、GOの2つの異なる一般化戦略の比較を示しています。検証用に取り除いた作業(x軸)で評価します
配置、スケジューリング、および融合の同時最適化(pl + sch + fu):
配置、スケジューリング、融合を同時に最適化すると、単一GPUの最適化されていない場合と比較して、30%~73%のスピードアップが得られ、TensorFlowのデフォルトの配置、スケジューリング、および融合と比較して33%~60%のスピードアップが得られます。
各タスクを個別に最適化する場合と比較すると、マルチタスクGO(pl + sch + fu)はシングルタスクGO(p | sch | fu)よりもパフォーマンスが高く、全てのタスクを一度に最適化するので平均7.8%の向上です。
更に、すべての作業において、3つのタスク全てを同時に最適化すると、2つを最適化して3番目のタスクにデフォルトのポリシーを使用するよりも実行時間が短縮されます。
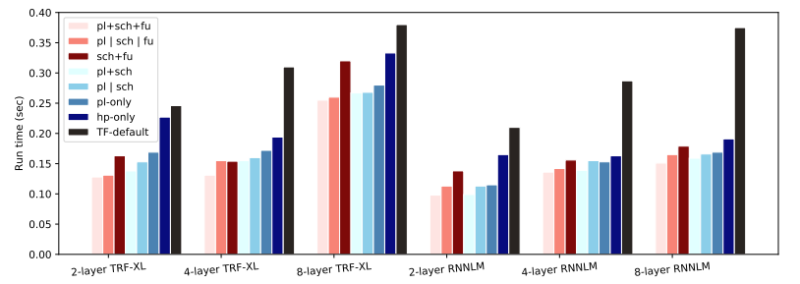
マルチタスク最適化での様々な仕事での実行時間
TF-default:TF GPUのデフォルトの配置、融合、およびスケジューリング
hp-only:デフォルトのスケジューリングと融合を使用した人間による配置
pl-only:デフォルトのスケジューリングと融合を使用してGOを使って配置
pl | sch:GOは、デフォルトの融合を使用して、配置とスケジューリングを個別に最適化
pl + sch:マルチタスクGOは、デフォルトの融合を使用して配置とスケジューリングを共同最適
sch + fu:マルチタスクGOは、スケジューリングと人間の配置と融合を最適化
pl | sch | fu:GOは、配置、スケジューリング、融合を個別に最適化
pl + sch + fu:マルチタスクGOは、配置、スケジューリング、および融合を共同最適化
結論
ハードウェアアクセラレータの複雑さと多様性の高まりにより、堅牢で適応力のあるMLフレームワークの開発は面倒で時間がかかり、多くの場合、何百人ものエンジニアによる数年の努力が必要になります。本投稿では、そのようなフレームワークの最適化問題の多くが、慎重に設計された学習アプローチを使用して効率的かつ最適に解決できることを示しました。
謝辞
本研究は、Daniel Wong, Amirali Abdolrashidi, Peter Ma, Qiumin Xu, Hanxiao Liu, Mangpo Phitchaya Phothilimthana, Shen Wang, Anna Goldie, Azalia Mirhoseini, James Laudonとの共同作業です。
3.GO:グラフ最適化用強化学習(3/3)関連リンク
1)ai.googleblog.com
End-to-End, Transferable Deep RL for Graph Optimization
2)papers.nips.cc
Transferable Graph Optimizers for ML Compilers(PDF)
3)snap.stanford.edu
GraphSAGE: Inductive Representation Learning on Large Graphs

