
1.GO:グラフ最適化用強化学習(2/3)まとめ
・GOはGraphSAGEを利用しておりトレーニング時に見た事がないグラフに対して一般化可能
・GOは規模拡大可能なAttentionが含まれノード間の距離が離れていても依存関係を捕捉可
・GOはパラメータの数を増やすことなく特定のグラフタイプに特化できる仕組みを持つ
2.グラフ最適化用強化学習の概要
以下、ai.googleblog.comより「End-to-End, Transferable Deep RL for Graph Optimization」の意訳です。元記事の投稿は2020年12月17日、Yanqi ZhouさんとSudip Royさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Max Bender on Unsplash
RLポリシーネットワークアーキテクチャ
私達の研究は、前述の最適化問題のそれぞれを個別に、または共同で解決するために使用できるRLフレームワークであるGOを提案しています。提案されたアーキテクチャには、次の3つの重要な側面があります。
まず、グラフニューラルネットワーク(具体的にはスタンフォード大学のGraphSAGE)を使用して、計算グラフにエンコードされたトポロジ情報を捕捉します。GraphSAGEの帰納的ネットワークは、ノード属性情報を活用して、トレーニング時に見た事がないグラフに対しても一般化できます。これにより、トレーニングに多大なコストをかけることなく、トレーニング時に見た事がないデータに関して意思決定が可能になります。
次に、多くのモデルの計算グラフには、多くの場合、10,000を超えるノードが含まれています。このような大規模な最適化問題を効果的に解決するには、ネットワークがノード間の距離が離れていても依存関係を捕捉できる必要があります。GOのアーキテクチャには、規模拡大可能なAttentionネットワークが含まれています。これを利用し、セグメントレベルの繰り返しを使用して、このような長距離ノードの依存関係を捕捉できます。
第三に、MLコンパイラは、様々な応用領域からの様々なグラフの最適化問題を解決する必要があります。異種のグラフを複数使用して共有ポリシーネットワークをトレーニングするという素朴な戦略では、特定のクラスのグラフの特異性を捉えることはできません。これを克服するために、GOは、パラメータの数を増やすことなく、ネットワークが特定のグラフタイプに特化できるようにする特徴変調メカニズム(feature modulation mechanism)を使用します。

GOの概要:グラフembeddingとシーケンシャルAttentionを組み合わせたエンドツーエンドのグラフポリシーネットワーク
複数の依存する最適化タスクを共同で解決するために、GOには、異なるタスク間で共有されるパラメーターを使用して、タスク毎にrecurrent attentionレイヤーを追加する機能があります。アクションのスキップ接続とrecurrent attentionレイヤーにより、タスク間の依存関係を追跡できます。
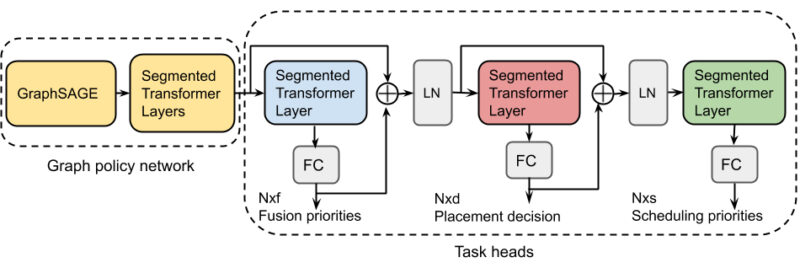
GOのポリシーネットワークを拡張するマルチタスクポリシーネットワーク。タスク毎に追加のrecurrent attentionレイヤーとスキップ接続を持ちます。GE:グラフEmbedding、FC:完全接続レイヤー、Nxf:融合アクションディメンション、Fxd:配置アクションディメンション、Nxs:スケジューリングアクションディメンション。
結果
次に、実際のハードウェア測定に基づいてデバイス配置問題単体でのスピードアップ、様々なタスクを組み合わせたGOのバリエーションを用いて「初見グラフへの一般化」、「操作の融合」、「デバイス配置問題」、「スケジューリング問題」を共同で最適化するマルチタスクパフォーマンスの評価結果を示します。
スピードアップ:
このアーキテクチャのパフォーマンスを評価するために、実際のハードウェア評価に基づいてデバイス配置問題にGOを適用します。ここでは、最初に各作業でモデルを個別にトレーニングします。 GO-oneと呼ばれるこのアプローチは、人間のエキスパートによる手動配置(HP)、TensorFlow METISによる配置、および現在の最先端の強化学習ベースのデバイス配置である階層型デバイス配置(HDP:Hierarchical Device Placement)を常に上回っています。重要なのは、効率的なエンドツーエンドのシングルショット配置により、GO-oneはHDPを介した配置ネットワークの収束時間を15倍高速化することです。
GOは、8層のGoogleニューラル機械翻訳(GNMT)モデルのように、80,000を超えるノードで構成される非常に大きなグラフに規模拡大できるするように設計されているため、HDP、REGAL、Placetoなどの以前のアプローチよりも優れています。GOは、GNMTのような大きなグラフの最適化された実行を実現します。これは、HPおよびHDPよりもそれぞれ21.7%および36.5%高速です。全体として、GO-oneは、HPおよびHDPと比較して、14個のグラフの多様なセット全体で平均20.5%および18.2%の実行時間の短縮を達成します。
3.GO:グラフ最適化用強化学習(2/3)関連リンク
1)ai.googleblog.com
End-to-End, Transferable Deep RL for Graph Optimization
2)papers.nips.cc
Transferable Graph Optimizers for ML Compilers(PDF)
3)snap.stanford.edu
GraphSAGE: Inductive Representation Learning on Large Graphs
