
1.Weak Supervision:機械学習のための新しいプログラミングパラダイム(1/4)まとめ
・weak supervisionとは、SMEからもたらされる高レベル情報、またはノイズの多い情報を活用する事
・過去の同様な手法にはActive LearningやSemi-supervised Learning、Transfer Learningがある
・しかし、過去の手法はラベル付け作業を無くすわけではなくラベル付け作業の負荷低減は不十分
2.Weak Supervisionとは?
以下、ai.stanford.eduより「Weak Supervision: A New Programming Paradigm for Machine Learning」の意訳です。元記事は2019年3月10日、Alex Ratnerさん, Paroma Varmaさん, Braden Hancockさん, Chris RéさんとHazy Labの皆さんによる投稿です。
近年、機械学習(ML)の現実世界への影響は飛躍的に増大しています。
この大部分はディープラーニングの出現によるものであり、これにより機械学習を実践する人は手作業による特徴エンジニアリングをせずとも、ベンチマークデータセットで最先端のスコアを実現する事ができるようになりました。
TensorFlowやPyTorchのような複数のオープンソースのMLフレームワークが利用可能であり、利用可能な最先端のモデルが豊富に存在する事を考えると、高品質のMLモデルは現在、ほぼコモディティ化された、誰でも利用できるリソースであると主張する事ができます。
しかしながら、そこには隠れた落とし穴があります。これらのモデルが人間が手でラベル付けした大量の訓練データに依存している事です。これらの手でラベル付けされたトレーニングセットは作成するのに多額の費用と時間がかかります。
多くの場合、データの構築、整頓、およびデバッグに専任の人間が数カ月、または数年かかって取り組む事になります。ラベル付けに特定の分野の専門知識が必要な場合は特にそうです。
これに留まらず、ラベル付け作業は現実の世界の影響を受けて、しばしば状況が変化したり、従来は考えなくても良かった進化に対応する必要が出てきます。たとえば、ラベリングの方針、どのくらい細かく分類するか、または作業の進め方はしばしば変更され、再ラベリングが必要になります。(例:プラスかマイナスのどちらかにラベル付けする方針だったのが、ニュートラルと言う新しいカテゴリが追加されるなど)
これらすべての理由から、機械学習の実践者は、外部の知識ベース、パターン/規則、または他の分類器を用いて発見的に訓練データを生成するなど、弱い教師形態(weaker forms of supervision)にますます注目しています。基本的に、これらはプログラミングでトレーニングデータを生成するすべての方法、またはより簡潔に言えば、トレーニングデータをプログラミングする方法です。
以下では、トレーニングデータのラベル付けに関して動機を持つMLの領域を確認することから始めます。その後、多様な教師付きデータソースのモデル化と統合に関する私達の研究を説明していきます。
そして、複雑に多様に相互作用する数十から数百の弱い教師付き動的タスクを含む、大規模マルチタスク体制のためにデータ管理システムを構築するという私達のビジョンについても説明します。これらのトピックの詳細な議論などについては、私たちの研究ブログをチェックしてください。
ラベル付きトレーニングデータをもっと入手するためには?
MLにおける伝統的な研究の多くは、ラベル付きトレーニングデータを欲するディープラーニングモデルの飽くなき欲求によって動機付けられています。
私達はこれらのアプローチと弱い教師アプローチの核心的な違いを高次元から俯瞰する事から始めます。
弱い教師(weak supervision)アプローチとは、その領域の専門家(SMEs:subject matter experts)からもたらされる高レベルの情報、そして/または、よりノイズの多い情報を活用することです。
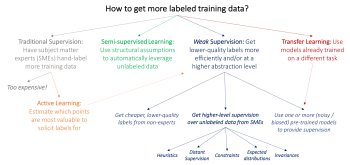
専門家に大量のデータを直接ラベル付けを依頼するという現在主流となっているアプローチの主な問題は、それが高価であるということです。例えば、医療用画像処理の研究用に大規模なデータセットを作るのはとても困難です。大学院生とは異なり、放射線科医は一般的にブリートー(トルティーヤを使ったメキシコの軽食)や無料のTシャツでの支払いを受け付けてくれません!
このため、MLで人気のある研究の多くは、ラベル付けされたトレーニングデータを集める事がボトルネックになっており、データを集める事に対して大きな動機付けがあります。
(1)Active Learning(能動学習)では、モデルにとって最も価値があると推定されるデータポイントにラベルを付けることで、SMEをより効率的に利用することが目標です。(2012年のSettlesによる研究)標準的な教師あり学習では、これはラベルを付ける新しいデータポイントを選択することを意味します。例えば、現在のモデルが癌か癌でないかを決定する境界に近い微妙なラインのマンモグラム(乳癌発見のための乳房のX線撮影画像)を選び、放射線科医にこれらの微妙なラインの写真についてラベル付けを依頼するような事です。
しかしながら、私達はこれらのデータポイントに適切な弱い教師を求める事もできます。その場合、能動学習は弱い教師と完全に補完的です。その一例として、2009年のDruck, Settles, and McCallumによる研究を参照してください。
(2)Semi-supervised Learning(半教師付き学習)での目標は、小さいラベル付きトレーニングセットと、大きなラベルなしデータセットの両方を使用することです。ラベルなしのデータを活用するために、滑らかさ、低次元構造、または距離測定基準に関する仮定を使用します。(生成モデルの一部か識別モデルの正則化、またはcompact data representationを学ぶため)。詳細は2009年のChapelle, Scholkopf, Zienによる研究を参照してください。
大まかに言って、SMEにより多くの入力を求めるのではなく、半教師つき学習のアイデアは、大量に安価に入手できることが多いラベルなしデータを活用するために専門領域とタスクにとらわれずに仮定を活用することです。
より最近の方法はGAN(2016年のSalimans等による研究)、ヒューリスティック変換モデル(2016年のLaine, Ailaによる研究)、意思決定の境界を効果的に正規化するためにその他の生成的アプローチを使います。
(3)典型的なTransfer Learning(転移学習)では、目標はすでに別のデータセットでトレーニングされた1つ以上のモデルを取得し、それらを私たちのデータセットとタスクに適用することです。概要は2010年のPan、Yangによる研究を参照してください。
例えば、私達が体の他の部分にある腫瘍を検出するための大きなトレーニングセットとこのセットでトレーニングされた分類器を持っているとしたら、それらを乳癌を検出するマンモグラフィーの仕事に適用したいと思うかもしれません。今日のディープラーニングコミュニティにおける一般的なトランスファーラーニングアプローチは、1つの大きなデータセットでモデルを「事前トレーニング(pre-train)」してから、関心のあるタスクに合わせてモデルを「微調整(fine-tune)」する事です。
もう1つの関連する研究はmulti-task learning(マルチタスク学習)で、いくつかのタスクを同時に学習する手法です。(1993年のCaruna、2015年のAugenstein、Vlachos、およびMaynardによる研究)。
上記3つのパラダイムは潜在的に、私達がSMEの共同研究者達に追加で訓練ラベルの作成を求めないで済むようにします。
しかし、それでも、データにラベルを付ける必要性は避けられません。もし私達が専門家に様々なタイプのより高レベルの、もしくは、あまり正確でなくても問題ない形式で教師役を求めることができるとしたらどうでしょう?
例えば、放射線科医が一連のヒューリスティック(経験則)に、緩いレベルで正解に近い解を得ることができるようにリソースを振り分ける事に午後の時間を費やしてくれたら、それを適切に活用して、何千というトレーニングラベルに効果的に置き換えることができるでしょうか?
3.Weak Supervision:機械学習のための新しいプログラミングパラダイム(1/4)関連リンク
1)ai.stanford.edu
Weak Supervision: A New Programming Paradigm for Machine Learning
2)aclweb.org
Active Learning by Labeling Features
Extracting Relations between Non-Standard Entities using Distant Supervision and Imitation Learning
3)www.semanticscholar.org
Multitask Learning: A Knowledge-Based Source of Inductive Bias
4)www.cse.ust.hk
A Survey on Transfer Learning
5)arxiv.org
Temporal Ensembling for Semi-Supervised Learning
6)papers.nips.cc
Improved Techniques for Training GANs
7)www.acad.bg
Semi-Supervised Learning

コメント