
1.データ拡張を教師なしで実現し半教師付き学習の性能を向上(1/2)まとめ
・ラベル付きデータが不足している際にデータを水増しする手法は進歩している
・しかし、基本的には教師付き学習でのみ利用可能な手法であった
・今回、ラベルなしデータを教師なしでデータ拡張する手法が発表された
2.教師なしでデータの水増しを実現する手法とは?
以下、ai.googleblog.comより「Advancing Semi-supervised Learning with Unsupervised Data Augmentation」の意訳です。元記事の投稿は、2019年7月10日、Qizhe XieさんとThang Luongさんによる投稿です。
ディープラーニングの成功は、アルゴリズムの進歩、並列処理ハードウェア(GPU/TPU)の開発、およびImageNetのような大規模なラベル付きデータセットが利用可能になった事、などの重要な要因よって可能になりました。
ただし、ラベル付きデータが不足している場合は、ニューラルネットワークを適切にトレーニングすることは困難です。
このような場合、ラベル付けされたトレーニングデータの量を効果的に増やすために、例えば文を言い換えたり画像を回転させるなどのデータを水増しする手法、すなわちデータ拡張手法(data augmentation methods)を適用することができます。近年、自然言語処理(NLP)、視覚処理、および音声処理などのさまざまな分野でデータ拡張アプローチの設計が大幅に進歩しています。
残念なことに、データ拡張は教師付き学習のみに限定されることが多いです。データが水増しにはオリジナルのラベル付きデータが必要なためです。
![]()
テキストベース(上)またはイメージベース(下)のトレーニングデータに対するデータ拡張操作の例。
私達の最近の研究「Unsupervised Data Augmentation (UDA) for Consistency Training」では、ラベルなしデータに対してデータ拡張を実行し、半教師付き学習(SSL:Semi-Supervised Learning)の性能を大幅に向上出来る事を示しました。
私達の研究結果は、最近の半教師つき学習の復活を裏付けるものです。
(1)SSLは桁違いに多くのラベル付けデータを使用する純粋な教師あり学習に勝るとも劣りません。
(2)SSLは文書を扱う分野でも視覚を扱う分野でも良く機能します。
(3)SSLは転移学習と良くコンビネーションする事ができます。(例えば、BERTを微調整するときなど)
また、コミュニティが複製して検証するためのコードをgithubでオープンソース化しました。
教師なしデータ拡張とは?
教師なしデータ拡張(UDA:Unsupervised Data Augmentation)は、ラベル付きデータとラベルなしデータの両方を利用します。
ラベル付きデータを利用する際は、下図の左部分に示したように、教師付き学習でモデルを訓練するための標準的な手法を使用して損失関数を計算します。
ラベルなしデータの場合、グラフの右側に示すように、「ラベルなしデータ」と「ラベルなしデータをデータ拡張した事例」で予測が類似するように、整合性トレーニング(consistency training)が適用されます。
そこでは、「ラベルなしの事例」と「その事例を拡張した事例」の両方に同じモデルを適用し、2つの予測が生成され、そこから一貫性損失(consistency loss)、すなわち2つの予測分布間の距離が計算されます。
次にUDAは、「ラベル付きデータからの教師付き損失」と「ラベルなしデータからの教師なし一貫性損失」の両方を最適化し、最終的な損失を計算します。
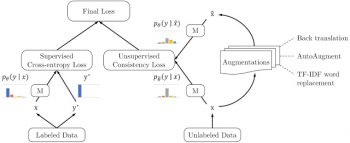
教師なしデータ増強方法(UDA)の概要
左図:ラベル付きデータが利用可能な場合、教師付きで標準的な損失が計算されます。右図:ラベルなしデータの場合、ラベル付き事例とその事例を拡張した事例の間での一貫性損失が計算されます。
一貫性損失を最小限に抑える事で、UDAは「ラベル付きデータ」から「ラベルなしデータ」へ、ラベル情報のスムーズな伝達を可能にします。
直感的には、UDAは暗黙の反復プロセスと考えることができます。まず、モデルは、ラベルなしの事例を正しく予測するために、少量のラベル付き事例に依存しています。そこからラベル情報が一貫性喪失を通じて拡張された事例に伝播します。時間が経つにつれて、ますます多くのラベルなしの例が正しく予測されるようになり、これはモデルの一般化の改善を反映しています。
様々な種類のノイズが一貫性トレーニング用にテストされています。ガウスノイズ(Gaussian noise)、敵対的ノイズ(adversarial noise)などです。それでも、私たちはデータ拡張がそれら全てを凌駕し、言語からビジョンまでの多種多様なタスクで最先端のパフォーマンスを導いていることを発見しました。
UDAは、逆翻訳、自動補完、TF-IDFの単語の置換など、目の前のタスクに応じてさまざまな既存の拡張方法を適用します。
3.データ拡張を教師なしで実現し半教師付き学習の性能を向上(1/2)関連リンク
1)ai.googleblog.com
Advancing Semi-supervised Learning with Unsupervised Data Augmentation
2)github.com
google-research/uda
3)arxiv.org
Unsupervised Data Augmentation for Consistency Training

