
1.Snorkel MeTaLを用いた大規模マルチタスク学習(3/4)まとめ
・自然言語推論(NLI)に関連するデータを用いてマルチタスク学習を実施
・特殊な句読点を使用している文など特殊な事例に関して固有のタスクヘッドを追加して対応
・「もっと多くの教師となる信号が必要です(We need more signal. ?)」で以下次号
2.MTLとデータスライシング
以下、dawn.cs.stanford.eduより「Massive Multi-Task Learning with Snorkel MeTaL: Bringing More Supervision to Bear」の意訳です。元記事は2019年3月22日、Braden Hancockさん, Clara McCreeryさん, Ines Chamiさん, Vincent Chenさん, Sen Wuさん, Jared Dunnmonさん, Paroma Varmaさん, Max Lamさん, そしてChris Réさんによる投稿です。以前、紹介したSnorkelの中で紹介されていたSnorkel MeTaLのお話です。
教師となる信号3.マルチタスクラーニング(Multi-Task Learning)
言語モデリングはモデルに多くのことを教えることができますが、自然言語推論(NLI)のようなより複雑なタスクで最適なパフォーマンスを得るために必要なこと全てを教えることはできません。それには間違いなくさらに深いレベルの自然言語理解が必要です。
したがって、RTEのパフォーマンスをさらに向上させるために、RTEに密接に関連する他のタスクとのマルチタスク学習を実行します。例えば、偶然ですがGLUEベンチマークの他の3つのタスクもNLIタスクです。
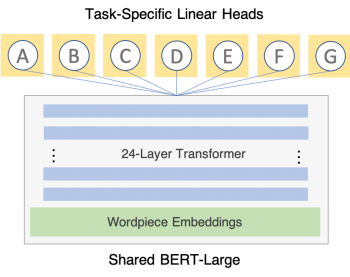
私たちのMTLアーキテクチャは非常に単純です。共有部分(すべてのネットワークパラメータの99.99%以上)は単一のPyTorchモジュール(BERT-Large)で、各タスクはタスクヘッドとしてタスク固有の線形層を持ちます。
マルチタスク学習(MTL)は、共有特徴表現を使用して複数のタスクを予測できる単一のモデルをトレーニングする手法です。(優れた概要についてはSebastian RuderのMTLに関する調査を参照してください)
機械学習アプリケーションに、着目すべき変化をもたらすものは、モデルの構造ではなく教師データであると私達は考えているので、構造は非常に単純にしています。
ネットワークに追加する各タスクは、単純にBERTモジュールの上に線形ヘッド(linear task heads)を追加するだけです。これらの線形ヘッドは、事前学習されたBERTモデルの出力次元(1024次元)を分類タスクの濃度(RTEでは2次元)にマッピングします。
私達のトレーニングスケジュールも同様にシンプルです。取り扱う全てのタスクをバッチに分割し、それらをランダムにシャッフルし、そして各タスクの各トレーニング事例が、その都度、正確に確認できるように一度に一つずつネットワークを通して送ります。
MTLトレーニングを10回繰り返した後、追加の5回のトレーニングで微調整するために、個々のタスクの最善のチェックポイントを探します。これにより、前半のトレーニングで共有情報を活用し、後半のトレーニングでタスク間の有害な干渉を減らすことができます。
MTLトレーニングだけで、RTEは全体的な検証精度が82.3に大幅に(5.8ポイント)向上しました。追加のタスク固有の微調整により更には、最大83.4まで上昇しました。
大規模MTLへの拡大
しかし、MTLが「完全なデータセット」のみを含むように制限する理由はありません。 私たちが使用するSnorkel MeTaL MMTLパッケージは、多数の、多様な、異なった粒度の教師に対してマルチタスク学習を容易にするために特別に構築されたものです。
このため、任意のネットワークモジュール、データタイプ、およびラベルタイプをサポートしています。たとえば、文章単位で付与したラベルとトークン単位で付与したラベルを混在させることができます。
思考実験として、以下を考えましょう。誤った結果を分析したところ、モデルが間違った原因の多くが文法的構造の理解の欠如から生じていたとします。そのため、データセットの各品詞について、既存の構文解析プログラムを使って生成された品詞タグを教師として学習する補助的なタスクを追加する事ができます。もし、相互参照の解決に関連する間違いが疑われる場合は、既存の相互参照解決システムを使用してMTLモデルの学習用ラベルを作成する事もできます。
これらのトークンレベルのラベルは、独自のバイアス、エラーモード、および死角を持つ別のモデルの出力であるため、確かに完全ではありません。ただし、これらの補助タスクラベルを生成するモデルは、通常、非常に大きなラベル付きデータセットを使用してトレーニングされているため、私達が教師信号として活用したいと思う有用な信号を出力します。
これまでのところ、私たちのリーダーボードには従来のマルチタスク学習の事例しか含まれていませんが、将来的にはこのMMTLの分野で利用可能な信号を更に探索する予定です。
もっと多くの教師となる信号が必要です ?
教師となる信号4.Datasetの小分割
訳注:原文はDataset Slicing。スライスチーズのSlice、薄く切るイメージです。「配列のスライス」なんて言い方は技術書には稀に出てきますが、あまりしっくりこないので「小分割」と意訳しました。
モデルのミスを調べたところ、データの特定の一部分に対してモデルのパフォーマンスが常に低下していることがわかりました。
例えば、私たちのモデルは検証データセット全体で83.4の精度を達成しましたが、珍しい句読点(ダッシュ-やセミコロン;)が使われている特殊な事例では76.7のスコアしか得られず、複数の代名詞を含む事例ではわずか58.3でした。
これらの例は、単純に他の平均的な事例より難しかったので、私達のモデルは他のデータセットと同様なパフォーマンスを発揮できなかったのかもしれません。しかし、それは少し特別な仕組み作っても、モデルがこれらの困難な事例に対するパフォーマンスを改善する事ができないという事を意味しているわけではありません。
上述した2つのような発見的方法を使用して、私達はトレーニングセット内の難しい事例をプログラム的に識別しました。(これは、人間による観察や他のモデルからの出力などのノイズの多い上位レベルの信号を使用して、モデルに何らかの教師信号を提供する、弱い教師の別の形式と見なすことができます。)
次に、これらの特殊な事例のそれぞれについて、モデルの上に個別に線形ヘッドを追加し、それぞれ、特殊事例についてのみ学習させます。これにより、ネットワークのごく一部を、パフォーマンスを低下させる特殊な例文の特徴表現の学習に集中させて、パフォーマンスを向上させることができます。
そして、私たちのネットワークパラメータの大部分はタスク間で共有されるので、特殊な例文から学んだ特徴表現の微調整は、(ハードパラメータの共有を介して)そのタスクのプライマリヘッドによっても利用され、全体的なタスクの精度を向上させることができます。前述の2つの事例に対して学習処理を追加すると、スコアはそれぞれ76.7から79.3と58.3から75.0に上がり、全体のRTE検証スコアも84.1になりました。
もっと多くの教師となる信号が必要です ?
3.Snorkel MeTaLを用いた大規模マルチタスク学習(3/4)関連リンク
1)dawn.cs.stanford.edu
Massive Multi-Task Learning with Snorkel MeTaL: Bringing More Supervision to Bear
2)github.com
HazyResearch/metal
3)ruder.io
An Overview of Multi-Task Learning in Deep Neural Networks

コメント