
1.強化学習における好奇心報酬とぐずぐず先延ばしの罠(2/2)まとめ
・強化学習は飴と鞭で人工知能を学習させるが飴も鞭もほとんど発生しない世界では学習できない
・好奇心を満たす事を報酬として組み込む手法が以前より研究されている
・今回発表された新しい手法では従来手法が陥るわなを回避する事ができる
2.驚きベースの好奇心と記憶ベースの好奇心の比較
以下、ai.googleblog.comより「Curiosity and Procrastination in Reinforcement Learning」の意訳です。Google BrainのNikolay SavinovさんとDeepMindのTimothy Lillicrapさんの共著です。前半はこちら
グズグズ先延ばしの罠
論文「Large-Scale Study of Curiosity-Driven Learning」で、ICMメソッドの著者とOpenAIの研究者は、驚きを最大化する事の隠れた危険性を示唆しています。エージェントは、タスクに役立つ何かをする代わりに、先延ばしに似た行動に夢中になってしまう事があります。
原理を知るために、著者が “騒々しいテレビの問題”と呼ぶ実験を考えてみましょう。エージェントが迷路に入り、以前のスーパーマーケット問題のチーズ相当の非常に有益なアイテムを見つけることを任されています。迷路内には、エージェントがリモコンを持っているテレビも含まれています。チャンネル(それぞれ別の番組です)数には限りがあり、リモコンのボタンを押すと番組がランダムに切り替わります。このような環境で人工知能エージェントはどのような行動をするでしょうか?
驚きに基づいた好奇心を定義する数式が原因で、チャンネルを変更すると、それがもたらす変更は予測できないので、大きな報酬が得られます。重要なのは、全ての番組を見た後でも、ランダムにチャンネルが変更される事により、テレビ画面の変化は人工知能にまだまだ驚きをもたらすことです。人工知能エージェントはチャンネル変更後のテレビに関する情報を予測してますが、大抵の場合、間違うためにそれが再び驚きをもたらします。このため、驚きに基づいた好奇心を搭載する人工知能エージェントは、最終的には、ぐずぐずしているかのように、非常に高い報酬のアイテムを探すのではなく、永遠にテレビの前にとどまり続けます。それでは、このように大事な行動につながらない好奇心はなんと定義すべきでしょう?
エピソード好奇心
論文「Episodic Curiosity through Reachability」で、私たちは、「自己満足」に陥りにくいエピソード記憶ベースの好奇心モデルを探求します。なぜそうするのでしょうか?上記の迷宮のテレビのケースでは、しばらくの間チャンネルを変更すると、すべての番組がメモリに保存されます。そうなれば、テレビはもうそれほど魅力的ではありません。たとえ画面に表示される番組の順序がランダムで予測不可能であっても、それらの番組はすべて既に記憶されているのですから!これは、驚きに基づく手法との主な違いです。私たちの手法は、予測するのが難しい(または不可能でもある)未来についての賭けをしません。代わりに、エージェントは過去を調べて、現在のものと同じような観測を見たかどうかを調べるのです。従って、私たちのエージェントは、騒々しいテレビによって提供される即時の満足感にそれほど引き寄せられません。よりよい報酬を得るために、テレビの外で世界を探索しなければならないでしょう。
しかし、エージェントが既存のメモリと同じものを見ているかどうかをどうやって決めているのでしょうか?厳密な一致を確認することは無意味である可能性があります。現実的な環境では、エージェントが全く同じ風景を2回見ることはほとんどありません。たとえば、エージェントがまったく同じ部屋に戻ってきたとしても、その部屋を異なる角度から見ていたら記憶の風景とは異なって見えます。
メモリ内の正確な一致をチェックする代わりに、2つの体験がどれだけ近いかを測定するためにディープニューラルネットワークを使用します。このネットワークを訓練するために、2つの体験が時間的に近いか、時間的に離れているかをを推測します。時間的に近いか否かは、2つの経験が同じ経験の一部である否かを判断するための優れた代替手段として用いる事ができます。このトレーニングは、以下に示す到達可能性を介した新規性という一般的な概念につながります。
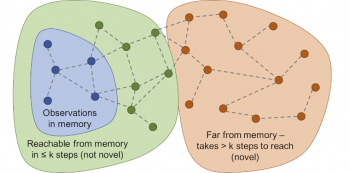
到達可能性のグラフは新規体験か否かを決定します。現実的には、このようなグラフを作成する事はできません。代わりにニューラルネットワークを訓練して、ステップ数を推定します。
実験結果
好奇心を用いる様々なアプローチのパフォーマンスを比較するため、ViZDoomとDMLabの2つの視覚的に賑やかな3D環境でテストしました。これらの環境では、迷路のゴールを探したり、良いものを集めたり、悪いものを避けたりするようなさまざまな問題が人工知能エージェントに課せられました。DMLab環境では、人工知能エージェントにレーザーのようなSF装備が提供されます。
以前のDMLab環境の標準設定は、すべてのタスクに対してエージェントにこのSF装備を持たす事が必須でした。エージェントが特定のタスクにこの装備を必要としない場合は、装備使用しないこともできます。興味深いことに、上記の騒々しいテレビの実験と同様に、驚きに基づくICM手法のエージェントは使う必要がない場面でもレーザーを打ちまくりました。
また、迷路で高価なアイテムを探すタスクを任されたとき、ICM手法のエージェントは壁にタグ(目印)を付ける事に沢山の時間を費やすことが好きです。これは、「驚き」の報酬がたくさん出るためです。理論的には、タグ付けの結果は予測可能であるべきですが、標準的なエージェントに物理演算に関する深い知識を持たせる事は、実際は困難です。

驚きをベースとするICMメソッドは、迷路を探索するのではなく、壁にタグを付け続けます。
我々の方法は、同じ条件下で代わりに合理的な探査行動を学びます。これは、その行動の結果を予測しようとするのではなく、すでにエピソード記憶にあるものではなく達成するのが「難しい」風景を求めるためです。言い換えれば、エージェントは暗黙的に、単にタグ付け動作に熱中するのではなく、記憶にない到達に多くの努力を必要とする目標を追求するのです。

我々の方法は合理的な探索を行います。
面白いことに、報酬を付与する私達の手法は、グルグルと円を描いて行動するエージェントに負の報酬(ペナルティ)を課しています。これは、最初の一週が完了した後、エージェントがメモリ内に新しい風景を齎さないため、報酬を受け取れないためです。

報酬の視覚化:赤はペナルティ、緑は報酬を意味します。左図:報酬の存在する地図、真ん中:現在記憶されている場所の地図、右図:一人称視点の迷路
同時に、私達の手法は良好な探査行動を行います。

報酬の視覚化:赤はペナルティ、緑は報酬を意味します。
左図:報酬の存在する地図、真ん中:現在記憶されている場所の地図、右図:一人称視点の迷路
私たちの仕事が、驚きを超えてもっと知的な探査行動を学ぶ新しい探査方法のトレンドに繋がることを願っています。私たちの方法の詳細な分析については、私たちの研究論文のプレプリントを見てください。
謝辞
このプロジェクトは、Google Brainチーム、DeepMindとETHZürichの協力の結果です。
コアチームには、Nikolay Savinov、Anton Raichuk、RaphaëlMarinier、Damien Vincent、Marc Pollefeys、Timothy Lillicrap、Sylvain Gellyが含まれます。この論文についての議論のために、Olivier Pietquin、Carlos Riquelme、Charles Blundell、Sergey Levineに感謝したいと思います。私たちは、イラストを借りたIndira Paskoにも感謝しています。
(前半「強化学習における好奇心報酬とぐずぐず先延ばしの罠(1/2)」の続きです)
3.強化学習における好奇心報酬とぐずぐず先延ばしの罠(2/2)関連リンク
1)ai.googleblog.com
Curiosity and Procrastination in Reinforcement Learning
2)arxiv.org
Episodic Curiosity through Reachability


コメント