
1.ディープラーニングを使った網膜眼底画像からの屈折異常予測(2/3)まとめ
・網膜画像から屈折異常などを発見するためにディープラーニングが役に立つかを評価
・非常に高い精度で屈折異常を発見できる事と窩領域を人工知能が重視した事がわかった
・結論としてディープラーニングが医療用画像から新規予測を行うために適用できる
2.網膜異常検出アルゴリズムの開発
以下、iovs.arvojournals.orgより「Deep Learning for Predicting Refractive Error From Retinal Fundus Images」の意訳、三部作です。第一部はこちら
ディープニューラルネットワークは一連の数学的操作です。しばしば画像のピクセル値のような数百万のパラメータ(重み)が入力として使われます。ディープラーニングとは、このパラメータが、網膜の眼底写真のピクセル値から予測を生成する等の所与のタスクを実行するように、適切なパラメータ値を学習するプロセスとみなす事ができます。
ディープラーニングのためのオープンソースソフトウェアライブラリであるTensorFlowをモデルのトレーニングと評価に使用しました。
開発のためのデータセットは、「学習」と「チューニング」の2つの部分に分けられました。
チューニングセットは一般に「検証」セットとも呼ばれますが、臨床検証セット(学習時に使わずに学習済みの人工知能の性能を検証するために使うデータセット)との混乱を避けるため、チューニングセットと呼ぶ事にしました。
学習、チューニング、および臨床検証データセットは、被験者の属性が均等になるように分割されました。
学習時、ニューラルネットワークのパラメータは当初ランダム値に設定されます。次に、各画像について、人工知能が出力する予測と学習セットの症例が比較され、人工知能の出力が学習セットの症例に近づくように各パラメータを少しずつ修正していきます。確率的勾配降下として知られているこのプロセスは、訓練セット内のすべての画像に対して、画像の各画素から人工知能が正確な予測が出来るようになるまで繰り返されます。
チューニングデータセットは、人工知能の学習時に使用しなかったデータセットですが、人工知能モデルをチューニングするための小さな評価データセットとして使用されました。この評価セットは、英国Biobankデータセットの10%とAREDSデータセットの11%で構成されていました。
適切な調整および十分なデータにより、得られたモデルは、新しい画像上のラベル(例えば、屈折異常)を予測することができました。
本研究では、ResNet16とソフトアテンションアーキテクチャを組み合わせたディープニューラルネットワークを設計しました。
簡単に言えば、ネットワークは、入力画像のサイズを減らすレイヤー、予測画像の特徴を学習するための3つの残差ブロック、最も有益な特徴を選択するためのソフトアテンションレイヤー、および選択された特徴間の相互作用を学習する完全に連結された2つのレイヤーからなります。
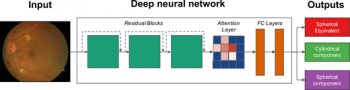
概要図。眼底画像は、3つの残差ブロック、最も予測に重要な眼の特徴を学習するためのアテンションレイヤー、および完全に接続された2つの層からなる深いニューラルネットワークの入力を形成します。モデル出力はSE、円柱成分、球成分です。モデルパラメータは、入出力の例を示すことによって、データ駆動方式で学習されます。
トレーニングの前に、画質フィルタアルゴリズムを適用して、品質の悪い画像を除外しました。これにより、英国バイオバンクのデータセットの約12%を除外しています。 AREDS画像の大部分は良質であったため、AREDS画像はいずれも除外していません。画質フィルタアルゴリズムは、モデルの安定性を高めるために他のラベルに加えて画質を予測するために手作業でラベル付けされた300の画像で訓練された畳み込みニューラルネットです。このモデルは、非常に品質の悪い(例えば、完全に過剰または露出不足の)画像を除外するように調整されました。
除外画像の例は補足図S1にあります。除外された画像の集計分析は補足表S1にあります。訓練とチューニングのために画像を前処理し、Gulshanらと同じ手順に従ってニューラルネットワークを訓練しました。球状出力、円柱出力、SEを予測するために別々のモデルを訓練しています。
チューニング・データ・セットのパフォーマンスに基づく早期停止基準を用いて、チューニング・データ・セット上の平均絶対誤差(MAE)などのモデル性能が改善しなくなったときに、オーバーフィッティングを回避するため、トレーニングを終了させました。結果をさらに改善するために、我々は同じデータで訓練された10のニューラルネットワークモデルの結果を平均(アンサンブル学習)しています。
ネットワークの構造
今回のニューラルネットワークは、画像から特徴を抽出するResNet( residual network)、抽出した特徴を理解して最も重要な特徴がどれかを選択するsoft-attentionレイヤー、及び選択された特徴間が相互に及ぼす影響を学習するfully connectedレイヤー、から構成されます。
特に residual networkは、1つの畳み込みレイヤーと、3つのresidual blocksから構成されます。3つのresidual blockはそれぞれ、4つ、5つ、2つのresidual unitsを含みます。それぞれのresidual unitsは、3つの畳み込みレイヤーから構成されるボトルネック構造になっています。
このようなresidualアーキテクチャは、より深いネットワーク(今回の場合は34層)を可能にし、より抽象的な特徴を学習し、より高い予測精度を実現します。
重要なのは、スキップ接続により、ネットワークがresidual unitsを飛び越えて、異なる抽象レベルと解像度で特徴を再利用できる事です。これにより、次のアテンションレイヤーがより正確にローカライズされた予測イメージの特徴にアクセスできるようになります。
residual networkの出力は畳み込み特徴マップAで、Ai,Ajはそれぞれ空間(i、j)から学習された特徴です。
続いてソフトアテンション層で、特定の画像領域の重要性を示すスカラー重みWi、Wjを各位置(i、j)について予測し、これにより画像のどの部分がもっとも予測に重要なのか理解できるようにします。(例えば網膜画像の中心窩が最も予測時に重視されている事など)
私達は予測に使う特徴の重みWi、Wjをヒートマップとして視覚化することにより、個々のAttentionマップを生成しました。そしてまた、複数の画像のAttentionマップを平均化することによって集約されたAttentionマップを生成しました。
ソフトアテンション層の出力は、Wi、Wjの重みを平均化したAi、Ajによって得られる単一の特徴ベクトルです。
ソフトアテンション層の後には、fully connectedレイヤーと出力レイヤーが続き、SEと球形および円筒形の部品も予測します。
アルゴリズムの評価
我々は、屈折誤差を予測するモデルの性能を評価するため、MAEを最小化するように最適化しました。また、R2値も計算しましたが、これはモデル性能の選択には使用されませんでした。さらに、アルゴリズムのパフォーマンスを詳しく調べるために、アルゴリズムの予測が特定のエラーマージン内に収まった頻度を調べました(統計分析セクションを参照)
統計分析
これらの結果の統計的有意性(偶然良い結果がでたのではない事を確認する事)を評価するために、ノンパラメトリックブートストラップ手順を使用しました。検証セットからN個のサンプルを取り出し、このサンプリングしたデータを用いてモデルを評価しました。
このサンプリングおよび評価を2000回繰り返すことによって、パフォーマンス基準(例えば、MAE)の分布を計算し、2.5および97.5パーセンタイルを95%信頼区間(CI)を得ました。我々は、アルゴリズムのMAEと、実際の屈折誤差と平均屈折誤差のMAEを計算することによって生成されたベースライン精度とを比較してみました。
統計的有意性をさらに検証するために、我々は、各予測が誤差マージン内にあるか片側二項検定を用いて仮説検定を行いました。誤差範囲に等しいサイズのウインドウをヒストグラムにわたってスライドさせ、合計されたヒストグラムカウントの最大値をとる事で、帰無仮説に対応するベースライン精度が得られます。これにより最大限のランダム精度が得られました。
Attention Maps
予測する際に最も重視されたのは眼球のどの箇所かを視覚化するために、私たちはネットワークアーキテクチャにソフトアテンションレイヤを統合しました。このレイヤーは、前の層によって学習された入力画像の特徴を取り込み、各特徴について予測を行うための重要度を予測し、加重平均として出力します。予測された特徴をヒートマップとして視覚化することにより、個々の画像の注目を集めた箇所の地図を生成できます。我々は地図を平均化することによって個々の画像の予測で注目を集めた部分を集約し、注意マップ(Attention Maps)を生成しました。
3.ディープラーニングを使った網膜眼底画像からの屈折異常予測(1/3)関連リンク
1)iovs.arvojournals.org
Deep Learning for Predicting Refractive Error From Retinal Fundus Images

コメント