
1.プライバシーに配慮しながら医療現場の略語を解読可能な機械学習を実現(1/2)まとめ
・多くの人が医療記録にアクセスできるようになったが専門的な略語が含まれているため理解する事が困難
・医療現場で使われる略語は一般的でないものや重複するものがあるので機械にとっても扱うのが難しい
・機密情報が含まれないウェブ上の公開データを使って臨床略語を解読可能なモデルを学習させる事に成功
2.医療用略語の難しさ
以下、ai.googleblog.comより「Google Research, 2022 & beyond: Responsible AI」の意訳です。元記事の投稿は2023年1月24日、Marian Croakさんの投稿です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成で左側はまぁ、ナウシカと主張しても大丈夫に思えますが、右側は、うーん、単なる赤毛で青い服を着ているお医者さんのような気もしてきてテトが側にいてくれないとちょっと厳しいレベルな気もしてきます。しかし、安心してください、リアル系テトがリス化してしまう問題は更なる改良が計画されています。
現在、多くの人が医師の診療メモを含む医療記録にデジタルでアクセスできるようになっています。しかし、臨床記録は、臨床医が使用する専門的な言語であり、聞き慣れない速記や略語が含まれているため、理解することが困難です。実際、このような略語は何千とあり、その多くは特定の医療専門分野や地域特有のものであったり、異なる文脈で複数の意味を持つことがあります。
例えば、医師が臨床ノートに「PT referred to pt for lbp」と書くことがありますが、これは、以下のような内容を伝えるものです。
「患者は腰痛のために理学療法を指示された」
略語の中には日常言語では一般的でないものもあり(例えば「lbp」は「腰痛(lower back pain)」を意味します)、また「患者(patient)」を意味する「pt」のような馴染みのある略語でも、「理学療法(physical therapy)」のような別の意味を持つことがあるので、この翻訳を思いつくのは素人やコンピューターにとっては難しいのです。
複数の意味を曖昧にしないためには、周囲の文脈を考慮する必要があります。すべての意味を解読するのは簡単なことではありません。先行研究では、短縮形や略語を非省略形に変更することで、患者が自分の健康、診断、治療についてより深く理解できるようになることが示唆されています。
Nature Communications誌に掲載された論文「Deciphering clinical abbreviations with a privacy protecting machine learning system」では、臨床略語(clinical abbreviations)を解読する汎用的な手法について、このタスクにおける最先端かつ認定医に匹敵する結果を報告しています。
私達は、患者と関連付けられていないウェブ上の公開データ(つまり、機密性の高いデータが潜在的に存在しない)のみを使用してモデルを構築し、異なる医療システムの入院患者および外来患者の臨床医から得た、非識別化された実際のメモで性能を評価しました。このモデルをウェブデータからメモに一般化するために、大量のインターネットテキストをあたかも医師が書いたかのようにアルゴリズムで書き換えるウェブ規模の逆置換法(WSRS:Web-Scale Reverse Substitution)と、新しい推論方法である誘発推論法(elicitive inference)を開発しました。

モデルの入力は医学的略語を含む、または含まない文字列です。私達は、すべての略語を同時に検出・展開した文字列を出力するようにモデルを学習させました。入力文字列に略語が含まれていない場合、モデルは元の文字列を出力します。(Rajkomar等による研究。CC4.0ライセンスの元で切り出し)
医療用略語を含むようにテキストを書き換える
医師の診断書を翻訳するシステムを構築するには、通常、すべての略語にその意味がラベル付けされた、大規模で代表的な臨床テキストのデータセットから始めることになります。しかし、研究者が一般的に使用できるそのようなデータセットは存在しません。そこで私たちは、このようなデータセットを自動的に作成する方法を開発しました。ただし、実際の患者のメモには機密情報が含まれている可能性があります。また、このデータで学習したモデルが、複数の病院施設や外来・入院患者のようなケアの種類からなる実際の臨床記録でもうまく機能することを確認したいと考えました。
そこで、数千の臨床略語とその非省略形を収録した辞書を元に、非省略形が使われている文章をウェブ上で探し出しました。次に、非省略形を略語に置き換えました。その結果、医師が書いたような文章ができあがりました。例えば「心房細動の患者は胸痛を起こすことがある」という文章がある場合、「pts with af can have cp. 」と書き直します。そして、この省略された文章をモデルの入力とし、元の文章をラベルとして使用しました。この方法で、略語展開のモデルを学習させるためのデータを大量に得ることができました。
長文テキストをその略語に「逆置換」するというアイデアは先行研究で紹介されましたが、私達の分散型アルゴリズムにより、この手法を大規模なウェブサイズのデータセットに拡張することが可能になりました。WSRS(web-scale reverse substitution)と呼ばれるこのアルゴリズムは、よりバランスのとれたデータセットにするためにインターネットを参考にして、希少な用語の出現頻度を高め、一般的な用語の出現頻度を低めるように、設計されています。
このデータをもとに、一連の大規模なtransformerベースの言語モデルの学習をウェブ規模のテキストに拡張しました。
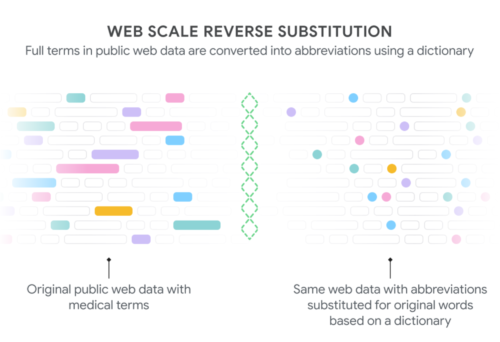
私たちは、公開されたウェブページから、対応する医療略語(左の色付きボックス)を持つフレーズを抽出し、適切な略語(右の色付き〇)に置き換えることで、解読タスクのモデルを訓練するためのテキストを生成しました。ある単語は他の単語よりも頻繁に見つかるため(「patient」は「posterior tibialis」よりも多く、どちらも「pt」と略すことができます)、何千もの略語の中でよりバランスのとれたデータセットを導き出すために、良く使われる略語は数を減らしました。Rajkomar等による CC BY 4.0 の下で使用。
3.プライバシーに配慮しながら医療現場の略語を解読可能な機械学習を実現(1/2)関連リンク
1)ai.googleblog.com
Deciphering clinical abbreviations with privacy protecting ML
2)www.nature.com
Deciphering clinical abbreviations with a privacy protecting machine learning system

