
1.ReAct:わからなかったらググって、ググった情報を元にもう一度ググって必要な情報を探せる人工知能(1/2)まとめ
・言語モデルは様々なタスクに応用されているが学習済の知識しか利用できない
・また、長期的な視点にたって行動するための一時的な記憶を持つ事もできない
・ReActは行動と行動結果に対する推論を繰り返してタスクを実行する新しい考え方
2.ReActとは?
以下、ai.googleblog.comより「ReAct: Synergizing Reasoning and Acting in Language Models」の意訳です。元記事は2022年11月8日、Shunyu YaoさんとYuan Caoさんによる投稿です。
Reactと聞くとMeta(旧FaceBook)のJavaScriptライブラリが有名ですが、今回のお話は次世代のプロンプトに繋がるお話です。
プロンプトと聞くと、最近はStableDiffusionに好みの絵を描いて貰うための神秘的な呪文と思っている人が多いかもしれませんが、元々は言葉を扱う人工知能(言語モデル)に望みの行動を起こしてもらうための工夫であって、例えばTwitterのツイート内容が肯定的な内容なのか否定的な内容なのかを調べるなんて事をやるための工夫であったりしました。
直近で有名な改善では思考の連鎖(chain-of-thought)プロンプトがあって、これは、ステップバイステップで考える事を言語モデルに教えるプロンプトで、標準的なプロンプトであれば
Q
太郎君は500円を持って買い物に行き、100円のリンゴを2つ買い、その後、50円のみかんを3つ買いました。太郎君は今いくら持っていますか?
A
150円
といった感じで導入部のプロンプトを与えた後に以下のように本当に解決して欲しい本題を与えていました。
Q
次郎君が初めに持っていたお金は1000円です。150円のブロッコリーを3本買い、その後、20円のチョコを20個買いました。次郎君は今いくら持っていますか?
思考の連鎖プロンプトの場合は導入部のプロンプトのQの部分は同じですが、Aで段階的に考える事を教えます。
A
100円のリンゴ2つは200円です。リンゴを2つ買った後に太郎君が持っているお金は500円 – 200円 = 300円です。50円のみかん3つは150円です。みかん3つを買った後に太郎君持っているお金は300円 – 150円 = 150円です。
答えは150円です。
本題として与えるプロンプトも同じですが、導入部に思考の連鎖プロンプトを与えておくと、本題の回答時も導入部のプロンプトと同様に段階的に記述するようになり、その結果、正答率があがるというプロンプトの与え方だけで人工知能の性能が激増するという衝撃的なお話でした。
今回のReActはこの技法が更に発展して「行動」と「行動結果に対する推論」を交互に行えるように工夫したと言うお話です。後半に出てくる具体例で言えば、
「Seven Brief Lessons on Physicsという本はイタリア人によって書かれました。このイタリア人は何年からフランスで働いていますか?」
という、人間でもまず、著者名を調べて、その著者名に対してフランス在住歴を調べるという二段階手順を踏むような質問に答える事が出来るようになったと言う事です。
「google is your friend(ググレカス)」なんて言葉もそう遠からず過去の言葉になり本当に人間の方が得意な事がどんどん無くなっていきそうだなぁ、と感じます。
アイキャッチ画像はstable diffusionの1.5版の生成でリアクション芸人として活躍中のトトロ
近年の進歩により、言語モデル(LM:Language Models)の下流タスクへの適用が拡大しています。
一方、思考の連鎖(chain-of-thought)によって適切なプロンプトを与えられた既存の言語モデルは、質問から答えを導き出すための自己条件付き推論トレース(self-conditioned reasoning traces)を実行する能力を得て、様々な算術、常識、記号推論タスクに秀でる事ができます。
しかし、思考の連鎖プロンプトでは、モデルは外界に基盤を持たず、自身の内部表現を用いて推論の道筋を生成するため、反応的に探索・推論したり、知識を更新する能力が制限されます。
一方、最近の研究では、様々な対話環境(テキストゲーム、ウェブナビゲーション、具現化タスク、ロボット工学など)における計画と行動のために、事前に学習した言語モデルを用いており、言語モデルの内部知識を介してテキストの文脈をテキストの行動にマッピングすることに重点を置いています。しかし、これらの言語モデルは、高レベルの目標について抽象的に推論したり、長期的な視野での行動をサポートするためのワーキングメモリを保持することはありません。
「ReAct: Synergizing Reasoning and Acting in Language Models」では、言語モデルが様々な言語推論と意思決定タスクを解決できるように、「推論と行動(reasoning and acting)」を組み合わせた汎用的なパラダイムを提案します。
私達は、Reason+Act(ReAct)パラダイムが、より大きな言語モデルのプロンプトや小さな言語モデルの微調整を行う際に、推論のみや行動のみのパラダイムより系統的に優れていることを実証しています。
また、推論と行動の緊密な統合により、解釈可能性、診断可能性、制御可能性を向上させる、人間に合わせたタスク解決の軌跡を提示します。
モデルの概要
ReActは、言語モデルが言語を使った推論と文章による行動の両方を交互に生成することを可能にします。
行動は外部環境(下図の「Env」)からの観察フィードバックにつながりますが、推論は外部環境に影響を与えません。その代わり、文脈を推論し、将来の推論と行動をサポートするために有用な情報でそれを更新することによって、モデルの内部状態に影響を与えます。
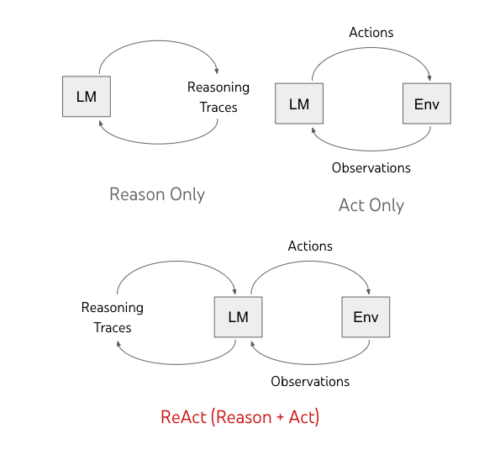
これまでの手法では、言語モデル(LM:Language Models)に自己条件付きで推論の道筋かタスク固有のアクションを生成するように促していました。私達は、言語モデルにおける推論と行動を組み合わせた新しいパラダイムであるReActを提案します。
ReActのプロンプティング
凍結した言語モデルPaLM-540Bに、文脈中の少数の例文をプロンプトとし、タスク解決のために
・「領域固有の行動(domain-specific actions、質問回答における「検索(search)」、部屋案内における「行く(go to)」)」
・「自由形式の言語推論の道筋(free-form language reasoning traces、「今、私はカップを見つけて、テーブル上に置く必要があります」)」
を生成する事に注力します。
推論が重要なタスクでは、推論の道筋と行動を交互に生成し、タスク解決への道筋が複数の推論-行動-観察ステップ(reasoning-action-observation steps)で構成されるようにします。
一方、多数の行動を伴う可能性がある意思決定タスクでは、推論トレースは道筋内で最も関連性の高い位置に出現すればよいので、推論をまばらに実行するようにプロンプトに記述し、言語モデル自身に推論の道筋と行動の非同期発生を決定させるようにします。
以下に示すように「タスク目標を分解して行動計画を作成する」、「タスク解決に関連する常識的知識を注入する」、「観測から重要な部分を抽出する」、「計画の実行しながらタスクの進捗を追跡する」、「行動計画を調整して例外を処理する」など、様々な種類の有用な推論の道筋が存在します。
推論と行動の相乗効果により、モデルは行動するための高レベルの計画を作成、維持、調整するために動的推論(reason to act)を行います。一方で、外部環境(例えば、Wikipedia)と相互作用して追加の情報を推論に取り込む(act to reason)ことができます。
3.ReAct:わからなかったらググって、ググった情報を元にもう一度ググって必要な情報を探せる人工知能(1/2)関連リンク
1)ai.googleblog.com
ReAct: Synergizing Reasoning and Acting in Language Models
2)arxiv.org
ReAct: Synergizing Reasoning and Acting in Language Models

