
1.ReAct:わからなかったらググって、ググった情報を元にもう一度ググって必要な情報を探せる人工知能(2/2)まとめ
・ReActの軌跡を用いてより小さな言語モデルの微調整を行うことも検討中
・ReActが推論を誤った際、人間が道筋を編集して正解にたどり着く事が可能
・ReActは質問回答、事実確認、対話的意思決定タスクにおいて優れている
2.ReActの性能
以下、ai.googleblog.comより「ReAct: Synergizing Reasoning and Acting in Language Models」の意訳です。元記事は2022年11月8日、Shunyu YaoさんとYuan Caoさんによる投稿です。
アイキャッチ画像はstable diffusionの1.5版の生成
ReActの微調整
また、ReAct形式の軌跡(trajectories)を用いて、より小さな言語モデルの微調整を行うことも検討しています。人間による大規模な注釈付けを必要としないように、ReActプロンプトのPaLM-540Bモデルを使って軌跡を生成し、タスクが成功した軌跡を使ってより小さな言語モデル(PaLM-8/62B)を微調整しています。

(a)標準、(b)思考の連鎖(CoT, 推論のみ)、(c)Act-only, (d) ReActの4種類のプロンプトでHotpotQA問題を解く比較。文脈内のサンプルは省略し、タスクの軌跡のみを示しています。ReActは、推論を支援する情報を取り出すと同時に、次に取り出すべき情報を推論によって絞り込むことができ、推論と行動の相乗効果を示しています。
研究成果
質問応答(HotPotQA)、事実検証(Fever)、テキストベースのゲーム(ALFWorld)、ウェブページナビゲーション(WebShop)の4種類のベンチマークにおいて、ReActと最先端の比較対象モデルとの実証評価を行いました。
HotPotQAとFeverでは、モデルが操作可能なWikipedia APIへのアクセスにより、ReActは素の行動生成モデル(action generation models)を上回り、思考連鎖推論(chain-of-thought)の性能と競合します。
また、ReActとCoTの組み合わせで、推論時に内部知識と外部からの情報の両方を利用するアプローチが最も良い結果を示しました。
| HotpotQA (exact match, 6-shot) | FEVER (accuracy, 3-shot) | |
| Standard | 28.7 | 57.1 |
| Reason-only (CoT) | 29.4 | 56.3 |
| Act-only | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| Best ReAct + CoT Method | 35.1 | 64.6 |
| Supervised SoTA | 67.5 (using ~140k samples) | 89.5 (using ~90k samples) |
HotpotQAとFeverでのPaLM-540Bプロンプトの結果
ALFWorldとWebShopにおいて、ワンショットとツーショットのプロンプトを用いたReActは、既存の比較対象手法に比べて、105タスク以下のデモから学習した模倣手法と強化学習手法を上回り、成功率でそれぞれ34%と10%の改善を絶対値で実現しました。
| AlfWorld (2-shot) | WebShop (1-shot) | |
| Act-only | 45 | 30.1 |
| ReAct | 71 | 40 |
| Imitation Learning Baselines | 37 (using ~100k samples) | 29.1 (using ~90k samples) |
AlfWorldとWebShopでのPaLM-540Bプロンプトタスクの成功率結果
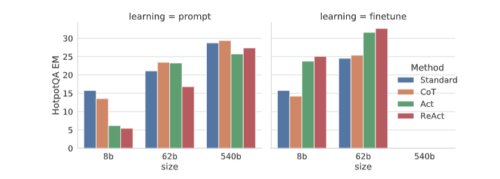
HotPotQAにおけるプロンプトと微調整のスケーリング結果を、ReActと異なる比較対象モデルで比較。ReActは常に最高の微調整性能を達成しています。


Feverの例におけるReAct(上)とCoT(下)の推論軌跡の比較(スペース削減のためReActの観測は省略)。この場合、ReActは正しい答えを出しており、CoTが存在しない幻覚を見てしまうのと対照的に、ReActの推論軌跡はより事実や知識に基づいたものであることが分かります。
また、人間の検査員がReActの推論の道筋を編集できるようにすることで、ReActと人間のループ内相互作用を探りました。ReActは、存在しない幻覚の文章を検査員のヒントで置き換えるだけで、検査員の編集に合わせて行動を変化させ、タスクを成功させることができることを実証しています。ReActを用いると、わずかな思考を手動で編集するだけでタスクの解決が大幅に容易になり、新しい形の人間-機械協調が可能になります。

AlfWorldでReActを用いたヒューマンインザループの行動修正例
(a)ReActの軌跡は、幻覚を見てしまい推論の道筋に失敗(Act 17)
(b)人間の検査官が2つの推論トレースを編集し(Act 17, 23)、ReActが望ましい推論の道筋と行動を生成し、タスクを完了させます。
まとめ
言語モデルにおいて、推論と行動を相乗的に行うシンプルかつ効果的な手法であるReActを紹介しました。マルチホップな質問応答、事実確認、対話的意思決定タスクに焦点を当てた様々な実験を通して、ReActが解釈可能な意思決定トレースと優れたパフォーマンスをもたらすことを示しました。
ReActは、言語モデル内で思考、行動、環境からのフィードバックを共同でモデル化することが可能であることを示し、環境との相互作用を必要とするタスクを解決できる汎用的なエージェントであることを実証しました。私たちは、この研究成果をさらに発展させ、大規模なマルチタスク訓練やReActと同等に強力な報酬モデルと結合といったアプローチにより、言語モデルの強力な潜在能力を活用して、より幅広い具現化タスクに取り組むことを計画しています。
謝辞
Jeffrey Zhao、Dian Yu、Nan Du、Izhak Shafran、Karthik Narasimhanの各氏には、この研究に多大な貢献をしていただきました。また、GoogleのBrainチームとPrinceton NLP Groupの皆様には、プロジェクトのスコープ作成、アドバイス、洞察に満ちた議論など、共同でサポートとフィードバックをしていただきました。
3.ReAct:わからなかったらググって、ググった情報を元にもう一度ググって必要な情報を探せる人工知能(2/2)関連リンク
1)ai.googleblog.com
ReAct: Synergizing Reasoning and Acting in Language Models
2)arxiv.org
ReAct: Synergizing Reasoning and Acting in Language Models

