
1.UL2 20B:オープンソースとして公開された200億パラメータを持つ統一言語モデル(2/2)まとめ
・UL2は異なる事前学習から得られる能力と帰納的バイアスをモデルに付与可能
・従来モデルは微調整タスクとプロンプトベースの1ショットタスクはトレードオフ
・UL2はPaLMとT5を同程度計算コストであるにもかかわらず性能で上回る
2.UL2 20Bの性能
以下、ai.googleblog.comより「UL2 20B: An Open Source Unified Language Learner」の意訳です。元記事は2022年10月14日、 Yi TayさんとMostafa Dehghaniさんによる投稿です。
アイキャッチ画像はstable diffusionの生成
混合ノイズ除去器(mixture-of-denoisers)
UL2フレームワークは、事前学習の目的を混合してモデルを学習させ、異なる事前学習タスクから得られる能力と帰納的バイアスをモデルに与えるために使用することができます。学習を混合させる事は、モデルが異なるタスクの長所を活用し、他のタスクの短所を軽減するのに役立ちます。例えば、混合ノイズ除去器(mixture-of-denoisers)は、範囲破損(Span corruption)のみのT5モデルとは対照的に、プロンプトベースの学習能力を強く向上させることができます。
UL2は3つのノイズ除去タスクの混合を用いて学習されます。
(1) R-denoising(regular span corruption)。これは標準的なT5 span corruptionの目的をエミュレートするものです。
(2) X-denoising(extreme span corruption)
(3) S-denoising(sequential PrefixLM)
事前学習では、ユーザが指定した比率(すなわち、R、X、S-denoiserの異なる組み合わせ)に基づき、利用可能なノイズ除去タスクからサンプリングし、入力とターゲットを適切に準備します。そして、入力にノイズ除去タスクを示すパラダイムトークンを付加します。([R]、[X]、[S]のいずれか1つ)

UL2の混合ノイズ除去器で使用されているノイズ除去の目的についての概要
学習パラダイム間のトレードオフの改善
既存の言語学習パラダイムの多くは、性能の微調整やプロンプトベースの文脈内学習(in-context learning)など、ある1つのタイプのタスクや応用に秀でています。
以下のグラフでは、異なるタスクにおけるベースラインの目的関数をUL2と比較して示しています。また、UniLMが提案するベースライン目的関数は、CausalLM(GPT等)、PrefixLM、Span Corrupt(T5と表記)、およびUniLMが提案するベースライン目的関数を示しています。これらの目的関数を用いて、デコーダのみのアーキテクチャ(緑)とエンコーダ・デコーダ間のアーキテクチャ(青)を学習し、目的関数とアーキテクチャの異なる組み合わせを2つの主要なタスクセットで評価しました。
(1)SuperGLUEでのパフォーマンス測定による微調整(下のグラフのy軸)
(2)文脈内学習:1ショットGEMタスク(例:XSUM、SGDまたはSchema guided dialog、TOTTO)に対するモデルの性能を測定(下のグラフのx軸)
既存の言語学習パラダイムの多くでは、これら2つのタスクにおけるモデルの品質がトレードオフの関係にあることが知られています。UL2は、文脈内学習と微調整の間のトレードオフを埋めることができることを示します。
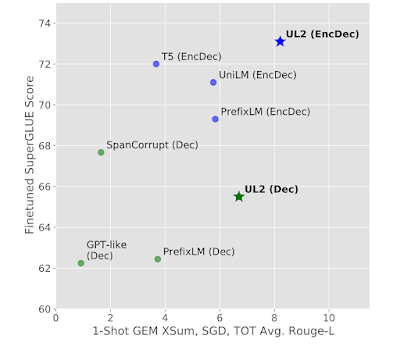
UL2は、デコーダのみ、エンコーダとデコーダの両方のセットアップにおいて、微調整した識別タスクとプロンプトベースの1ショット自由形式テキスト生成の間の性能のバランスが、従来の方法と比較して大幅に改善されています。(計算コスト、すなわちFLOPsは全モデルで同等です。エンコーダデコーダモデルは3億、Decモデルは1.5億パラメータです)
UL2による少数ショットプロンプトと思考の連鎖を使った推論
UL2をスケールアップし、200億パラメータのエンコーダ・デコーダモデルをC4コーパスで学習させ、UL2 20Bモデルの素晴らしい能力を実証しました。
UL2は強力な文脈内学習器であり、少数回のプロンプトと思考の連鎖(CoT:chain-of-thought)プロンプトの両方に優れています。以下の表では、XSUM要約データセットにおいて、UL2と他の最先端モデル(T5 XXLやPaLMなど)を比較し、プロンプトの数が少ない場合にUL2が優れていることを示します。その結果、UL2 20BはPaLMとT5を、計算コストが同程度であるにもかかわらず、上回っていることが分かりました。
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
| LaMDA 1370億 | – | 5.4 | – |
| PaLM 620億 | – | 11.2 | – |
| PaLM 5400億 | – | 12.2 | – |
| PaLM 80億 | – | 4.5 | – |
| T5 XXL 110億 | 0.6 | 0.1 | 0.6 |
| T5 XXL 110億 + LM | 13.3 | 2.3 | 10.7 |
| UL2 200億 | 25.5 | 8.6 | 19.8 |
ワンショット要約(XSUM)におけるUL2とT5 XXL、PaLM、LamDA 1370億との比較。生成された要約を参照用の優れた要約と比較して品質を把握するROUGE-1/2/L(高いほど良い)で比較
CoTプロンプトの結果は、GPT-3 175B、PaLM 540B、LaMDA 137Bなどの大規模な言語モデルを用いて得られているものがほとんどです。本発表では、一般に公開されているUL2 20BでCoTプロンプトによる推論が可能であることを示し、また、従来の思考連鎖プロンプトを利用したモデルより数倍小さいことを示します。
これにより、研究者がCoTプロンプトと推論に関する研究を身近な規模で行うことができる道が開かれました。以下の表では、UL2において、様々な難易度の数学単語問題(GSM8K、SVAMP、ASDiv、AQuA、MAWPS)において、CoTプロンプトが標準プロンプトよりも優れていることを示しています。また、自己一貫性(self-consistency)がさらにパフォーマンスを向上させることも示しています。
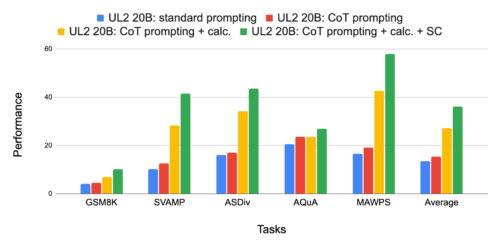
5つの算術推論ベンチマークにおける思考の連鎖(CoT:chain-of-thought)プロンプトと自己一貫性(SC:Self-Consistency)の結果
結論と今後の方向性
UL2は、多くの微調整タスクや小数ショットタスクにおいて、優れた性能を発揮します。私達は、200億個のパラメータを持つ最高性能のUL2モデルのチェックポイントを公開し、機械学習コミュニティ全体において、より優れた言語モデルの開発がより速く進展することを期待しています。
謝辞
Vinh Q. Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Denny Zhou, Neil Houlsby and Donald Metzlerと共にこの研究に取り組むことができたのは名誉であり特権でした。
さらに、Alexey Gritsenko, Andrew M. Dai, Jacob Devlin, Jai Gupta, William Fedus, Orhan Firat, Sebastian Gerhmann, Nan Du, Dave Uthus, Siamak Shakeri, Slav Petrov およびQuoc Leのサポートと議論に感謝します。また、この研究を可能にした素晴らしいインフラを構築したJaxとT5Xチームに感謝します。
3.UL2 20B:オープンソースとして公開された200億パラメータを持つ統一言語モデル(2/2)関連リンク
1)ai.googleblog.com
UL2 20B: An Open Source Unified Language Learner
2)arxiv.org
UL2: Unifying Language Learning Paradigms
3)github.com
google-research/ul2/

