
1.Stable Diffusionを微調整するために必要な条件の調査まとめ
・Stable Diffusionを独自データで微調整してイラストを改良している人達がいる
・Stable Diffusionを微調整するにはどの程度のデータと予算が必要か調べてみた
・トップレベルは200万円以上かけているが数千円でもそこそこの改良はできそう
2.Stable Diffusionの微調整に関する調査
アイキャッチ画像はstable diffusionの生成で「ポケモンバトルをしているトトロ」と入力した結果です。トトロはモンスターボールを投げられる方かと思っていたら投げる方のようでした、失礼しました。
2022年10月30日追記)途中経過ですがStable Diffusionを微調整した結果を投稿しました。画像データがすくないと過剰適合しがちで調整が難しい感じではあります。
2023年1月4日追記)
本記事で紹介している微調整(Fine Tuning)手法はいわゆる「ネィティブトレーニング(native training)」と言われる正攻法のやり方であり、大量の画像データ+膨大な計算機資源を投入してモデルを微調整する場合に適した手法です。
記事を書いている最中は気軽に出来そうに思えたのですが、画像データが少ないと過剰適合しやすく、多いとお金がかかりまくるという困難さがあります。私自身も何度か挑戦した結果、正直、非常に調整が難しくお金と時間が溶けていく感がありちょっと休憩しています。
Stable Diffusionを学習させる手法や独自モデルを作り出す手法は日々新しい手法が提案されており、現時点では主要なものでも5パターンくらいあって、それらの手法も発表時よりかなり進化しています。ネィティブトレーニングよりは用意する画像も少なくて済み、それでも相当な効果が見込めるため、以下のどれかを先に試してみる事をお勧めします。
(1)DreamBooth
最近は複数概念を取りこむ事などもできるようになったので私の実現したい事とマッチしているので私は良く使っていました。元のモデルを改良するのでファイルそのものは1つで済み、拡張機能なども不要ですが、数GBサイズのファイルになります。
(2)textual inversion
最近は、embeddingという形式でスタイルをプロンプト内に持ち込めるようになっています。AUTOMATIC1111 / stable-diffusion-webui では使い勝手が良いかもしれません。ファイルそのものは1つで数キロバイト程度で済み、ネガティブプロンプトの中でも呼び出せるので独自の地位を確立しています。
(3)ハイパーネットワーク
AUTOMATIC1111 / stable-diffusion-webui では一番実行しやすいかもしれません。最近はあまり見かけません。
(4)マージ
学習させなくても独自モデルを作りだす手法として個人的に少し注目しています。こちらもAUTOMATIC1111 / stable-diffusion-webuiだと使いやすいかもです。マージ手法もだいぶ発展してきており、従来のモデルAとモデルBの重みを半々ずつ足すようなシンプルなものから、前半レイヤーではモデルAを使い後半レイヤーではモデルBを使うような
(5)Lora
GPUメモリが比較的少なくとも学習させる事が可能な手法として最近、注目を集めている手法です。ファイルサイズが小さく、textual inversionと同様にプロンプト内で呼びだす事が出来、その際に強度の指定が可能なので現在主流となってる手法です。LoRAと一括で呼称されていても細かく分類すると3種類のタイプがあり、それらをAUTOMATIC1111 / stable-diffusion-webuiで使用する際は拡張機能のインストールが必要です。
ネィティブトレーニングで満足するレベルのモデルを仕上げるには数万円~数十万円は必要ではないかと現在は思っています。
最近、情熱的な人達はStable Diffusionを独自データで微調整(Fine Tuning)してより好みのイラストを生成しやすいようにしています。
微調整と言えば、微調整で素晴らしい効果が見込めますが、学習用データとして与える事が出来る画像数は3~5枚程度が妥当と論文内で言われていて、より多くのデータでがっつりと学習して貰う事がどうやら難しいようなのです。
ハイハイハイ!!独自データでの微調整、私もやってみたいです!
という事で、まずはStable Diffusionを微調整するには
(1)GPUメモリはどのくらい必要なのか?
(2)どの程度のデータ量でどの程度の成果が得られるのか?
(3)微調整用にはどんな形式のデータ/注釈を用意する必要があるのか?
(4)クラウドをお借りするとしたらトレーニング完了までにお幾らほどになりそうか?
をざっと調べてみました。
(1)GPUメモリは如何ほど必要なのか?
16GBは最低でも必要そうです。
私のRTX-3060(12GB)でもどうにかならないのかと調べてみましたが、DeepSpeedという最適化ライブラリを使うとGPUメモリから溢れた部分をCPU(本体メモリ)やディスクに書き出してトレーニングを継続する事が出来るようなのですが、今のところ、私は混合精度関係のエラーが出てしまい動作させる事が出来ていません。
頑張って動かせたとしてもおそらく速度的に非常に遅いと思われますので、エラー原因を追及したり、お金を貯めてハイエンドなGPU(つまり電気代も高い)を購入するよりはトレーニングはクラウド、実行はローカルPCと割り切った方が効率良さそうだなと感じています。
Colab Pro+なら動かす事は可能ですが、課金仕様が変わってプレミアムなGPUだとそこそこお金がかかるようになってしまいました。
(2)どの程度のデータ量でどの程度の成果が得られるのか?
LambdaというGPUのクラウドサービス等を提供している会社がポケモンのデータセットで微調整したStable Diffusionの出力結果をgithubで公開してくれており、中々良い感じの微調整が出来ているように見えます。

Lambda社のgithubより引用
ポケモンのデータセット(pokemon-blip-captions)自体はhuggingface社のDatasetsで公開されており、データセット長は
833サンプル数
99.7 MB
との事です。
1000以下の画像でもこれだけ良い感じに微調整できるのであれば手の届かないレベルではなさそうです。
なお、huggingface社のdiffusersライブラリのサンプル内でも同データを使ったトレーニングが紹介されているのでdiffusersに慣れている方はそちらのトレーニングコードを参考にするのも良いかもしれません。
(3)どんな形式のデータ/注釈が必要なのか?
Lambda社の学習用サンプルですとhuggingface社のDatasets形式にする必要があり、チラ見すると以下です。
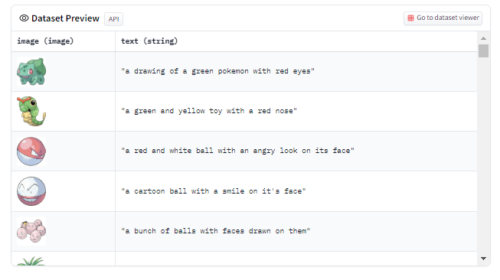
画像+テキストで構造自体は特に複雑ではありません。
また、テキスト自体も画像をsalesforce社のBLIPに与えて出力されたものであり、手動で注釈付けしたものではなく、画像さえ用意できればテキストは割と何とでもなりそうです。
(4)クラウドをお借りするとしたらお幾らほどになりそうか?
前述のLambda社のクラウドサービスであれば、ポケモンのデータセットで微調整するために、2 x A6000 GPUを15,000ステップ(6時間)動かして約$10ドル(1,450円)との事です。
これは、GCPやAWSなどのメジャーなクラウド比で確かにお安いと思います。
ちなみにオープンソースとして公開されたオリジナルのstable-diffusion-v1-4は
(1)stable-diffusion-v1-1
237k steps at resolution 256×256 on 「laion2B-en(約23.2億枚)」
194k steps at resolution 512×512 on 「laion-high-resolution(約1.7億枚)」
↓
(2)stable-diffusion-v1-2
v1-1に以下を追加
515k steps at 512×512 on 「laion-improved-aesthetics(おそらく6億よりは少ない)」
↓
(3)stable-diffusion-v1-4
v1-2に以下を追加
225k steps at 512×512 on 「laion-aesthetics v2 5+(約6億)」
なので、延べ36億枚程度の画像を使用して1,171,000ステップ学習していると思われます。
これほど、巨大なモデルであっても1,000以下の画像で15,000ステップでかなりいい感じに微調整出来るのですね。
また、Stable Diffusionを二次元イラストで微調整した事で人気の高いWaifu Diffusion 1.3は、Stable Diffusion 1.4を68万画像で微調整した結果で8 x 48GB A40 GPUsで10日間、約$3,100ドル(約45万円)かかっているそうです。
Waifu Diffusionは試行錯誤も加えるとおそらく200万円以上はかかっていそうで凄い情熱を感じますが、これは世界トップレベルのプロジェクトだと思います。
3.Stable Diffusionを微調整するために必要な条件の調査関連リンク
1)github.com
examples / stable-diffusion-finetuning (Fine Tune Stable Diffusion)
salesforce / BLIP
diffusers/examples/text_to_image (Stable Diffusion text-to-image fine-tuning)
microsoft / DeepSpeed
2)huggingface.co
lambdalabs/pokemon-blip-captions
3)gist.github.com
Waifu Diffusion 1.3 Release Notes

