
1.DreamBooth:Stable Diffusionに自分の好きなキャラクターを描いてもらう事は可能まとめ
・DreamBoothは少数の画像から新しい概念をタグとして学ばせる事が可能
・textual inversionと同等だが全体を最適化するためにより強力でメモリ喰い
・DreamBoothの省メモリ実装は推論だけなら6GB程度のメモリで動作可能
2.DreamBoothとは?
アイキャッチ画像はstable diffusionのDreamBoothによる生成で8K版の風の谷のナウシカと肩にポケモンをのせた風の谷のナウシカ。
風の谷のナウシカは生成が難しいキャラクターの一つです。厳密にはスタジオジブリ作品ではない、ギリシャ神話の登場人物や現実に存在する地名等と名称がかぶるケースがある、インターネットがなかった時代の作品なので最近の作品に比べると英語圏での知名度が低い、等々が原因として推測されます。
2023年9月追記)DreamBoothというキーワード検索するとやや古いこのページがGoogle検索上位に来てしまうようなので追記します。
本ブログでたどったDreamBoothの進化の歴史は以下です。
・DreamBoothで鬼滅の刃の蟲柱の服をナウシカに着てもらう事は可能か?
・DreamBoothで鬼滅の刃の隊服をナウシカに着てもらう事は妥協すれば可能
・DreamBoothで鬼滅の刃の隊服をナウシカに着てもらう事は可能
DreamBoothは初期に発表されたstable diffusionをカスタマイズする手法で注目を集めましたが、直近は後発技術であるLoRAの方が広く使われるようになっています。理由の1つはファイルサイズです。DreamBoothは元にしたモデルそのものを改変するのでサイズが2~5GBくらいになりますが、LoRAは数キロバイト程度の別ファイルとして保存でき、更に系統が似た他のモデルにも適用できるため、使い勝手が良いのです。
例えば、Waifu Diffusion 1.5 Beta 3というモデルは基本となるベースモデルに加えて4つの派生モデルが公開されました。DreamBoothを全部で試したい場合、全5モデルを対象にして5回微調整を行い、5つのモデル(全25GB)を作る必要がありますが、LoRAの場合は基本モデルを対象に一回微調整して1つの数キロバイトファイルを作成するだけで済みます。実例は以下です。
Waifu Diffusion 1.5 Beta 3を使ってLoRAとReference-only ControlNetを比較
その他、拡張機能を使った細かい制御手法なども発表されておりLoRAは使い勝手が非常に良くなってきているため、今から微調整をやってみたいと考えている方は先にLoRAを試してみる事をお勧めします。拡張機能とLoRAを使った事例は以下です。
2023年6月時点の技術でイラスト生成AIで二次元キャラクターのコスプレ画像を作成する
余談ですがLoRAはネガティブプロンプトの中で使う事が出来ないので、それがDreamBoothと同時期に発表されたtextual inversion(Embedding)がまだ広く使われている理由です。
文章による指示を元に画像を生成してくれる事で有名な人工知能であるStable Diffusionですが、漠然とした指示で何となく良い感じの絵を生成するのは比較的容易です。
しかし、特定のキャラクターを含めた絵を生成したくなった場合、思った通りに生成できるキャラクターと、色々とプロンプトを試行錯誤してみても想定と異なる絵しかできないキャラクターがある事に気がつくと思います。
前者は例えば、海外の有名人など、つまり英語圏で有名なキャラクターです。後者は例えば、英語圏ではそれほど有名ではないキャラクターや、名称が一般的すぎて他と被ってしまうキャラクターなどです。
世間の人気や知名度などどうでも良くて、とにかく、自分が好きなキャラクターの絵を描いて欲しいんだ!と言う湧き上がる熱い思いを持っている方は後者の絵を描いてもらおうとして悪戦苦闘していると思うのですが、遂に後者パターンのキャラクターでもStable Diffusion先生に描いて貰う事ができるようになりました!と言うお知らせです。
DreamBoothは、元々Googleの非公開の画像生成モデルであるImagenを対象にした手法で、モデルに少数の画像を与えて新しい概念として学ばせる事ができます。そして、学ばせた概念をプロンプトの中で利用できるようになるのです。
つまり、先日紹介したtextual inversionとほぼ同じなので、より詳しく知りたい方はそちらも見ておくと良いと思いますが、textual inversionが単語のembeddingのみを最適化するのに対して、モデル全体を最適化するために、より強力です。
しかし、その代償として必要メモリも多く30GB超のメモリを搭載したGPUがなくては微調整させる事が出来ませんでした。パソコン本体ではなくGPUのメモリが30GB超です!つまり、個人向けGPUの最上位モデルである20万円以上するRTX 3090(24GB)でも動かせなかった程です。
しかし、AIコミュニティの先達の皆さんの不断の努力のおかげで、DreamBoothの実装をStable Diffusionで動くようにした人、またそのStable Diffusion実装をコツコツと改良し、必要メモリを減らした人達のおかげで、12.5GBあれば微調整できるようになったのが3日前だったと思います。
12.5GB!
私の使用している5万円くらいのRTX 3060の搭載メモリは12GB!
ぐぬぬぬぬぬ、後0.5GBで動かせるのに、何とかならないのか!と苦悩したのですが、良く考えると、微調整(トレーニング)に12.5GB必要だと言うのであるならば推論、つまり学習済モデルを実行するだけなら、12.5GBも使わないのではないかと思いつきました。
そのため、12.5GB版のColab(末尾にリンクあり。完全に動作する事を確認していますが、稀にダウンロードに失敗してエラーになるケースがあるので失敗したら悩まず再実行すると良いです)を公開してくれている人がいたので、
(1)無料版のColabでTesla T4(15GB)を引き当てて、タグとして学習して欲しい画像を3~5枚程与えてモデルを学習させる。Colabで割り当てられるGPUはランダムなのですが、何度もトライして頑張ってTesla T4を引いてください。また、Colab上でモデルを学習させるだけではなく、もちろん、そのまま引き続きイラストを生成して貰って楽しむ事もできます。
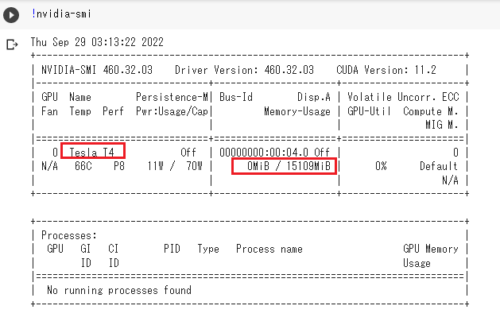
(2)学習したモデル(models配下)をダウンロードして自分のPC内で学習させたタグを使用したプロンプトで画像を生成
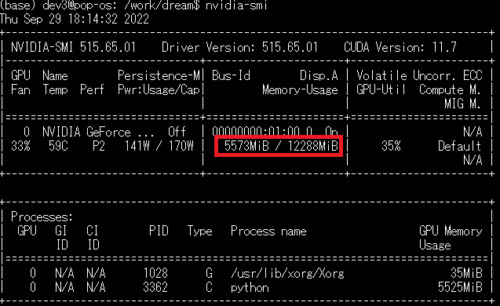
動いた!(ShivamShrirao版のdiffusersとhuggingface社アカウント登録が必要)
推論実行時は6GB弱程度しか使っていないため、4万円くらいのRTX 3050(8GB)、7万円くらいのRTX 3070(8GB)、10万円くらいのRTX 3080(10GB)でも同様なやり方でおそらく動かす事が可能と思います。
Colabだけで動かす事は可能ですが、大量に試行錯誤する場合はどうしても自宅PCで動かしたくなりますよね。
そして、実際に動かしてみたところ、まぁ、これは、うーん、ヤバイ奴ですね。やりたいと思った事がそんなに一生懸命チューニングしなくてもできちゃいます。自分が希望するキャラクターを比較的容易に人工知能に描いて貰う事が出来ちゃいます。
以下、今までのプロンプトエンジニアリングやパラメータチューニングに費やした時間は何だったんだろうと、ちょっと悲しくなって来るレベルの高品質なナウシカ画像をお楽しみください。















沢山、ナウシカの絵を描いて貰えて幸せな気持ちです。
なお、微妙にノイズが載ってしまっている絵などもあるので、Stable Diffusionで生成したナウシカのイラストの解像度を上げて綺麗にする試みも別記事でやっています。
また、好みのキャラクターを描いて貰って且つ服装などの一部の属性を変更して貰う試みもやっています。
Stable Diffusion2.0を使ったDreamBooth拡張のナウシカをアップしました。
3.DreamBooth:Stable Diffusionに自分の好きなキャラクターを描いてもらう事は可能関連リンク
1)dreambooth.github.io
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
2)github.com
XavierXiao / Dreambooth-Stable-Diffusion
ShivamShrirao / diffusers
3)colab.research.google.com
DreamBooth_Stable_Diffusion.ipynb (12.5 GB版Colab)

