
1.Dual Mirror Descent:どのタイミングでどのくらい売るのが最も儲かるかを予測する(1/2)まとめ
・デジタル化によりリアルタイムで意思決定を行う事が重要な市場が増えている
・限られた資源を効率的に割り当てるオンライン割り当て問題が重要になっている
・デュアルミラー降下法と呼ぶオンライン割り当て解法アルゴリズムを開発した
2.Dual Mirror Descentとは?
以下、ai.googleblog.comより「Robust Online Allocation with Dual Mirror Descent」の意訳です。元記事の投稿は2022年9月16日、Santiago BalseiroさんとVahab Mirrokniさんによる投稿です。
アイキャッチ画像はstable diffusionによる生成でバナナの叩き売りをするトトロ
デジタル技術の出現により、航空会社、オンライン小売業、インターネット広告などの商業セクター全体で意思決定が変化しました。現在、非常に不確実で急速に変化する環境では、リアルタイムの意思決定を繰り返し行う必要があります。
さらに、通常、組織の資源は限られているため、意思決定全体に効率的に割り当てる必要があります。このような問題は「資源の制約を伴うオンライン割り当て問題(online allocation problems with resource constraints)」と呼ばれ、適用業務がたくさんあります。いくつかの例は次のとおりです。
・予算制約のある入札
広告主は、検索エンジンや広告掲載枠取引市場など、オークション形式の市場で広告枠を購入することが多くなっています。一般的な広告主は、1ヶ月に数多くのオークションに参加することができます。このような市場では供給が不確定であるため、広告主は予算を設定して総出稿量をコントロールすることになります。そのため、広告主は総出稿量を抑えつつ、成約を最大化するために最適な入札方法を決定する必要があります。
・動的広告割当
出版元は、広告主とインプレッション数を保証する契約を結ぶか、自由市場で広告掲載枠をオークションにかけることで、ウェブサイトを収益化することができます。この選択をするために、出版元は、自由市場での掲載枠販売による短期的な収益と、予約広告に良質な枠を提供することによる長期的な利益を、リアルタイムでトレードオフする必要があります。
・航空会社の収益管理
飛行機の座席数には限りがあり、出発前に可能な限り座席を埋めておく必要があります。しかし、フライトの需要は時間とともに変化するため、航空会社は最もお金を払ってくれるお客さんに航空券を売りたいと考えています。そのため、航空会社は航空券の価格設定や販売状況を管理するために、高度な自動化システムを採用することが多くなっています。
・限られた在庫でパーソナライズする小売業
オンライン小売業者は、リアルタイムのデータを利用して、来店した顧客に合わせた商品を提供することができます。商品の在庫は限られており、簡単に補充できないため、小売業者は在庫の制約を満たしながら収益を最大化するために、どの商品をどの程度の価格で提供するかを動的に決定する必要があります。
これらの問題の共通点は、資源制約(上記の例ではそれぞれ予算、契約上の義務、座席、在庫)が存在し、不確実性のある環境下で動的な意思決定を行う必要があることです。例えば、入札問題では、早期に高すぎる入札をすると、広告主は予算がなくなり、後に機会を逃すことになります。逆に、入札を控えめにしすぎると、成約数やクリック数が少なくなる可能性があります。
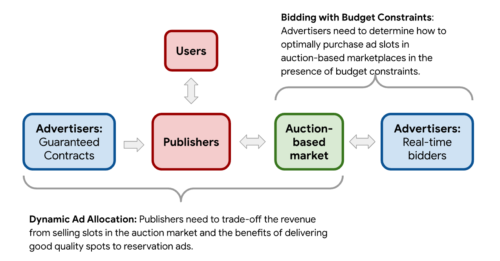
インターネット広告市場において、広告主と出版元が直面する2つの中心的な資源配分問題
この投稿では、動的で資源に制約のある環境において目標を最大化するのに役立つ、最先端のアルゴリズムについて説明します。
特に、私達は最近、デュアルミラー降下法(Dual Mirror Descent)と呼ばれるオンライン割り当て問題に対する新しいクラスのアルゴリズムを開発し、シンプルで堅牢かつ柔軟なアルゴリズムを実現しました。
私達の論文はOperations Research, ICML2020, ICML2021に掲載されており、この分野での進歩を続けるために現在も研究を続けています。
既存の手法と比較して、補助的な最適化問題を解く必要がないため高速であり、最小限の修正で異なる分野の多くのアプリケーションに対応できるため柔軟であり、異なる環境下で顕著な性能を発揮するため堅牢であることが特徴です。
オンライン割当問題
オンライン割り当て問題では、意思決定者は限られた総資源(B)を持ち、時間(T)にわたって一定数の要求を受けます。任意の時点(t)で、意思決定者は報酬関数(ft)と資源消費関数(bt)を受け取り、行動(xt)を起こします。報酬関数と資源消費関数は時間とともに変化する中で、資源制約の中で報酬の総和を最大化することが目的です。
もし全ての要求が事前に分かっていれば、資源制約の中で時間経過とともに報酬関数をいかに最大化するかというオフライン最適化問題を解くことで最適な割り当てを得ることができます。
オフラインでの最適配分は、将来の要求を知る必要があるため、実際には実行できません。しかし、このことは、将来の要求を知らなくても、できるだけ最適に近い性能を持つアルゴリズムを設計するという、オンライン割り当て問題の目標を構成するのに有効です。
3.Dual Mirror Descent:どのタイミングでどのくらい売るのが最も儲かるかを予測する(1/2)関連リンク
1)ai.googleblog.com
Robust Online Allocation with Dual Mirror Descent
2)arxiv.org
From Online Optimization to PID Controllers: Mirror Descent with Momentum

