
1.ディープラーニング比較用のベースラインを利用しやすくする(2/2)まとめ
・不確実性ベースラインでは、モデル、データセット、評価指標を選択可能
・各ベースラインのトレーニング/評価パイプラインはPythonファイルに含まれる
・ベースライン間の独立性があるため、TensorFlow、PyTorch、JAXのいずれでも開発可
2.Uncertainty Baselinesの内容
以下、ai.googleblog.comより「Baselines for Uncertainty and Robustness in Deep Learning」の意訳です。元記事は2021年10月14日、Zachary NadoさんとDustin Tranさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Michael Shannon on Unsplash
不確実性ベースライン(Uncertainty Baselines)では、ベースモデル、トレーニングデータセット、一連の評価指標を選択して各ベースラインを設定します。そして、それぞれのベースラインは、これらの評価指標における性能を最大化するようにハイパーパラメータを調整します。ベースラインの種類は、以下の3つの軸によって異なります。
・ベースモデル(アーキテクチャ)には、Wide ResNet 28-10、ResNet-50、BERT、および単純な完全結合ネットワークが含まれます。
・学習データセットには、標準的な機械学習データセット(CIFAR、ImageNet、UCI)や、より現実的な問題(Clinc Intent Detection、Kaggle’s Diabetic Retinopathy Detection、Wikipedia Toxicity)が含まれています。
・評価項目は、予測指標(精度など)、不確実性指標(選択的予測やキャリブレーションエラーなど)、計算指標(推論の待ち時間)、分布内データおよび分布外データセットでの性能などです。
モジュール化と再利用性
研究者がベースラインを使用して構築できるように、我々は意図的にベースラインを最適化し、可能な限りモジュール化して最小化しました。下のワークフロー図に見られるように、不確実性ベースラインは新しいクラスの抽象化を導入せず、代わりにエコシステムに既に存在するクラス(例えば、TensorFlowのtf.data.Dataset)を再利用している。各ベースラインのトレーニング/評価パイプラインは、その実験用のスタンドアロンPythonファイルに含まれており、CPU、GPU、またはGoogle Cloud TPU上で実行できます。
このようにベースライン間の独立性があるため、TensorFlow、PyTorch、JAXのいずれかでベースラインを開発することができます。
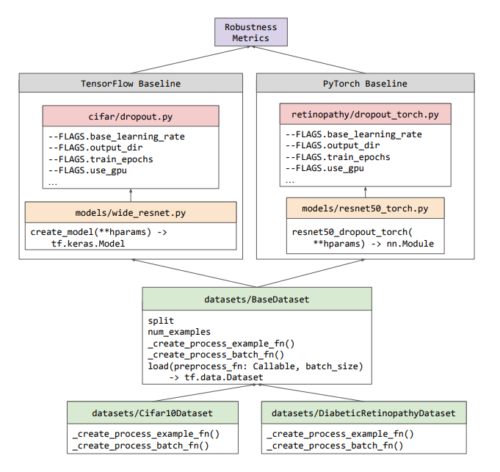
不確実性ベースラインの各部がどのように構成されているかを示すワークフロー
すべてのデータセットはBaseDatasetクラスのサブクラスで、サポートされているフレームワークで書かれたベースラインで使用するためのシンプルなAPIを提供しています。
どのベースラインからの出力も、Robustness Metricsライブラリを使って分析することができます。
研究エンジニアの間で議論されている分野の1つは、ハイパーパラメータやその他の実験設定値をどのように管理するかということがあります。その数は簡単に数十個にもなります。
管理を行うために作られた多数のフレームワークを使う事や、ユーザーが別のライブラリを学ばなければならないというリスクを冒す代わりに、私たちは単純にPythonに引数として設定値を渡す事にしました。
つまり、Googleの引数解析Pythonライブラリであるabseilで定義します。これは多くの研究者にとって馴染みのある手法であり、他のパイプラインへの拡張やプラグインも容易です。
再現性
文書化されたコマンドを使用して各ベースラインを実行し、同じレポート結果を取得できることに加えて、さらに再現性を高めるために、ハイパーパラメータの調整結果と最終モデルチェックポイントをリリースすることも目指しています。現時点では、糖尿病性網膜症(Diabetic Retinopathy)のベースラインのみが完全にオープンソース化されていますが、今後、さらに多くの結果をアップロードし続けます。さらに、ハードウェア構成まで正確に再現可能なベースラインの事例もです。
実務的な影響
リポジトリに含まれる各ベースラインは、広範なハイパーパラメータ調整を経ており、研究者が費用のかかる再トレーニングや再調整を必要とせずに、この作業を簡単に再利用できることを願っています。さらに、ベースラインの比較に影響を与えるパイプライン実装の小さな違いを回避したいと考えています。
不確実性ベースラインは、すでに多くの研究プロジェクトで使用されています。他の手法やデータセットで貢献したい研究者は、GitHubでissueを開いてディスカッションを開始してください。
謝辞
共同開発者であり、ガイダンスを提供し、および/またはこの投稿のレビューを支援してくれた多くの人々に感謝します。
Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jasper Snoek, Yarin Gal。
3.ディープラーニング比較用のベースラインを利用しやすくする(2/2)関連リンク
1)ai.googleblog.com
Baselines for Uncertainty and Robustness in Deep Learning
2)arxiv.org
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
3)abseil.io
abseil / Flags
4)github.com
google / uncertainty-baselines

