
1.画像の説明文を利用して視覚的質問回答データを作成(2/2)まとめ
・質問回答モデルと質問生成モデルの両方を使用して一貫性をチェックした
・既存データセットから生成したサンプルの66%~87%が妥当と評価された
・従来データに存在しなかった質問も存在する質問も生成できている
2.\(VQ^2A\)を使った学習
以下、ai.googleblog.comより「Rewriting Image Captions for Visual Question Answering Data Creation」の意訳です。元記事は2022年7月13日、Soravit Beer ChangpinyoさんとDoron Kuklianskyさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Hans-Jurgen Mager on Unsplash
質問回答モデルと質問生成モデルの両方を使用して、互いを往復して一貫性をチェックするというアイデアは、以前、他の文脈でも検討されています。例えば、\(Q^2\)はこのアイデアを用いて、知識に基づく対話における事実の一貫性を評価します。最終的に、VQ2Aアプローチは、以下に示すように、VQAの学習データとして十分に高品質な[画像、質問、回答]のトリプレットを大量に生成することができます。

\(VQ^2A\)は主に3つのステップから構成されます。(i)候補回答抽出、(ii)質問文生成、(iii)質問回答および回答の検証。
結果
人間が書いたCOCO Captionsと自動収集したCC3M Conceptual Captionsに基づいて生成されたVQAデータをそれぞれ、\(VQ^2A-COCO\)と\(VQ^2A-CC3M\)と呼んでいます。
VQAでは、問題の種類とスタイルが多様であることが重要です。全体として、説明文がクリーンなほど(つまり、ペアとなる画像との関連性が高いほど)、生成される[画像、質問、回答]のトリプレットの精度は高くなります。800のサンプルに基づき、\(VQ^2A-COCO\)の87.3%、\(VQ^2A-CC3M\)の66.0%が人間の評価者によって妥当であると認められました。私達のアプローチが高い精度で質問と回答のペアを生成できることを示唆しています。


COCO Captions(上)とConceptual Captions(下)に基づき生成された質問と答えのペア。灰色のハイライトはVQAv2に存在しない質問を、緑のハイライトは存在する質問を示しており、私達のアプローチが既存のVQAデータセットに存在しない新しい質問を生成できることを示しています。
最後に、生成したデータを用いてVQAモデルの学習を行い、評価を行いました。(下図参照)
その結果、自動生成されたVQAデータは、手動で注釈付けされたターゲットVQAデータに対して高い競争力を持つことが分かりました。まず、生成したデータのみで学習させた場合、VQAモデルはターゲットベンチマークで高い性能を発揮します。(薄い青色と薄い赤 vs 黄色の比較)。
その後、ターゲットデータで微調整を行ったところ、VQAv2やGQAなどの大規模ベンチマークではターゲットデータのみでの学習をわずかに上回り、小規模だが知識を必要とするOK-VQAでは大幅に上回りました。(青/赤 と 薄い青/薄い赤の比較)
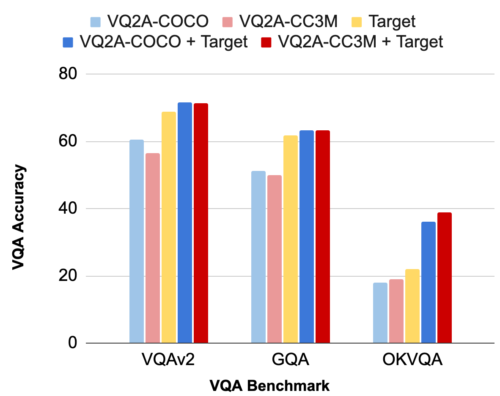
一般的なベンチマークデータセットにおけるVQAの精度
まとめ
VQAに必要なのは、画像の説明文だけかもしれません!本研究は、高品質なVQAデータを大規模に自動生成することが可能であることを示し、VQAおよび一般的な視覚-言語モデル(ALIGN、CoCaなど)にとって不可欠な構成要素となることを示しました。私たちは、この研究がデータ中心のVQAに関する他の研究の刺激となることを期待しています。
謝辞
Roee Aharoni, Idan Szpektor, Radu Soricutの各氏には、このブログ記事についてフィードバックをいただきました。また、共著者にも感謝します。Xi Chen、Nan Ding、Iadan Szpektor、Radu Soricutに感謝します。Or Honovich、Hagai Taitelbaum、Roee Aharoni、Sebastian Goodman、Piyush Sharma、Nassim Oufattole、Gal Elidan、Sasha Goldshtein、Avinatan Hassidimの貢献にも感謝します。最後に、彼らのパイプラインがこの作品に強い影響を与えている\(Q^2\)の作者に感謝します。
3.画像の説明文を利用して視覚的質問回答データを作成(2/2)関連リンク
1)ai.googleblog.com
Rewriting Image Captions for Visual Question Answering Data Creation
2)arxiv.org
All You May Need for VQA are Image Captions

