
1.MV-GPT:動画に説明文を自動で付与するための新手法(1/2)まとめ
・マルチモーダルビデオキャプションは動画に説明文(キャプション)を生成するタスク
・根拠に基づいてキャプションを生成する必要があり動画理解タスクより困難なタスク
・MV-GPTはラベル付けされていない動画像から学習する新手法で最先端のスコアを達成
2.MV-GPTとは?
以下、ai.googleblog.comより「End-to-end Generative Pre-training for Multimodal Video Captioning」の意訳です。元記事は2022年6月7日、Paul Hongsuck SeoさんとArsha Nagraniさんによる投稿です。
アイキャッチ画像のクレジットはDALL·E Miniでプロンプトは「Illustration of a cat happy to see the video and understand the content」
マルチモーダルビデオキャプションシステムは、ビデオフレームと音声の両方を利用して、ビデオに対して自然言語の説明文(キャプション)を生成します。
このようなシステムは、動画と音声などマルチモーダルな入力ストリームを通して環境を知覚しながら、ユーザーと楽々とコミュニケーションできるマルチモーダルな会話システムを構築するという長年の目標への足がかりとなるものです。
映像理解タスク(video understanding tasks、動画分類や動画検索など)や映像検索タスクではマルチモーダルな入力映像を処理し理解することが重要な課題となります。
しかし、マルチモーダルビデオキャプションタスクには、根拠に基づいてキャプションを生成するという追加の課題が含まれます。
この課題に対して最も広く採用されているアプローチは、手動で注釈付けしたデータを用いてエンコーダ・デコーダのネットワークを共同で学習することです。
しかし、大規模な人手による注釈付けデータがないため、ビデオに根拠となるキャプションをアノテーションするタスクは手間がかかり、多くの場合、現実的ではありません。
VideoBERTやCoMVTのような先行研究では、自動音声認識(ASR:Automatic Speech Recognition)を活用し、ラベル付けされていないビデオを使ってモデルを事前学習させます。しかし、このようなモデルはデコーダを持たないため、自然言語の文章を生成できないことが多く、そのため、ビデオエンコーダのみを下流のタスクに転移しています。
CVPR 2022で発表される論文「End-to-End Generative Pre-training for Multimodal Video Captioning」では、マルチモーダルビデオキャプションのための新しい事前学習フレームワークを紹介します。
このフレームワークは、マルチモーダルビデオ生成事前学習(MV-GPT:Multimodal Video Generative Pre-Training)と呼ばれ、ラベル付けされていない動画像からマルチモーダルビデオエンコーダと文章デコーダを共同で学習します。
MV-GPTは、未来の発話(Future Utterance)をターゲットテキストとして利用し、新しい双方向生成タスクを定式化する事でこれを実現します。
私達は、MV-GPTがマルチモーダルビデオキャプションに効果的に転移し、様々なベンチマークで最先端の結果を達成することを実証します。さらに、このマルチモーダルビデオエンコーダは、VideoQA、テキスト-ビデオ検索、行動認識(action recognition)など、複数のビデオ理解タスクに対して競争力を発揮しています。
追加のテキスト信号として未来の発話を使用
一般的に、マルチモーダルビデオキャプションの各トレーニングビデオクリップは、2つの異なるテキストと関連付けられます。
(1)マルチモーダル入力ストリームの一部として動画に配置される音声字幕
(2)ターゲットキャプション、これはしばしば手動で注釈付けされたものです。
エンコーダは字幕情報と映像コンテンツの融合を学習し、ターゲットキャプションは生成用デコーダのトレーニングに使用されます。しかし、ラベル付けされていないビデオの場合、各ビデオクリップはASRから得た字幕のみであり、手動で注釈付けされたターゲットキャプションはありません。
さらに、ターゲットキャプションの生成が簡単になってしまうため、エンコーダの入力とデコーダのターゲットに同じテキスト(ASRの字幕)を使用することはできません。
MV-GPTは、将来の発話を追加のテキスト信号として活用し、エンコーダとデコーダの共同事前学習を可能にすることで、この課題を回避しています。
しかし、入力内容に基づかない未来の発話を生成するモデルの学習は、理想的とは言えません。そこで私達は、入力とのつながりを強化するために、新しい双方向生成損失(bi-directional generation loss)を適用します。
双方向生成損失(bi-directional generation loss)
前方生成(forward generation)と後方生成(backward generation)を含む双方向生成損失を定式化することで、根拠のないテキスト生成の問題を緩和しています。
前方生成は、視覚的フレームとそれに対応する字幕を与えて将来の発話を生成し、モデルが視覚的コンテンツとそれに対応する字幕を融合する学習を可能にします。
後方生成は、視覚フレームと未来の発話を受け取り、ビデオクリップのより根拠のあるテキストを含む字幕を生成するためにモデルを学習させるものです。
MV-GPTの双方向生成損失により、エンコーダとデコーダは視覚に基づいたテキストを扱うように学習することができます。
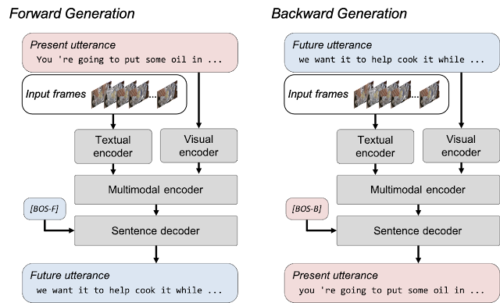
MV-GPTの双方向生成
モデルは2つの生成損失でトレーニングされます。前方生成では、モデルはフレームと現在の発話(赤いボックス)を指定して将来の発話(青いボックス)を生成しますが、現在の発話は後方生成の将来の発話から生成されます。2つの特別な文頭トークン([BOS-F]および[BOS-B])は、デコーダーの順方向および逆方向の生成を開始します。
3.MV-GPT:動画に説明文を自動で付与するための新手法(1/2)関連リンク
1)ai.googleblog.com
End-to-end Generative Pre-training for Multimodal Video Captioning
2)arxiv.org
End-to-end Generative Pretraining for Multimodal Video Captioning

