
1.30億のパラメータを持つ巨大モデルを学習させた際の知見まとめ
・非常に巨大なモデルを学習させる際は混合精度と全精度で違いが出る可能性がある
・通常の学習では問題は発生しないが学習の収束が見込めるトレーニングの後半に出る
・DALL·E megaのトレーニングは今後数日で終了しオープンソースで公開される予定
2.DALL·E megaのトレーニング中に起こった事
以下、TwitterよりBoris Dayma(@borisdayma)さんの2022年6月2日の投稿です。
最近OpenAIのDALL·E 2が生み出した画像が話題になっていますが、初代DALL·E(120億パラメータ)をオープンソースで再現しようという試みが幾つかあります。
その中で、工夫してパラメータ数を削減したDALL·E mini(4億パラメータ)の学習済モデルを公開してくれている方が、引き続きDALL·E Mega(30億パラメータ)を学習中に遭遇した挙動について投稿してくれていたので意訳しました。
アイキャッチ画像は初代DALL·Eが見事にイラスト化した事で有名になったフレーズ「犬の散歩をするバレリーナ用衣装を着た赤ちゃん大根(Baby daikon radish in a tutu walking a dog)」をDALL·E miniに画像化してもらった画像
DALLE-Megaのトレーニング中に犯した最大の失敗について話す時が来ました。
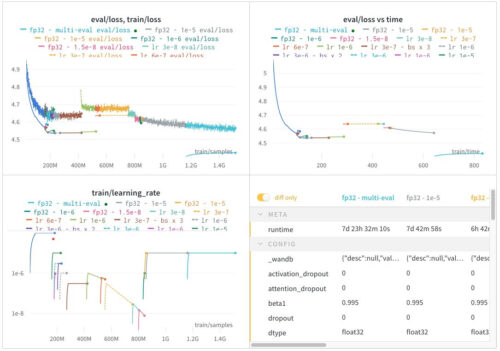
このモデルのトレーニングには、Google TRCプログラムから寛大に提供されたTPU Pods v3-256を使用しています。30億パラメータのモデルをトレーニングする際に、これほど素晴らしいリソースが手に入ることはそうそうないでしょう。
このモデルは過去にうまく規模を拡大する事ができなかったので、多くの改善(Shampoo, NormFormer, GLU, better init, etc)を行っていました。
さっと学習率に検討を付けた後、最初の数日間はトレーニングが非常に有望に思えました。
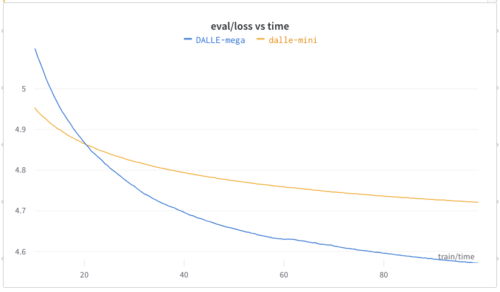
ある時点から、不安定さが目立つようになりました。大きな心配はしませんでした。ちょうど学習率を低下させる時期だったからです。
問題は、私が予想していたよりもずっと早く学習率を減少させる必要があった事です。
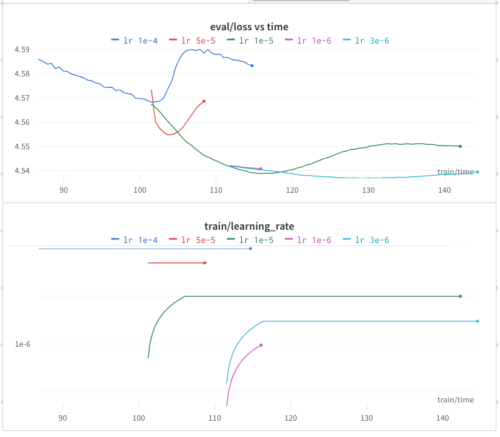
トレーニングを再開する際、私は小さなウォームアップをするのが好きです。なぜなら、それは何も損ないませんし、損失が「鋭いエッジ(sharp edges)」を避けるのに役立つ可能性があるからです。
うまくいかなかったので、勾配蓄積(gradient accumulation)を増やすようにしました。バッチサイズを大きくすると、学習率を下げるのと同じような効果が得られることが多いです。
これもすぐに限界が見えてきました。
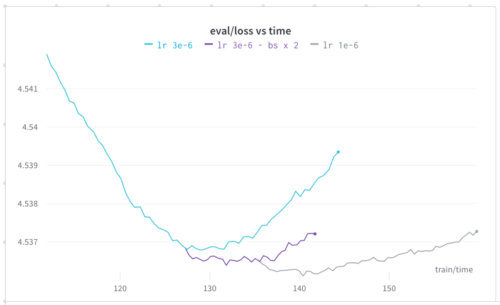
ドロップアウトも試しましたが、トレーニングのスピードが遅くなり、損失はまだ減りませんでした。そこで、LR decayを使って学習を終了させるようにしました。
驚いたのは、損失が大きくなってもサンプルの予測値が向上し続けたことです。
最終的には、検証セットのデータ分布が異なることが原因ではないかと思うようになりました。
・トレーニングセットには同じ画像(ただしキャプションは異なる)が含まれていることがある
・途中で学習データを追加した
この種のモデルでは、動的なデータセットがあってもいいのです。
私は時間を無駄にしたくないので、すべてのデータが揃う前に学習を開始しました。
モデルの学習が進むにつれて、学習データを調整する際にエラーを修正するようにしました。(テキストが含まれている画像を削除、透かし、サイズ調整)
そこで、検証セットをトレーニングシャード(training shard)に置き換えて、損失がどのような挙動を示すか確認することにしました。
検証セットを再利用するつもりはなかったので、トレーニングデータに追加してもいいかもしれないと思ったのです。
これが大きな間違いでした。
それに、とにかくデータが少なかった..。
損失は増え続けました。
私がドロップアウトを取り除くと、プラトー(plateau)に到達し、トレーニングの終了に至りました。
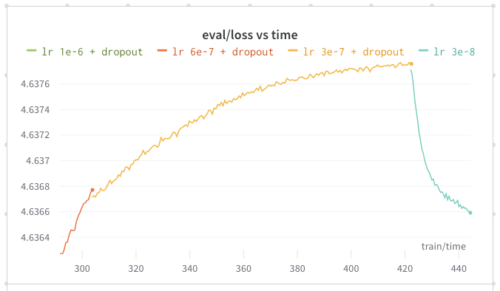
その時、Rohan Anil(@_arohan_)が全精度(full precision)で学習し、beta1 を更新することを提案しました。
その結果、検証損失がすぐに改善され、再び減少し始めました。
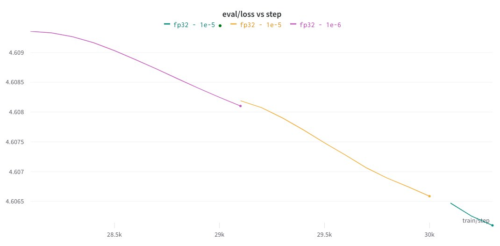
なぜ改善されたのか、まだよくわかりません。モデルは実際にうまく学習していたので、推論を全精度で行わなければならなかったのかもしれません。(VQGANでこの問題に気づきました)。
後日、さらに検証してみる予定です。
数日後、別の問題が気になりました。
検証データセットの損失は引き続き改善されましたが、検証セットには学習データにも含まれる画像が含まれるようになりました(ただし、キャプションは一意です)。
このモデルでは、キャプションはエンコーダーに、画像はデコーダーに供給されます。
もしかしたら、画像を記憶し、キャプションを無視していたのかもしれません。
今となってはこの理論を確認する術がありませんでした。
ユニークな画像で構成された最初の検証セットは、今やトレーニングデータの一部になってしまいました…
ユニークな画像で構成された新しいデータセットを集めるしかないのですが、かなり時間がかかり、現在トレーニングは終了間近です。
私が行うべきことは、複数の検証セットを許可することでした。
これは現在実装されており、起こっていることは理にかなっています。
・トレーニングデータには画像が含まれているため、トレーニングシャードが下がる(キャプションが一意であっても)
・最初の検証用シャードは、モデルがそれを忘れているため、上昇する。
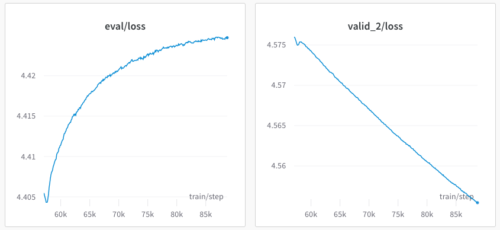
このモデルは現在、サンプルの予測値を手動で検査する以外にはチェックせずに学習しています。
まだ、(本家のDALL Eのように)チュチュを着て犬を連れて歩く赤ちゃん大根は描けませんが、改善されてきているので希望は捨てずにいます。
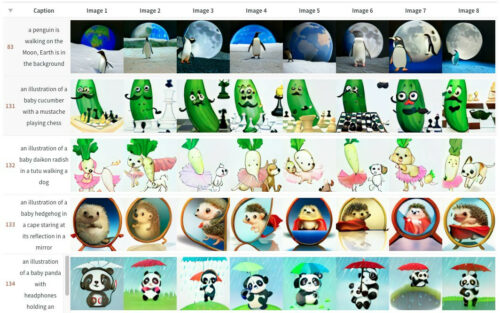
私は今後数日でトレーニングを終了することを期待しています。
トレーニングジャーナルでトレーニングの経過を追い、現在の予測を確認できます。
幾つかのQA
Q1.もう少し詳しく教えてください。かなり意外です。一般的には、混合精度で学習すれば混合精度での推論はあまり影響しないはずだと考えられていると思ったのですが…..
A1.モデルがかなりディープで誤差が蓄積されるからかもしれませんね。bfloat16でのevalとfloat32でのevalの差が出始めるのは、トレーニングの後半になってからです。
Q2.すでにお考えかもしれませんが、これは二重降下現象(double descent phenomenon)かも?あるいは補間現象(interpolation phenomenon)?全精密(full precision)にすれば修正できるかも?
A2.他のケースでは全精度とモーメンタム(momentum)の違いは起きなかったのでよくわからないのです。
3.30億のパラメータを持つ巨大モデルを学習させた際の知見関連リンク
1)twitter.com
@borisdayma
2)github.com
borisdayma / dalle-mini
3)wandb.ai
DALL·E Mega – Training

