
1.CoVeR:画像と動画で協調学習を行い行動認識を改善(1/2)まとめ
・行動認識は応用範囲が広いので研究コミュニティの注目を集める分野となっている
・行動認識モデルを別の異種データセットで調整するとパフォーマンスが低下する
・画像と映像を同時に活用し単一の汎用行動認識モデルを学習するCoVeRを提案
2.CoVeRとは?
以下、ai.googleblog.comより「Co-training Transformer with Videos and Images Improves Action Recognition」の意訳です。元記事は2022年3月1日、Bowen ZhangさんとJiahui Yuさんによる投稿です。
CoVeRしているマルチヘッドアーキテクチャを意識したアイキャッチ画像のクレジットはPhoto by Sam Manns on Unsplash
行動認識(Action recognition)は研究コミュニティにとって主要な注目分野となっています。これにより、動画検索(video retrieval)、動画への字幕付け(video captioning)、動画を使った質問回答(video question-answering)など、多くのアプリケーションが恩恵を受けるためです。
最近、Transformerベースのアプローチはいくつかのベンチマークで最先端の性能を実証しました。Transformerモデルは畳み込みモデル(ConvNets)と比較して、より良い視覚的な事前分布を学習する事ができますが沢山のデータを必要とします。
しかし、行動認識用のデータセットは比較的小規模です。大規模なTransformerモデルは、通常、最初に巨大な画像データセットで学習をし、その後、目的とする行動認識用データセットで微調整されます。
現在の行動認識における事前学習と微調整のパラダイムは、直接的であり、強力な経験的結果を示していますが、汎用の行動認識モデルを構築するには、過度に制限される可能性があります。
ImageNetのような広範な物体認識クラスをカバーするデータセットに比べ、KineticsやSSv2(Something-Something-v2)のような行動認識データセットは限られたトピックに関連するものです。
例えば、Kineticsには「崖から水に飛び込む(cliff diving)」や「氷の崖を登攀(ice climbing)」のような物体中心の動作が含まれ、SSv2には「何かを何かの上に置く素振り」のような物体にとらわれない動作が含まれています。
その結果、あるデータセットで微調整された行動認識モデルを、別の異種データセットで調整すると、パフォーマンスが低下することが確認されました。
また、データセット間の物体や背景映像の違いは、汎用的な行動認識分類モデルの学習をさらに困難なものにしています。ビデオデータセットのサイズが大きくなっている可能性があるにもかかわらず、先行研究は、強力なパフォーマンスを達成するためには、データの大幅な増強と正則化が必要であることを示唆しています。この後者の発見は、モデルが目標のデータセットにすぐに過剰適応し、その結果、他の行動認識タスクに汎化する能力が妨げられていることを示している可能性があります。
論文「Co-training Transformer with Videos and Images Improves Action Recognition」では、画像と映像の両データを共同で活用し、単一の汎用的な行動認識モデルを学習するCoVeRと名付けた学習方法を提案します。
このアプローチは、2つの主要な発見によって支えられています。
第一に、異種のビデオデータセットは多様な活動をカバーしており、単一のモデルでそれらを一緒に学習することにより、幅広い活動に秀でたモデルを導き出すことができます。
第二に、動画は運動情報を学習するのに最適なソースであり、画像は構造的な外観を利用するのに適しています。
多様な画像サンプルを活用することで、動画モデルにおいて堅牢な空間的特徴表現を構築することができるかもしれません。具体的には、CoVeRはまず画像データセットでモデルを事前学習し、微調整の際に、複数のビデオと画像データセットを使って一つのモデルを同時に学習させ、汎用のビデオ理解モデルのための堅牢な空間的および時間的特徴表現を構築します。
モデルの設計と学習戦略
最近提案されたTimeSFormerと呼ばれる24層のTransformerブロックを持つ空間的-時間的動画Transformerに対してCoVeRアプローチを適用しました。
各ブロックは、1つの時間的Attention、1つの空間的Attention、1つの多層パーセプトロン(MLP:Multilayer Perceptron)層を含みます。
複数のビデオと画像データセットから学習するために、マルチタスク学習パラダイムを採用し、行動認識モデルにを装着します。
大規模な画像データセットであるJFTデータセットを用いて、全ての非時間的パラメータを事前学習します。微調整の際には、複数の動画・画像データセットから動画・画像を一括してサンプリングします。サンプリングレートはデータセットのサイズに比例します。バッチ内の各サンプルはTimeSFormerによって処理された後、対応する分類器に分配され、予測が得られます。
標準的な学習戦略と比較して、CoVeRには2つの利点があります。
まず、モデルは複数のデータセットから直接学習するため、学習されたビデオ特徴表現はより汎用的であり、追加の微調整をすることなく、それらのデータセットで直接評価することができます。
第二に、Transformerベースのモデルは、より小さい動画の分布に容易に過剰適合する可能性があるため、学習された特徴表現の汎化性が低下することです。複数のデータセットで学習を行うことで、過剰適合のリスクを低減し、この課題を軽減することができます。
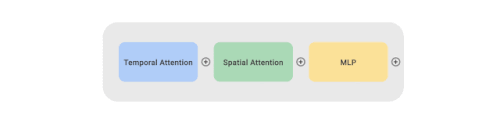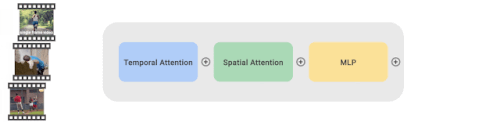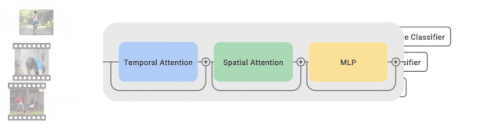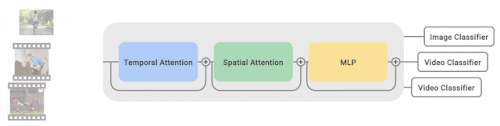
CoVeRは、複数のデータセットに対して、それぞれ独自の分類器を用いて学習するマルチタスク学習方式を採用しています。
3.CoVeR:画像と動画で協調学習を行い行動認識を改善(1/2)関連リンク
1)ai.googleblog.com
Co-training Transformer with Videos and Images Improves Action Recognition
2)arxiv.org
Co-training Transformer with Videos and Images Improves Action Recognition

