
1.CoCa:様々な視覚タスクのバックボーンとして利用できる基盤モデル(1/2)まとめ
・機械学習モデルは幅広いタスクに対応可能な大規模基盤モデルを元に設計する事が多い
・自然言語処理では、BERT、T5、GPT-3などの事前学習済大規模モデルが基盤となる事が多い
・視覚タスクでは幅広いタスクに使える基盤モデルがなかったので新手法でCoCaを設計した
2.CoCaとは?
以下、ai.googleblog.comより「Image-Text Pre-training with Contrastive Captioners」の意訳です。元記事は2022年5月24日、Zirui WangさんとJiahui Yuさんによる投稿です。
アイキャッチ画像はDALL·E Miniに「CoCa: Contrastive Captioners are Image-Text Foundation Models」を与えて作ってもらった画像。論文等の画像から引っ張ってきた図っぽいですね。
機械学習(ML:Machine Learning)モデルの開発者は、多くの場合、下流の幅広いタスクに転用可能な能力を持つ、大規模なバックボーンモデル(backbone model、「基盤モデル(foundation models)」と呼ばれる事もあります)を使用して設計を開始します。
自然言語処理では、BERT、T5、GPT-3など、多くの汎用的な基盤モデルが従来になかった規模の巨大データで事前学習し、ゼロショット学習、少数ショット学習、転移学習によって汎用的なマルチタスキング能力を実証しています。
特化しすぎた個別モデルの学習と比較して、多数の下流タスクのために基幹モデルを事前学習する事は学習コストを償却でき、大規模モデル構築時のリソース制限を克服することが可能です。
コンピュータビジョンでは、画像分類のために事前学習したシングルエンコーダーモデルが、他の下流タスクに有効な汎用的な視覚表現を捉えることができることを示した先駆的な研究があります。
最近では、インターネットから収集したノイズの多い画像とテキストのペアを用いて訓練した対照的なデュアルエンコーダ手法(CLIP、ALIGN、Florence)および生成的なエンコーダ・デコーダ手法(SimVLM)が研究されています。
デュアルエンコーダーモデルは、ゼロショット画像分類に顕著な能力を示しますが、視覚と言語の共同理解にはあまり効果的ではありません。一方、エンコーダ・デコーダモデルは、画像キャプションや視覚的質問応答には適していますが、検索スタイルのタスクを実行することはできません。
論文「CoCa: Contrastive Captioners are Image-Text Foundation Models」では、「対照的な字幕入力者(CoCa:Contrastive Captioner)」と呼ばれる統一的な視覚用バックボーンモデルを紹介します。
本モデルは、新しいエンコーダ・デコーダ手法です。画像とユニモーダルなテキストのembeddingsと、マルチモーダルな特徴表現の結合を同時に生成するアプローチであり、あらゆる種類の下流タスクに直接適用できる柔軟性を備えています。
具体的には、CoCaは視覚認識、クロスモーダルアライメント(画像に関連するテキストを選ぶ事など)、マルチモーダル理解といった一連の視覚・視覚言語タスクにおいて、最先端の結果を達成しています。更に、高度に汎用的な特徴表現を学習するため、ゼロショット学習や凍結エンコーダによる完全な微調整モデルと同等以上の性能を発揮することができます。
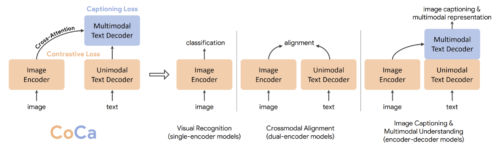
シングルエンコーダー、デュアルエンコーダー、エンコーダーデコーダーモデルと比較したCoCaの概要
具体的な手法
CoCaは、対照的な損失(contrastive loss)とキャプション損失(captioning loss)を組み合わせた統合トレーニングフレームワークです。
画像の注釈とノイズの多い画像-テキストのペアで構成される単一のトレーニングデータを使い、シングルエンコーダ、デュアルエンコーダ、およびエンコーダ-デコーダパラダイムを効果的に組み合わせます。
この目的のために、私達はエンコーダがVision Transformer(ViT)であり、テキストデコーダtransformer がユニモーダルテキストデコーダとマルチモーダルテキストデコーダの2つの部分に分離されている、新しいエンコーダ・デコーダのアーキテクチャを提示します。
ユニモーダルデコーダ層でクロスアテンションを省略し、テキストのみの特徴表現を符号化し、対照的な損失とします。
キャプション損失に対しては、マルチモーダルデコーダ層を画像エンコーダ出力へのクロスアテンションでカスケードしてマルチモーダル画像テキスト表現を学習させます。
この設計により、モデルの柔軟性と汎用性を最大限に高め、同時に、両方の学習目的に対して単一の順伝播と逆伝播で効率的に学習することができ、計算オーバーヘッドを最小にすることができます。その結果、ナイーブエンコーダ・デコーダモデルと同程度の学習コストで、ゼロから直接学習することが可能となりました。

対照的な損失とキャプションの損失の両方にCoCaが使用する順方向伝搬の図
3.CoCa:様々な視覚タスクのバックボーンとして利用できる基盤モデル(1/2)関連リンク
1)ai.googleblog.com
Image-Text Pre-training with Contrastive Captioners
2)arxiv.org
CoCa: Contrastive Captioners are Image-Text Foundation Models

