
1.脚式ロボットが学習時に転倒して破損しないようにする(1/3)まとめ
・脚式ロボットはは本質的に不安定であり学習中にロボットが転倒し破損する可能性がある
・仮想空間で学習させる事もできるが現実世界に転移学習する際に微妙な違いが問題を引き起こす
・実世界で学習中にロボットが転倒せずに運動能力を学習できるようになる事を目指した
2.脚式ロボットを安全に学習させる
以下、ai.googleblog.comより「Learning Locomotion Skills Safely in the Real World」の意訳です。元記事は2022年5月5日、Jimmy (Tsung-Yen) Yangさんによる投稿です。
Locomotionも久しぶりに出てきた概念ですね。
アイキャッチ画像のクレジットはPhoto by Ana Dujmovic on Unsplash
複雑で高次元な問題を自律的に解決する深層強化学習(RL:Reinforcement Learning)の有望性は、ロボット工学、ゲームプレイ、自動運転車などの分野で多くの関心を集めています。
しかし、RLポリシーを効果的に学習させるには、ロボットにとって安全でないものを多く含む、様々なロボットの状態や行動を広く収集する必要があります。例えば、脚式ロボットを訓練する場合、これはかなりのリスクです。このようなロボットは本質的に不安定であるため、学習中にロボットが転倒し、破損する可能性が高いのです。
コンピュータシミュレーションで制御ポリシーを学習し、それを実世界に展開することで、破損のリスクをある程度軽減することができます。しかし、このアプローチでは、通常、解決が困難なsim-to-realギャップに対処する必要があります。
すなわち、物理環境に展開した際にセンサーのノイズや訓練環境シミュレータが十分に現実環境をシミュレーションできていないなどの様々な理由により、シミュレーションで学習したポリシーを実世界に容易に展開することができない、という問題です。
sim-to-realギャップを解決するもう一つのアプローチは、実世界で制御ポリシーを直接学習したり微調整したりすることです。しかし、ここでも学習時の安全性を確保することが大きな課題となっています。
論文「Safe Reinforcement Learning for Legged Locomotion」では、訓練中に安全制約を満たしながら脚式移動(legged locomotion)を学習するための安全なRLフレームワークを紹介します。
私達の目標は、実世界において、学習中にロボットが転倒することなく、自律的に運動能力を学習することです。
本学習フレームワークは、安全でない状態に近いロボットを回復させる「安全回復ポリシー(safe recovery policy)」と、目的の制御タスクを実行するために最適化された「学習者ポリシー(learner policy)」の2つのポリシーを採用した安全RLフレームワークです。安全学習フレームワークは、安全回復ポリシーと学習者ポリシーを切り替えることで、ロボットが安全に新規かつ俊敏な運動技能を獲得することを可能にします。
提案するフレームワーク
私達の目標は、学習プロセス全体において、使用される学習者ポリシーに関係なく、ロボットが決して転倒しないことを保証することです。
子供が自転車の乗り方を学ぶのと同様に、我々のアプローチは「補助輪」を使いながらエージェントにポリシーを教えます、つまり、安全回復ポリシーを教えます。
私達はまず、ロボットが安全制約に違反しそうであるが、安全な回復ポリシーによってまだ救われる、「安全トリガーセット(safety trigger set)」と呼ぶ状態のセットを定義します。
例をあげると、安全トリガーセットとは「ロボットの高さがある閾値以下である事、揺れ、傾き、回転の角度が大きすぎる事」など、転倒の兆候を示す状態のセットとして定義することができます。
学習者ポリシーに従った結果、ロボットが安全トリガーセット内にいる(つまり、転ぶ可能性がある)場合、安全回復ポリシーに切り替え、ロボットを安全な状態まで駆動させます。
学習者ポリシーに戻るタイミングは、ロボットの近似ダイナミクスモデルを活用して将来のロボットの軌道を予測することで決定します。
例えば、ロボットの脚の位置と、揺れ、傾き、回転のセンサーに基づくロボットの現在の角度から、将来転倒する可能性があるかどうか?を予測します。
予測した未来の状態がすべて安全であれば、学習者ポリシーに制御を戻し、そうでなければ、安全回復ポリシーを使い続けます。
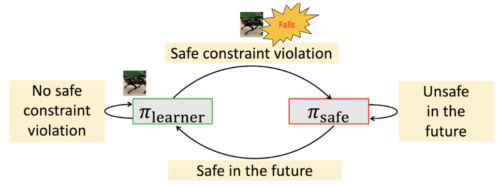
提案する手法の状態図
(1)学習者ポリシーが安全制約を破った場合、安全回復ポリシーに切り替えます
(2)安全回復ポリシーに切り替えた後、学習者ポリシーが近い将来の安全性を確保できなくなっていれば、安全回復ポリシーを使い続けます。これにより、ロボットは安全性を確保しながら、より多くの探索を行うことができます。
このアプローチでは、アプリケーション内の分布シフトに敏感な不透明なニューラルネットワークに頼ることなく、複雑なシステムでも安全性を確保することができます。また、学習者ポリシーは安全違反に近い状態を探索することができ、堅牢なポリシーを学習するのに有効です。
また、将来の軌道を予測するために「近似」されたダイナミクスを使用しているため、ロボットのダイナミクスにもっと正確なモデルを使用した場合に、どれだけ安全性が高まるかを検証しています。私達はこの問題の理論的解析を行い、私達のアプローチがシステムのダイナミクスを完全に知っているものと比較して、安全性能の損失を最小限に抑えることができることを示します。
3.脚式ロボットが学習時に転倒して破損しないようにする(1/3)関連リンク
1)ai.googleblog.com
Learning Locomotion Skills Safely in the Real World
2)arxiv.org
Safe Reinforcement Learning for Legged Locomotion

