
1.VDTTS:視覚駆動型の音声合成モデル(1/2)まとめ
・ノイズの多い環境で録音されたオリジナルの音声をスタジオで再録音し品質を高める時がある
・新たに録音した音声と映像の同期を取る必要がありこの作業は難しく、面倒な作業となる
・VDTTSは文章と話者のビデオフレームを与えると映像にマッチした韻律を持つ音声を生成可能
2.VDTTSとは?
以下、ai.googleblog.comより「VDTTS: Visually-Driven Text-To-Speech」の意訳です。元記事は2022年4月7日、Tal RemezさんとMicheal Hassidさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Brian Lundquist on Unsplash
近年、世界中のユーザーに対して、様々な言語と数多くのプラットフォームで動画コンテンツを作成し、提供することが非常に増えています。高品質なコンテンツの制作には、ビデオキャプチャ、キャプション、ビデオやオーディオの編集など、いくつかの段階を経て行われることがあります。
また、ノイズの多い環境で録音されたオリジナルの音声をスタジオで再録音し、品質を高める場合もあります。(対話の置き換え(dialog replacement)、ポストシンク(post-sync)、ダビング(dubbing)とも呼ばれます)
しかし、対話の置き換えは、新たに録音した音声と映像の同期を取る必要があり、口の動きのタイミングを合わせるために何度も編集する必要があるため、難しく、面倒な作業となる場合があります。
論文「More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech」では、では、VDTTS(Visually-Driven Prosody for Text-to-Speech) と呼ばれる概念実証の視覚駆動型音声合成モデルを紹介し、対話の置き換え処理を自動化します。
VDTTSは、テキストと話し手が映っているビデオフレームが与えられると、対応する音声を生成するように訓練されます。一般的な視覚的音声認識モデルは口元に注目しますが、VDTTSではMediaPipeを用いて顔全体を検出・切り出し、話し手の特徴表現に関連する情報を排除する可能性がないようにしています。
これにより、VDTTSモデルは映像にマッチした音声を生成するのに十分な情報を得るとともに、タイミングや感情などの韻律を回復することができます。入力映像に同期した音声を生成するように明示的に訓練されていないにもかかわらず、学習されたモデルは同期した音声を生成しています。
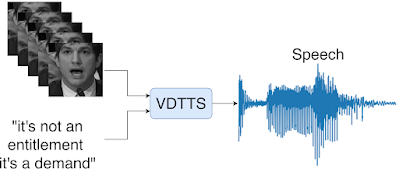
VDTTSは、テキストと話者のビデオフレームを与えると、ビデオ信号にマッチした韻律を持つ音声を生成します。
VDTTSモデル
VDTTSモデルは、Tacotronを核とし、4つの主要なコンポーネントから構成されています。
(1)入力を処理するテキストとビデオのエンコーダ
(2)エンコーダをデコーダに接続するマルチソースattention機構
(3)(VoiceFilterと同様に)話者embeddingを取り入れ、メルスペクトログラム(周波数領域での圧縮表現の一形態)を生成するスペクトログラムデコーダ
(4)メルスペクトログラムから波形を生成する事前訓練済みニューラルボコーダ(凍結済)
です。
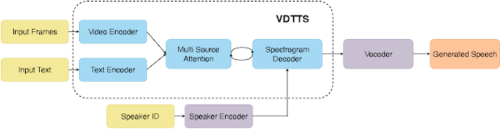
VDTTSの全体構成
テキストとビデオのエンコーダが入力を処理し、マルチソースattention機構がメルスペクトログラムを生成するデコーダに接続します。そしてボコーダがメルスペクトログラムから波形を生成し、音声を出力します。
VDTTSは、LSVSR(Large-Scale Visual Speech Recognition)データセットのビデオとテキストのペアを用いて学習します。テキストは、ビデオの中で人が話した正確な言葉に対応します。テストを通じて、VDTTSは任意のテキストを生成する事はできないため、悪用(フェイクコンテンツの生成など)されにくいと判断しています。
3.VDTTS:視覚駆動型の音声合成モデル(1/2)関連リンク
1)ai.googleblog.com
VDTTS: Visually-Driven Text-To-Speech
2)arxiv.org
More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech
3)google-research.github.io
More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech

