
1.Soft Prompt:プロンプトを人力でなく学習させる新手法(1/2)まとめ
・モデルの規模が大きくなるとタスク毎に複数のモデルを微調整して保存することは難しくなる
・GPT-3は1つの巨大モデルでも入力を工夫すれば多様なタスクを実行可能な事を示した
・入力(プロンプト)を設計するのは手作業が必要で微調整に比べると性能が劣る問題があった
2.soft promptとは?
以下、ai.googleblog.comより「Guiding Frozen Language Models with Learned Soft Prompts」の意訳です。元記事は2022年2月10日、Brian LesterさんとNoah Constantさんによる投稿です。
大規模言語モデルは次に出現する単語を予測する能力を持つので、入力文章を上手に調整する事で、感情分類等のやらせたいタスクを実行させる事ができ、この与える入力文の事をプロンプトといいます。
人工知能が人間の仕事を奪うなんて幻想だ、プロンプトチューニングという新しい仕事も生まれてきたじゃないかという真剣とも冗談ともとれる意見を見た事があるのですが、今回のソフトプロンプトの話は、早速、人間より機械の方が上手に仕事をこなせるようになったという事で、あまりの進化の速さに久々に微妙な気持ちになりました。
プロンプトと聞くとどうしてもコマンドラインプロンプトを思い起こしますが、それは英語圏でも共通なのだなと確認できたpromptで検索して出てきたアイキャッチ画像のクレジットはPhoto by Gabriel Heinzer on Unsplash
大規模化が進む事前学習済み言語モデルは、多くの自然言語処理(NLP:Natural Language Processing)ベンチマークで最先端の結果を達成しています。GPTやBERTの開発以来、標準的な手法として、下流のタスクでモデルを微調整することが行われており、これにはネットワーク内のすべての重みの調整(すなわちモデルのチューニング)が含まれます。
しかし、モデルの規模が大きくなると、下流タスクごとに調整したモデルのコピーを保存して提供することは現実的ではなくなります。代わりに、重みを固定した1つの学習済み言語モデルを全てのタスクで共有することができます。
このアプローチでは、ユーザはプロンプト(prompt)をデザインすることによって、与えられたタスクのをモデルに教え込む事ができます。例えば、感情分類用にモデルを条件付けるには、「この映画は素晴らしい!(This movie was amazing!)」という入力文字列の前に「この映画レビューは肯定的評価ですか?否定的評価ですか?(Is the following movie review positive or negative?)」というプロンプトを付けることで感情分類を行うようにモデルに促す事ができます。
タスク間で同じ凍結モデルを共有することで、下流タスクをサービスとして提供する事を大幅に簡素化し、効率的な混合タスク推論を可能にしますが、残念ながら、これはタスクのパフォーマンスを犠牲にしています。
テキストプロンプトは設計に手作業が必要で、うまく設計されたプロンプトでも、モデルチューニングに比べればはるかに性能が劣ります。例えば、SuperGLUE ベンチマークで GPT-3 1750億パラメータの凍結モデルの性能は、800倍少ないパラメータを使用するT5モデルの微調整済モデルより5ポイント低くなっています。
EMNLP 2021で発表した論文「The Power of Scale for Parameter-Efficient Prompt Tuning」ではプロンプトのチューニング手法について探求しています。
論文では凍結モデルをより効率的かつ効果的に調整するためにソフトプロンプト(soft prompt)を用います。
エンジニアが手動作成する従来のテキストプロンプトと同様に、ソフトプロンプトは入力テキストに与えられますが、調整が可能です。
既存の語彙群から選択するのではなく、ソフトプロンプトの「トークン」は学習可能なベクトルなのです。つまり、ソフトプロンプトは学習データセットに対して直接最適化することができます。
手動で設計する必要がなくなるだけでなく、何千、何百万もの例を含むデータセットから情報を凝縮してプロンプトを作成することが可能になります。これに対し、従来の個別に設定するテキストプロンプトは、モデル入力の長さに制約があるため、通常50サンプル以下に制限されています。また、私たちの実験を完全に再現するためのコードとチェックポイントを公開することができ、大変うれしく思っています。
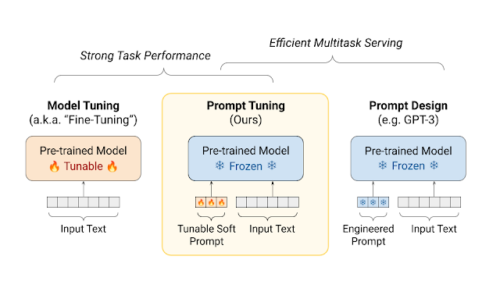
プロンプトチューニングは、モデルチューニングの強力なタスク性能を維持しつつ、事前に学習したモデルを凍結させることで、効率的なマルチタスク処理を可能にします。
プロンプトのチューニング
与えられたタスク用のソフトプロンプトを作成するために、まずプロンプトを固定長のベクトルの列(例えば20トークン長)として初期化します。
これらのベクトルを各embeddeing入力の先頭に付加し、結合した結果をモデルに入力として送り込みます。モデルの予測はターゲットと比較されて損失が計算されます。誤差は誤差逆伝搬されて勾配が計算されますが、この勾配の更新は新しい学習可能なベクトルに対してのみ適用されます。元のモデルは凍結されたままです。
このようにして学習されたソフトプロンプトは即座に人間が解釈できるものではありません。しかし、直感的なレベルでは、ソフトプロンプトはラベル付きデータセットからタスクを実行する方法に関する根拠を抽出し、手動で書かれたテキストプロンプトと同じ役割を果たし、しかしながら、個々の言語に制約される必要がありません。
JAXベースのT5Xフレームワークで実装された私たちのプログラム群は、誰でも簡単にこの手順を再現することができ、大きな学習率(0.3)を含む実用的なハイパーパラメータ設定が提供されています。(これは良い結果を得るために重要であると我々は考えています)
ソフトプロンプトはパラメータの使用量が小さいため(私たちはわずか512個のパラメータでプロンプトを訓練しています)、各入力サンプルと一緒に異なるプロンプトをモデルに渡すことが容易にできます。これにより、タスクが混合する推論バッチ(mixed-task inference batches)が可能となり、1つの推論モデルを多くのタスクで共有することでサービスを効率化することができます。
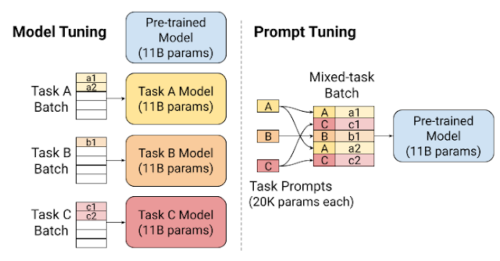
左:モデルチューニングにより、入力されたデータはタスクに特化したモデルに振り向けられます
右:プロンプトのチューニングにより、異なるタスクのサンプルやプロンプトが、1つの凍結モデルに大量に振り向け可能になり、サービス提供時に必要なリソースをより有効に活用できるようになりました。
3.Soft Prompt:プロンプトを人力でなく学習させる新手法(1/2)関連リンク
1)ai.googleblog.com
Guiding Frozen Language Models with Learned Soft Prompts
2)aclanthology.org
The Power of Scale for Parameter-Efficient Prompt Tuning(PDF)
3)github.com
google-research / prompt-tuning
