
1.V-MoEs:条件付き計算を使って視覚モデルの規模を拡大(2/2)まとめ
・Batch Priority Routingにより優先度の低いトークンを捨てる事を強制
・従来手法ではバッファ容量不足時に性能が低下するがBPRは堅牢
・ルーティングは意味的根拠に基づいてExpertsを識別している事も判明
2.BPRとは?
以下、ai.googleblog.comより「Scaling Vision with Sparse Mixture of Experts」の意訳です。元記事は2022年1月13日、Carlos RiquelmeさんとJoan Puigcerverさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Sebastian Herrmann on Unsplash
優先度付きルーティング
現実的には、ハードウェアの制約により、バッファを動的に確保して可変サイズで使用することは効率的ではないため、モデルでは通常、各Expertsに対してあらかじめ定義された固定サイズのバッファを使用します。
このバッファ容量を超えて割り当てられたトークンは、Expertsが「満杯」になると捨てられ、処理されなくなります。その結果、バッファ容量が大きいほど精度は高くなりますが、計算量も多くなります。この実装上の制約を利用して、推論時のV-MoEを高速化しています。
バッファの総容量を処理すべきトークンの数より少なくすることで、ネットワークはExperts層でいくつかのトークンの処理をスキップすることを余儀なくされます。
これまでの研究で行われてきたように、スキップするトークンを任意に選択するのではなく、重要度スコアに従ってトークンをソートするように学習させるのです。これにより、多くの計算を節約しながら、高品質の予測を維持することができます。
このアプローチをBPR(Batch Priority Routing)と呼び、下図に示します。

バッファサイズが大容量の場合、素のルーティングでも優先度付けルーティングも、すべてのパッチが処理されるため、うまく機能します。しかし、計算量を減らすためにバッファサイズを小さくすると、素のルーティングは任意のパッチを選択して処理するようになり、しばしば予測精度が低下します。BPRは、重要なパッチに優先順位をつけることで、より低い計算コストでより良い予測を実現します。
高品質で効率的な推論時予測を実現するためには、適切なトークンをドロップすることが重要であることがわかります。Expertsの能力が低下すると、素のルーティングメカニズムでは性能が急速に低下します。逆に、BPRはバッファサイズ低容量時により堅牢になります。
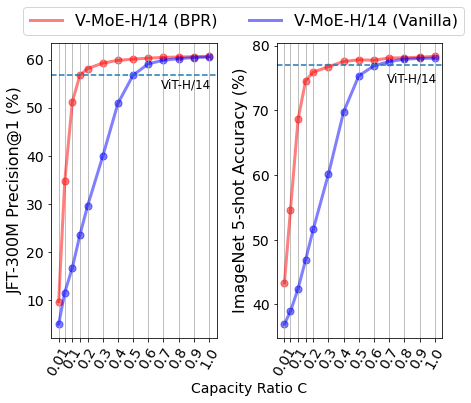
V-MoE-H/14モデル(K=2)の性能と推論時のバッファサイズ(または比率)Cの関係
Cが大きい場合でもBPRは性能を向上させ、Cが小さい場合はその差はかなり大きくなります。BPRはトークンの15-30%を処理するだけで、高密度モデル(ViT-H/14)に匹敵する性能を発揮します。
全体として、V-MoEは推論時に非常に柔軟であることが観察されました。例えば、モデルの重みをさらに訓練することなく、時間と計算を節約するために、トークン毎に選択するExpertsの数を減少させることができます。
V-MoEを探索する
疎なネットワークの内部構造についてはまだ解明されていないことが多いため、V-MoEのルーティングパターンを調査しました。
一つの仮説は、ルータが何らかの意味的根拠に基づいてExpertsを識別し、トークンを割り当てるように学習するという事です。(「車」の専門家、「動物」の専門家、といった具合に)。
これを検証するために、以下に2つの異なるMoE層(入力レイヤーに近いレイヤーと、出力レイヤーに近いレイヤー)の図を以下に示します。
X軸は32個のExpertsのそれぞれに対応し、Y軸は画像クラスのID(1から1000まで)を示しています。
この図は、特定の画像クラスに対応するトークンにエキスパートが選択された頻度を示しており、色が濃いほど頻度が高いことを示しています。初期レイヤーではほとんど相関がありませんが、ネットワークの後半では、各Expertsはほんの一握りのクラスからトークンを受け取り、処理するようになります。
したがって、ネットワークの深い層では、各画像の断片を意味的なクラスタリングをする機能が出現していると結論付けることができます。
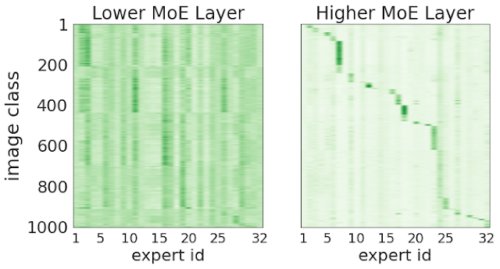
より後半のルーティングの決定は、画像のクラスと相関しています。
上図はV-MoE-H/14の2つのMoEレイヤーです。x軸は1つの層に含まれる32のExpertsに相当します。
Y軸は1000のImageNetクラスで、両軸の順序は(相関を強調するため)左右で異なっていまする。各ペア(Experts e、クラスc)について、その特定のExperts eにクラスcに所属する画像に対応するトークンがルーティングされた際の重みの平均を示しています。
最終的な結論
私たちは、条件付き計算を用いて非常に大きな視覚モデルを訓練し、比較的少ない訓練コストで特徴表現と転移学習の大幅な改善を実現しました。V-MoEと同時に、Experts層で最も有用なトークンのみを処理するようモデルに要求するBPRを導入しました。
私たちは、これがコンピュータビジョンのための大規模な条件付き計算の始まりに過ぎないと考えています。本研究の拡張には、マルチモーダルおよびマルチタスクモデル、Experts数の拡大、疎なモデルによって生成される特徴表現の転移の向上が含まれます。
また、異種のExpertsアーキテクチャ(Heterogeneous expert architectures)や条件付き可変サイズルート(conditional variable-length routes)も有望な方向性です。
スパースモデルは、大規模なビデオモデリングのようなデータが豊富な領域で特に役立つと考えられます。私たちは、オープンソースのコードとモデルが、この分野の新しい研究者を惹きつけ、参加させるのに役立つことを期待しています。
謝辞
共著者に感謝します。
Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, 及び Neil Houlsby。 また、Alex Kolesnikov, Lucas Beyer, そしてXiaohua Zhaiには、ViTモデルのスケーリングについて継続的な支援と詳細な情報を提供いただきました。
また、Josip Djolonga, Ilya Tolstikhin, Liam Fedus,Barret Zophには論文へのフィードバックをいただきました。
James Bradbury, Roy Frostig, Blake Hechtman, Dmitry Lepikhin, Anselm Levskaya, そして Parker SchuhにはJAXモデルをTPUで効率的に実行できるよう、貴重なサポートをいただきました。
その他Brainチームの多くの方々には感謝の意を表します。最後に、この投稿で使用した素晴らしいアニメーション図を提供してくれたTom Smallにも感謝し、謝意を表したいと思います。
3.V-MoEs:条件付き計算を使って視覚モデルの規模を拡大(2/2)関連リンク
1)ai.googleblog.com
Scaling Vision with Sparse Mixture of Experts
2)arxiv.org
Scaling Vision with Sparse Mixture of Experts
3)github.com
google-research / vmoe

