
1.視覚を聴覚で補うような脳の感覚置換能力を実現する強化学習(2/2)まとめ
・順列不変のニューラルネットワークは、未定義で変化する観測空間を扱うことが可能
・冗長な情報やノイズの多い情報を含む観測結果や破損した不完全な観測結果に対しても堅牢
・ゲームの背景を新しい画像に置き換えるような初見タスクに対する一般化性能も向上
2.順列不変システムとは?
以下、ai.googleblog.comより「Permutation-Invariant Neural Networks for Reinforcement Learning」の意訳です。元記事は2021年11月18日、Google Research TokyoのDavid HaさんとYujin Tangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Tony Rojas on Unsplash
メッセージを拡散(broadcasts)するように感覚ニューロンをトレーニングすることにより、ニューロンが互いに通信するように仕向けます。
自身で情報を受信している間、個々の感覚ニューロンはまた、各タイムステップで継続的に出力メッセージを拡散します。これらのメッセージは連結され、と呼ばれる出力ベクトルに結合されます。
Transformerアーキテクチャで適用されるものと同様のアテンションメカニズムを使用して、グローバル潜在コード(global latent code)と呼ばれる出力ベクトルに統合および結合されます。
次に、ポリシーネットワークは、グローバル潜在コードを使用して、エージェントが環境と対話するためのアクションを生成します。このアクションは、次のタイムステップで各感覚ニューロンにもフィードバックされ、通信ループが閉じられます。
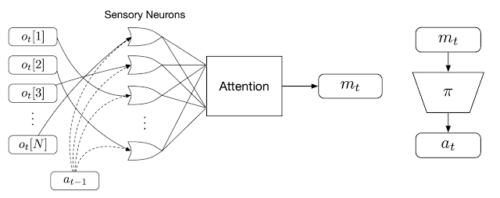
順列不変強化学習手法の概要
まず、個々の観測値(ot)を特定の感覚ニューロンに入力します。(エージェントの前回の行動(at-1)も一緒に)。その後、各ニューロンは独立にメッセージを生成して拡散し、Attentionメカニズムがそれらをグローバルな潜在コード(mt)にまとめ、エージェントの下流のポリシーネットワーク(𝜋)に与えて、エージェントの行動atを生成します。
なぜこのシステムは順列不変(permutation invariant)なのでしょうか?
各感覚ニューロンは、ある特定の感覚入力からの情報のみを処理することに限定されない、同等のニューラルネットワークです。実際、このシステムでは、各感覚ニューロンへの入力は定義されていません。各ニューロンは、固定された意味を明示的に仮定するのではなく、他の感覚ニューロンが受け取る入力に注意を払いながら、入力信号の意味を理解しなければなりません。
これにより、エージェントは入力全体を無秩序なセットとして処理するようになり、システムは入力に対して順列不変になります。さらに、原理的には、エージェントは必要なだけ多くの感覚ニューロンを使うことができるので、任意の長さの観測を処理することができます。これらの特性は、エージェントが「感覚置換(sensory substitution)」に適応するのに役立ちます。
実験結果
このアプローチの堅牢性と柔軟性を、より単純な状態観測環境で実証しました。この環境では、エージェントが入力として受け取る観測値は、エージェントの構成要素の位置や速度など、エージェントの状態に関する情報を持つ低次元のベクトルです。
人気のあるAntの移動タスクエージェントは、位置と速度を含む情報を持つ合計28個の入力を持っています。試行中に入力ベクトルの順序を何度か入れ替えてみたところ、エージェントは速やかに適応し、前に向かって歩くことができました。
cart-poleタスクでは、エージェントの目的は、カートの中心に取り付けられたカートポールを振り上げ、直立してバランスをとることです。通常、エージェントには5つの入力しかありませんが、cart-poleの環境を変更して、15個のシャッフルされた入力信号を用意しました。15の内10は純粋なノイズで、残りの5は環境実際の環境から取得した入力です。
このような状態でも、エージェントはタスクを実行することができました。これは、システムが多数の入力を処理し、有用と思われるチャンネルにのみ注意を払うことができることを示しています。このような柔軟性は、定義されていないシステムからの、ほとんどがノイズである不特定多数の信号を処理するのに有用なアプリケーションを見つけることができます。
また、このアプローチを、観測対象が画像内の画素として連続して入力される高次元の視覚ベースの環境にも適用します。ここでは、画面を分割してシャッフルした視覚ベースのRL環境について検討しています。各観測フレームは格子状の画像断片に分割され、パズルのように、エージェントはシャッフルされた順序で断片を処理して、取るべき行動を決定しなければなりません。視覚ベースのタスクに対する私達のアプローチを実証するために、シャッフル版のAtariのピンポンゲームを作成しました。


シャッフル版ピンポンゲームの結果
左:断片を30%しか使わないように学習したPongエージェントはAtari社の対戦CPUと互角の性能です。
右:追加の訓練を行わなくても、パズル内のピースを増やすと、エージェントの性能が向上します。
ここでは、エージェントの入力は長さが定まっていない画面の断片のリストであり、典型的なRLエージェントとは異なり、エージェントはスクリーンの断片の一部を「見る」だけです。
パズル化したピンポンゲームの実験では、スクリーンの断片をランダムに抽出したものをエージェントに渡し、それをゲームの残りの時間にわたって固定します。その結果、全断片の70%(固定されたランダムな位置)を渡さずとも、エージェントは内蔵されたアタリの対戦相手に対して良い結果を出すように訓練できることがわかりました。
興味深いことに、エージェントに追加の情報を与えた場合(例えば、より多くの画像断片にアクセスできるようにした場合)、追加のトレーニングを行わなくても、エージェントのパフォーマンスは向上しました。全ての断片をシャッフルして受け取った場合、エージェントは100%の確率で勝利し、画面全体を見ながら学習したエージェントと同じ結果を得ることができました。
このように、順序付けされていない観測データを用いて、学習時にさらなる困難を課すことは、CarRacingの学習環境の背景を新しい画像に置き換えたときのような、経験したことのないタスクに対する一般化を向上させるなど、さらなる利点があることがわかりました。

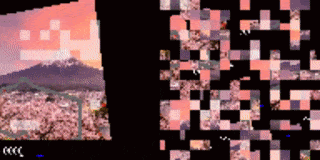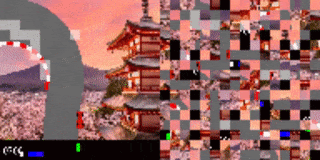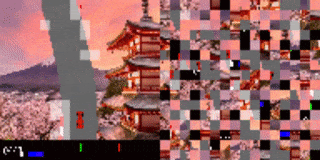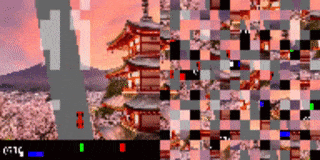
シャッフルされたCarRacingの結果
エージェントは、道路の境界(強調表示された断片)に注意を向けることを学習しました。
左:トレーニング環境
右:背景を変更したテスト環境
結論
今回発表した順列不変のニューラルネットワークエージェントは、定義されていない、変化する観測空間を扱うことができます。私達のエージェントは、冗長な情報やノイズの多い情報を含む観測結果や、破損した不完全な観測結果に対しても堅牢です。私達は、順列不変システムが強化学習における多くの可能性を開くと信じています。
この研究にご興味のある方は、インタラクティブなページやビデオをご覧ください。また、私達の実験を再現するためのコードもgithubで公開しています。
3.視覚を聴覚で補うような脳の感覚置換能力を実現する強化学習(2/2)関連リンク
1)ai.googleblog.com
Permutation-Invariant Neural Networks for Reinforcement Learning
2)attentionneuron.github.io
The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning
3)github.com
google / brain-tokyo-workshop

