
1.XMC-GAN:クロスモーダルな対照学習でテキストから画像を生成(1/2)まとめ
・テキストの説明文から画像を生成する合成タスクは最近大きな注目を集めている
・従来の画像合成手法はGANを使うケースが多いがモード崩壊などの問題を抱える
・XMC-GANは画像対テキストと画像対画像の対照的損失を利用する新手法
2.XMC-GANとは?
以下、ai.googleblog.comより「Cross-Modal Contrastive Learning for Text-to-Image Generation」の意訳です。元記事の投稿は2021年5月26日、Han ZhangさんとJing Yu Kohさんによる投稿です。
OpenAIのDALL·EのGoogle版ですかね。
Crossから安直に連想したアイキャッチ画像のクレジットはPhoto by Mohamed Nohassi on Unsplash
テキストの説明文だけから画像を生成するようにモデルをトレーニングする、「テキストから画像の自動合成(Automatic text-to-image synthesis)」タスクは、最近大きな注目を集めている挑戦的なタスクです。
この研究は、機械学習(ML:Machine Learning)モデルが視覚的属性を捉え、それらをテキストに関連付ける方法について豊富な洞察を提供します。
スケッチ、オブジェクトマスク、マウスの動き(以前の研究で紹介した)など、画像生成に繋がる他の種類の入力と比較して、説明文は視覚的な概念を表現するためのより直感的で柔軟な方法です。
従って、テキストから画像を自動生成する強力なシステムは、迅速なコンテンツ作成にも役立つツールであり、機械学習をアートの作成に統合する他の取り組みと同様に、他の多くのクリエイティブ アプリケーションに適用できます。(例:Magentaプロジェクト)
最先端の画像合成は、通常、2 つのモデルをトレーニングする敵対的生成ネットワーク(GAN:Generative Adversarial Networks)を使用して達成されます。現実的な画像を作成しようと試みるジェネレーター(generator)と、画像が本物か偽物かを判断しようとするディスクリミネーター(discriminator)です。
テキストから画像を生成するモデルの多くはGANです。意味的に関連する画像を生成するためにテキスト入力を使用するよう条件付けられています。これは、特に長く曖昧な説明文が入力として提供されている場合、非常に困難です。
更に、GANのトレーニングはモード崩壊する可能性があります。これは、ジェネレーターが限られた出力セットのみを生成することを学習してしまうトレーニング プロセスの一般的な失敗例です。
モードの崩壊を軽減するために、いくつかのアプローチは、画像を反復的に改良する多段階改良ネットワークを使用します。ただし、このようなシステムには多段階のトレーニングが必要であり、これは単純な1段階の直接実行モデルよりも効率的ではありません。
他の取り組みは、最終的に現実的な画像を合成する前に、最初に物体のレイアウトをモデル化する階層的アプローチに依存しています。これには、ラベル付けされたセグメンテーション データを使用する必要がありますが、これは取得が難しい場合があります。
CVPR 2021で紹介する論文「Cross-Modal Contrastive Learning for Text-to-Image Generation」では、クロスモーダルで対照学習を行う敵対的生成ネットワーク(XMC-GAN:Cross-Modal Contrastive Generative Adversarial Network)を紹介します。
これは、モーダル間(画像対テキスト)およびモーダル内(画像対画像)の対照的損失を使用して、画像とテキスト間の相互情報量を最大化することを学習することにより、テキストから画像への生成に対処します。
このアプローチは、ディスクリミネーターがより堅牢な識別特徴を学習するのに役立つため、XMC-GAN は 1段階のトレーニングでもモード崩壊の傾向が少なくなります。重要な点として、XMC-GAN は、以前の多段階または階層的アプローチと比較して、単純な1段階生成で最先端のパフォーマンスを実現します。
これは直接トレーニング可能であり、画像とテキストのペアのみが必要です。(ラベル付きのセグメンテーションまたは境界ボックス データが必要となる他の手法とは対照的です)
テキストから画像を合成する際の対照的な損失
テキストから画像を合成するシステムの目標は、条件付きのテキストの説明に対して高い意味的忠実度を持つ、鮮明で写真のようにリアルな風景を生成することです。これを達成するために、対応するペア間の相互情報量を最大化することを提案します。
(1) 風景を説明する文章とその文章が描写する画像(実際の画像または生成された画像)
(2) 同じ説明を持つ生成画像と実画像
(3) 実際の画像または生成された画像の領域およびその領域に関連付けられた単語または句
XMC-GAN では、これは対照的な損失を使用するように強制されます。他のGANと同様に、XMC-GAN には、画像を合成するためのジェネレーターと、実際の画像と生成された画像を区別する批評家として機能するように訓練されたディスクリミネーターが含まれています。
このシステムでは、3つのデータ セットが対照的な損失に寄与します。実際の画像、それらの画像を説明するテキスト、テキストの説明から生成された画像です。
ジェネレーターとディスクリミネーターの両方の個々の損失関数は、完全なテキストの説明を含む画像全体から計算された損失と、関連する単語または語句を含む細分化された画像から計算された損失の組み合わせです。
次に、トレーニングデータの各バッチについて、各テキストの説明と実際の画像の間、および同様に、各テキストの説明と生成された画像のバッチの間で、コサイン類似度スコアを計算します。
目標は、一致するペア(テキストと画像、および実際の画像と生成された画像の両方))が高い類似性スコアを持ち、一致しないペアが低いスコアを持つことです。このような対照的な損失を強制することで、弁別器はより堅牢で弁別的な特徴を学習することができます。
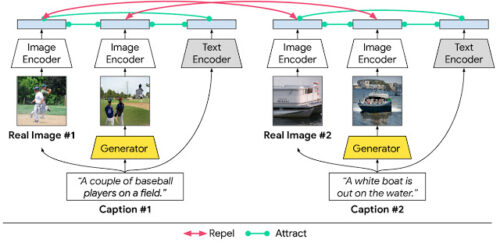
提案された XMC-GAN
テキストから画像を合成するモデルにおけるインターモーダルおよびイントラモーダルな対照学習
3.XMC-GAN:クロスモーダルな対照学習でテキストから画像を生成(1/2)関連リンク
1)ai.googleblog.com
Cross-Modal Contrastive Learning for Text-to-Image Generation
2)arxiv.org
Cross-Modal Contrastive Learning for Text-to-Image Generation
3)magenta.tensorflow.org
Magenta

