
1.RLiable: 強化学習における信頼性の高い性能評価指標(2/2)まとめ
・同じ実験を他で繰り返した場合の集約指標を予測する層別ブートストラップ信頼区間を提唱
・パフォーマンスプロファイルによりアルゴリズム間の定性的な比較が一目瞭然となる
・集約した指標として平均値や中央値の代替として四分位平均と最適性ギャップを提唱
2.RLiableの使い方
以下、ai.googleblog.comより「RLiable: Towards Reliable Evaluation & Reporting in Reinforcement Learning」の意訳です。元記事は2021年11月17日、Rishabh AgarwalさんとPablo Samuel Castroさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Erik Mclean on Unsplash
信頼性の高い評価のためのツール
有限回の試行に基づいた集約指標はランダムな変数であるため、これを考慮して、層別ブートストラップ信頼区間(CIs:stratified bootstrap confidence intervals)を報告することを提唱します。
この信頼区間は、同じ実験を他で繰り返した場合に、集約指標値がどのようになるかを予測するCIで、結果の統計的不確実性と再現性を理解することができます。
このようなCIは、実行したタスク結果を組み合わせたスコアを使用します。例えば、26個のタスクを含むAtari 100kで3回ずつ評価した場合、不確実性推定のための78個のサンプルスコアが得られます。
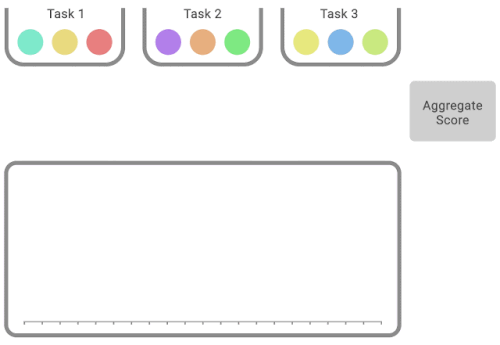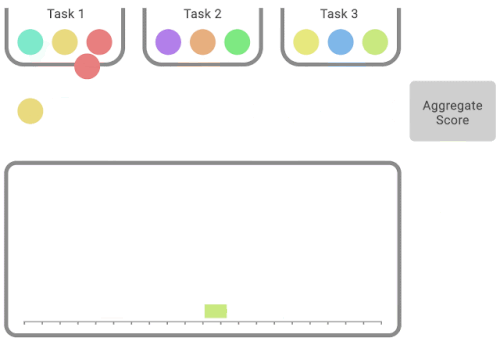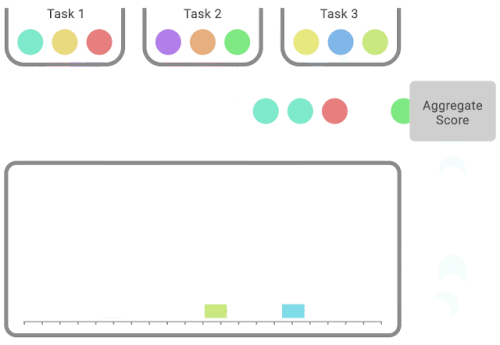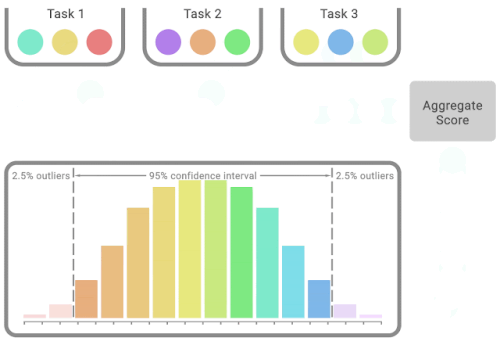
それぞれのタスクで、色のついたボールが異なる試行時のスコアを示します。パーセンタイル法を用いて統計的ブートストラップCIを計算するために、各タスクから比例的にスコアを無作為にサンプリングしてブートストラップサンプルを作成します。そして、これらのサンプルの集計スコアの分布がブートストラップ分布となり、その中心付近の広がりが信頼区間となります。
ほとんどの深層強化学習アルゴリズムは、幾つかのタスクや試行では、より良いパフォーマンスを発揮することが多いのですが、以下に示すように、性能指標を集約することで、このばらつきを隠すことができます。
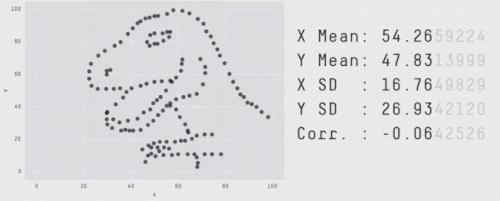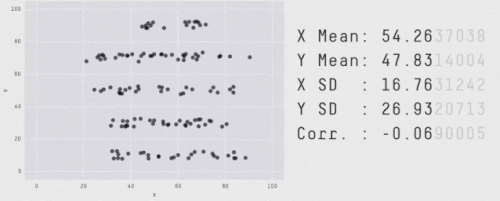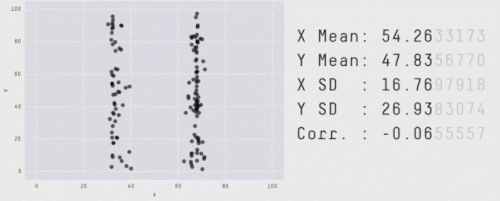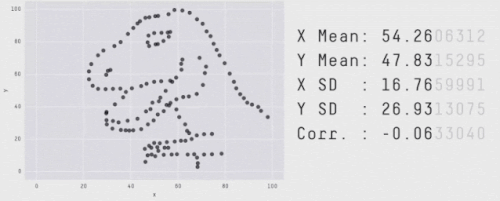
見た目はバラバラであっても集計値が同じになるデータ。
出典「Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing」
その代わりに、パフォーマンスプロファイルの使用をお勧めします。パフォーマンスプロファイルは最適化ソフトウェアが短縮した時間を比較する際などに一般的に使用されています。
これは、すべての試行とタスクのスコア分布を、層別ブートストラップ信頼帯を用いた不確実性推定値とともにグラフ化したものです。
これらのプロットは、しきい値(𝝉)以上のスコアを得たすべてのタスクの合計試行を、しきい値の関数として示しています。
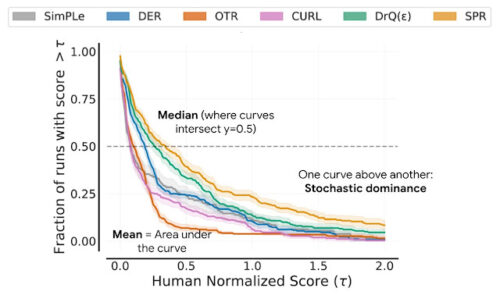
パフォーマンスプロファイルは,すべてのタスクの試行を組み合わせたスコアの経験的な裾の長い分布(tail distribution)に対応します。色付き部分は95%層別ブートストラップ信頼帯を示します。
このようなプロファイルにより、定性的な比較が一目でできるようになります。たとえば、あるアルゴリズムの曲線が他のアルゴリズムよりも上にある場合は、そのアルゴリズムの方が優れていることを意味しています。
また、任意のスコアパーセンタイルを読み取ることができます。例えば、プロファイルは、スコアの中央値でy = 0.5(点線)と交差します。さらに、プロファイルの下の領域は平均スコアに対応しています。
パフォーマンスプロファイルは定性的な比較には有用ですが、すべてのタスクにおいてアルゴリズムが他のアルゴリズムを上回ることは稀であり、そのためプロファイルが交差することも多く、より細かい定量的な比較には集約したパフォーマンス指標が必要となります。
しかし、既存の指標には限界があります。
(1)1つの高パフォーマンスタスクがタスクの平均スコアに強く影響を及ぼす可能性がある
(2)タスク中央値はほぼ半分のタスクがゼロスコアであっても影響を受けず、小さな統計的不確実性のために多数のトレーニングランを必要とする。
上記の限界を解決するために、堅牢な統計(robust statistics、外れ値の影響を過度に受けない統計手法)に基づいた2つの代替案を推奨します。それは、四分位平均(IQM:InterQuartile Mean)と最適性ギャップ(optimality gap)であり、どちらも以下のパフォーマンスプロファイルの下部領域と読み替えることができます。
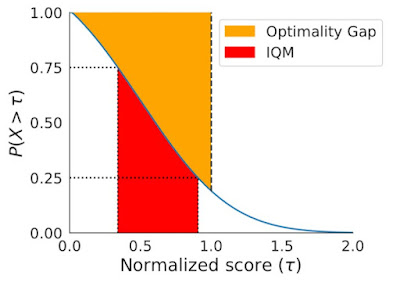
IQM(赤)は青線で示されたパフォーマンス・プロファイルの下部領域に対応します。x軸上の25パーセンタイルと75パーセンタイルのスコアの間です。最適性ギャップ(黄色)は、スコアが1未満の場合、プロファイルとy = 1(人間のパフォーマンス)の水平線との間の面積に相当する。
中央値や平均値に代わるものとして、IQMは、すべてのタスクの試行のうち、中間の50%のスコアの平均値に相当します。平均値よりも外れ値に強く、中央値よりも全体的なパフォーマンスの指標となり、CIも小さくなるため、改善された事を主張するために必要な実行回数も少なくて済みます。平均値に代わるもう一つの指標である最適性ギャップは、アルゴリズムが最適なパフォーマンスからどれだけ離れているかを測定します。
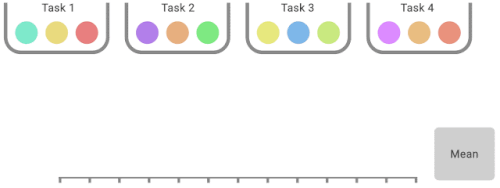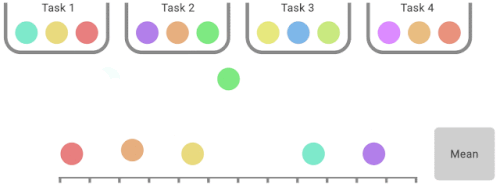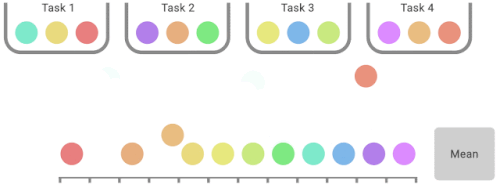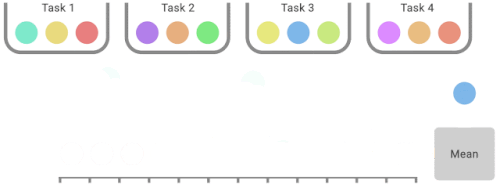
IQMは、合計スコアのうち最低25%と最高25%のスコア(色付きボール)を捨て、残りの50%のスコアの平均値を計算します。
2つのアルゴリズムを直接比較する場合に考慮すべきもう1つの指標は、改善の平均確率(average probability of improvement)で、これは、その大きさにかかわらず、ベースラインよりも改善される可能性がどの程度あるかを示します。この指標は、タスク間で平均化されたマン・ホイットニーのU統計(Mann-Whitney U-statistic)を用いて計算されます。
評価手法を再評価
前述の評価ツールを用いて、広く使われているRLベンチマークにおける既存アルゴリズムの性能評価を再検討したところ、これまでの評価の不整合が明らかになりました。
例えば、RLベンチマークとして広く知られているALE(Arcade Learning Environment)では、集計指標の選択によってアルゴリズムの性能順位が変化します。パフォーマンスプロファイルは全体像を把握することができるため、このような不整合が生じる原因を明らかにすることができます。
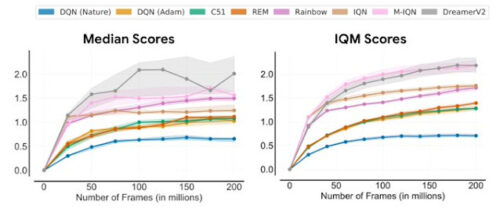
中央値(左)とIQM(右)のALEにおける人間の正規化スコアを、トレーニング中に見た環境内のフレーム数の関数として表したもの。IQMでは中央値よりも有意に小さいCIが得られています。
一般的な連続制御ベンチマークであるDM Controlでは、ほとんどのアルゴリズムで平均正規化スコアの95%CIに大きなオーバーラップが見られます。
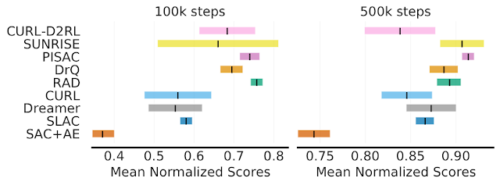
10万ステップおよび50万ステップのベンチマークにおいて、6つのタスクで平均化されたDM Control Suiteの結果。スコアは最大性能で正規化されているため、平均スコアは1から最適性ギャップを引いたものに相当します。Dreamerを除くすべてのアルゴリズムは、その下に配置された少なくとも1つのアルゴリズムに対する改善を主張しています。色付き部分は95%CIを示します。
最後に、強化学習の一般化を評価するベンチマークであるProcgenにおいて、改善の平均確率を見ると、いくつかの主張された改善は50-70%の確率しかなく、報告された改善が偽りである可能性を示唆しています。
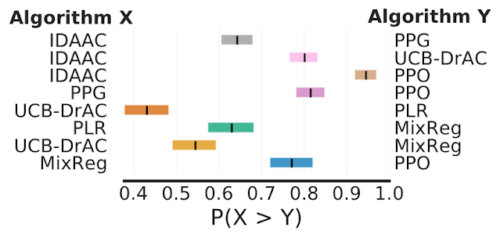
各行は、XがYよりも優れていると主張された場合に、左のアルゴリズムXが右のアルゴリズムYよりも優れている確率を示しています。色付き部分は95%層別ブートストラップCIを示します。
結論
広く使われている深層強化学習のベンチマークで得られた知見によると、統計分析の問題が以前に報告された結果に大きな影響を与えることがあります。本研究では、報告された結果の解釈を改善し、実験報告を標準化するために、評価方法を再検討しました。今後の統計分析を可能にするために、発表論文ではすべての実行結果を提供することが重要であることを強調したいと思います。ご自分の結果に自信を持つために、オープンソースで公開したライブラリRLiableと手早く開始するためのcolabをご覧ください。
謝辞
この研究は、Max Schwarzer, Aaron Courville そして Marc G. Bellemareとの共同研究で行われました。また、この記事で使用しているアニメーション図を提供してくださったTom Smallに感謝します。また、Google Research、Brain Team、DeepMindの複数のメンバーからのフィードバックにも感謝します。
3.RLiable: 強化学習における信頼性の高い性能評価指標(2/2)関連リンク
1)ai.googleblog.com
RLiable: Towards Reliable Evaluation & Reporting in Reinforcement Learning
2)agarwl.github.io
Deep RL at the Edge of the Statistical Precipice
3)github.com
google-research / rliable
4)colab.research.google.com
deep_rl_precipice_colab.ipynb

