
1.言語モデルに思考の連鎖を促し推論能力を向上(2/2)まとめ
・算術的推論は標準的なプロンプトでは比較的平坦に規模拡大と共に性能が向上する
・思考の連鎖プロンプトではモデル規模を大きくすると標準プロンプトを大幅に上回った
・追加の改良を行いGPT-3 1750の55%を上回る74%の精度を算術推論で達成した
2.思考の連鎖プロンプトの性能
以下、ai.googleblog.comより「Language Models Perform Reasoning via Chain of Thought」の意訳です。元記事は2022年5月11日、Jason WeiさんとDenny Zhouさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Andisheh A on Unsplash
算術的推論
言語モデルが苦手とするタスクのひとつに、算術推論(数学の文章問題を解くこと)があります。算術推論のベンチマークにはMultiArithとGSM8Kがあり、上図に示したような多段階の計算問題を解く言語モデルの能力が試されます。
このベンチマークでは、4.22億から1370億パラメータを持つ言語モデルのLaMDAコレクションと、80億から5400億パラメータを持つ言語モデルのPaLMコレクションの両方を評価しています。思考連鎖のプロンプトの例では、手動で思考連鎖を構成しています。
この2つのベンチマークでは、標準的なプロンプトを使用すると、比較的平坦に規模拡大と共に性能が向上するグラフになります。しかし、思考の連鎖プロンプトを使用する場合、モデル規模を大きくすると、標準プロンプトを大幅に上回る性能向上が見られることが分かりました。
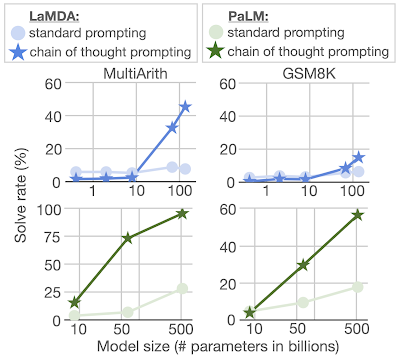
思考連鎖プロンプトを用いることで、標準プロンプトではほぼ平坦に性能が向上する算数推論問題を言語モデルで解くことができます。
数学の文章問題のGSM8Kデータセットにおいて、PaLMは5400億のパラメータに拡張されたときに顕著な性能を示しました。これは、GPT-3 1750億を大規模な訓練セットで微調整し、特別に訓練した検証機で解答候補をランク付けすることで達成した55%を上回る性能です。
さらに、自己一貫性(self-consistency)に関する研究により、生成された推論プロセスの幅広い集合の多数決を取ることで、思考連鎖プロンプトの性能がさらに向上することが示され、GSM8Kでは74%の精度が達成されました。
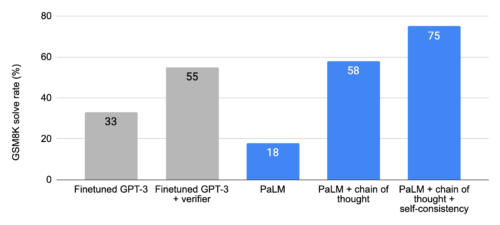
PaLMを用いた思考連鎖プロンプトは、GSM8Kベンチマーク(数学の文章問題)において、最先端のスコアを達成しました。また、微調整を行ったGPT-3と公正に比較するため、ここで示した思考連鎖プロンプトの結果は、基本的な算術関数(すなわち、加算、減算、乗算、除算)の計算に外部の計算機を使用しています。
常識的推論
算術的推論に加え、言語ベースの思考連鎖プロンプトの性質から、一般的な背景知識を前提とした物理的・人間的相互作用に関する推論である常識的推論への適用も検討しました。これらの評価には、CommonsenseQAとStrategyQAベンチマーク、およびBIG-Bench連携による日付理解とスポーツ理解の2つの領域特化型タスクを用いました。以下に質問例を示します。

以下に示すように、CommonsenseQA、StrategyQA、そしてDate Understandingでは、モデル規模によってパフォーマンスが向上し、さらに思考の連鎖のプロンプトによって、小さな改善がもたらされました。sports understandingでは、連鎖的思考プロンプトの効果が最も大きく、PaLM 5400億の思考の連鎖能力は、スポーツ愛好家が独力で回答したスコアを上回りました(95%対84%)。
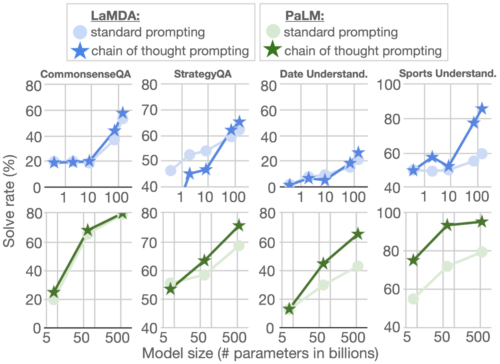
思考連鎖のプロンプトは、様々なタイプの常識的推論タスクのパフォーマンスも向上させます。
結論
思考連鎖プロンプトを使うと言語モデルは様々な推論タスクを実行する能力を向上させる事が可能になります。更に、簡単で広く適用可能な手法です。
算術と常識的推論の実験を通して、思考連鎖プロンプトがモデル規模に関連して出現する特性であることを見出しました。
言語モデルが実行できる推論タスクの範囲を広げることで、言語ベースの推論へのアプローチに関するさらなる研究が促されることが期待されます。
謝辞
Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Quoc Leとこのプロジェクトで一緒に仕事ができたことは光栄でした。
3.言語モデルに思考の連鎖を促し推論能力を向上(2/2)関連リンク
1)ai.googleblog.com
Language Models Perform Reasoning via Chain of Thought
2)arxiv.org
Chain of Thought Prompting Elicits Reasoning in Large Language Models

