
1.取り返しのつかない行動を避ける可逆性を意識した自己教師型強化学習(1/3)まとめ
・強化学習エージェントは試行錯誤を繰り返するで元に戻せない行動をしてしまう事がある
・現実のロボットが部品破損につながる可能性のあるアクションを実行することは避けたい
・アクションの先行性に注目してこの問題を教師無しで解決する手法を新たに考案した
2.アクションの可逆性とは?
以下、ai.googleblog.comより「Self-Supervised Reversibility-Aware Reinforcement Learning」の意訳です。元記事の投稿は2021年11月3日、Johan Ferretさんによる投稿です。
今回のお話もあったまいーなー、と感心しました。強化学習に興味を持ってる方は必読です。
倉庫番を意識したアイキャッチ画像のクレジットはPhoto by National Cancer Institute on Unsplas
ロボット工学からチップ設計まで、さまざまなアプリケーション用のエージェントをトレーニングする際に良く使用される手法は、強化学習(RL:reinforcement learning)です。
RLは、0からタスクを解決する方法を見つけることに優れていますが、エージェントがそのアクションの可逆性(reversibility)を理解するようにトレーニングするのに苦労する可能性があります。
これは、エージェントが環境内で安全に動作することを保証するために重要です。たとえば、通常、ロボットにはコストがかかり、メンテナンスが必要なため、部品破損につながる可能性のあるアクションを実行することは避けたいと考えられます。
可逆性、すなわちアクションが元に戻せるかどうか(または、より簡単に元に戻すことができるかどうか)を見積もるためには、エージェントが動作している環境内の物理に関する実用的な知識が必要です。ただし、標準のRL設定では、エージェントはこれを行うのに十分な環境のモデルを持っていません。
NeurIPS 2021で受理された論文「There Is No Turning Back: A Self-Supervised Approach to Reversibility-Aware Reinforcement Learning」では、RLでエージェントアクションの可逆性を概算する斬新で実用的な手法を紹介します。
このアプローチは、可逆性対応強化学習(Reversibility-Aware RL)と呼ばれ、自己教師型(つまり、エージェントによって収集されたラベルのないデータから学習します)のRLプロシージャに独立した可逆性推定コンポーネントを追加します。
オンライン(RLエージェントが自ら収集した相互作用データ)またはオフライン(蓄積した過去の相互作用データから)のいずれかでトレーニングできます。その役割は、RLポリシーを可逆的な動作に向けて導くことです。このアプローチは、挑戦的なパズルゲームである「倉庫番(Sokoban)」を含むいくつかのタスクでRLエージェントのパフォーマンスを向上させます。
可逆性対応強化学習
RLプロシージャに追加された可逆性コンポーネントは、相互作用から学習され、重要なことに、エージェントとは別にトレーニングできるモデルです。
モデルのトレーニングは自己教師型であり、アクションの可逆性でデータにラベルを付ける必要はありません。代わりに、モデルは、トレーニングデータのみによって提供されるコンテキストから、どのタイプのアクションが可逆的であるか傾向を学習します。
私達はこの経験的可逆性(empirical reversibility)を「AとBの両方が起こることを知りながら、ある事象Aが別の事象Bに先行する確率の尺度」と理論的に説明しています。
先行性(Precedence)は、報酬がなくても相互作用のデータセットから学習することができるので、真の可逆性の有用な代理となります。
例えば、テーブルの高さからグラスを落とし、床に落ちて粉々になるという実験を想像してみてください。この場合、グラスは位置A(テーブルの高さ)から位置B(床)へと移動し、試行回数にかかわらず、常にAがBよりも先行するため、事象のペアを無作為に抽出した場合、AがBよりも先行するペアが見つかる確率は1となり、不可逆的な順序であることがわかります。
次に、ガラスの代わりにゴムボールを落としたとします。この場合、ボールは位置Aから始まり、位置Bに落ち、(近似的には)Aに戻ります。従って、事象のペアをランダムに抽出した場合、AがBよりも先に起こるペアを見つける確率は0.5(ランダムなペアであればBがAよりも先に起こる確率と同じ)にしかならず、これは可逆的な順序を示しています。
可逆性の推定は、世界の動力学の知識に依存します。可逆性の代替として、先行性(Precedence)あります。これは、2つのイベントが観測された場合に、平均してどちらが先に来るかを示すものです。
実務的には、相互作用を集めた学習用データからイベントのペアを抽出し、それらをシャッフルし、イベントの実際の時系列を再構築するようにニューラルネットワークを訓練します。
ネットワークの性能は、実際のデータのタイムスタンプから得られる本当の順序と予測値を比較することで測定・改良できます。時間的に離れた場所にあるイベントは、些細なことであったり、順序付けが不可能であったりする傾向があるため、一定の大きさの時間的な窓の中でイベントを抽出します。そして、この推定器の予測確率を可逆性の代用とします。イベントAがイベントBの前に起こるというニューラルネットワークの確信度が、選択した閾値よりも高ければ、イベントAからBへの移行は不可逆的であると判断します。
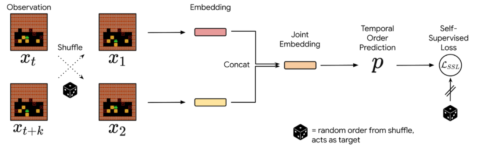
先行性の推定はランダムにシャッフルされたイベントの時間的順序を予測することです。
3.取り返しのつかない行動を避ける可逆性を意識した自己教師型強化学習(1/3)関連リンク
1)ai.googleblog.com
Self-Supervised Reversibility-Aware Reinforcement Learning
2)arxiv.org
There Is No Turning Back: A Self-Supervised Approach for Reversibility-Aware Reinforcement Learning

