
1.BERTとTF-Rankingを使ってランキングシステムの透明性と解釈可能性を向上(2/2)まとめ
・一般化加法モデルは解釈可能な機械学習モデルだがランキングにはあまり使用されていなかった
・ニューラルランキングGAMを開発し解釈可能なコンパクトなモデルを導出できるようになった
・DASALCモデルでLambdaMARTに対するニューラルランキングモデルの同等性を確立
2.ランク付け学習とは?
以下、ai.googleblog.comより「Advances in TF-Ranking」の意訳です。元記事の投稿は2020年7月27日、Michael BenderskyさんとXuanhui Wangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Leslie Jones on Unsplash
解釈可能なランク付け学習(Learning-to-Rank)
透明性と解釈可能性は、ローンの適格性評価、広告ターゲティング、治療決定のガイドなどの決定プロセスに関与するランキングシステムにLTRモデルを展開する際に重要な要素となります。このような場合、結果の透明性、説明責任、および公平性を確保するために、最終的なランキング結果への個々の特徴の貢献度は、調査可能で理解できるものでなければなりません。
これを実現するための1つの可能な方法は、一般化加法モデル(GAM:Generalized Additive Models)を使用することです。これは、個々の特徴の滑らかな関数で線形に構成される本質的に解釈可能な機械学習モデルです。
ただし、GAMは回帰および分類タスクについて広く研究されてきましたが、ランキング設定でGAMを適用する方法はあまり明確ではありません。
たとえば、GAMはリスト内の個々のアイテムをモデル化するために簡単に適用できますが、アイテムの相互作用とこれらのアイテムがランク付けされる場面の両方をモデル化することは、より困難な研究問題です。この目的のために、私たちはニューラルランキングGAMを開発しました。これは一般化加法モデルをランキング問題に拡張したものです。
標準のGAMとは異なり、ニューラルランキングGAMは、ランク付けされたアイテムの特徴と現在の状況(検索キーワードやユーザープロファイルなど)の両方を考慮して、解釈可能なコンパクトなモデルを導出できます。
これにより、各アイテムレベルの特徴の寄与だけでなく、現在の状況の寄与も解釈できるようになります。 たとえば、次の図では、ニューラルランキングGAMを使用すると、ユーザーが検索に使用している機器と、距離、価格、および関連性がホテルの最終ランキングにどのように寄与するかがわかります。
ニューラルランキングGAMは、TF-Rankingの一部として利用できるようになりました。
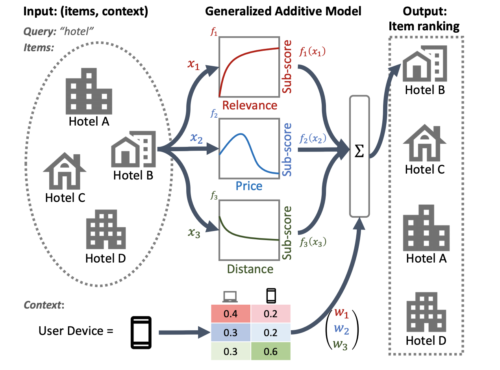
近隣検索にニューラルランキングGAMを適用する例
サブモデルは、入力特徴(価格、距離など)毎に、調査可能なサブスコアを生成し、透明性を提供します。状況に応じて(ユーザーの使っている機器など)、サブモデルの重要度の重みを導き出すことができます。
ニューラルランキング 対 勾配ブースティング
ニューラルモデルは様々な分野で最先端のパフォーマンスを達成していますが、LambdaMARTのような特殊な勾配ブースト決定木(GBDT:Gradient Boosted Decision Trees)を使った手法は、さまざまなオープンLTRデータセットを使ったコンペで良い成績を収める際に最も良く使われる手法のままでした。
オープンデータセットでのGBDTの成功は、いくつかの理由によるものです。まず、サイズが比較的小さいため、ニューラルモデルはこれらのデータセットに過剰適合する傾向があります。第2に、GBDTは決定木を使用して入力特徴表現空間を分割するため、ランキングデータの数値変動に対して当然、より回復力があります。
ただし、GBDTには、テキスト特徴表現と数値特徴表現の両方を組み合わせることが多い、より現実的なランキングが必要な場面には制限があります。たとえば、GBDTは、生のドキュメントテキストなどの大きな個別の特徴表現空間に直接適用することはできません。また、一般に、ニューラルランキングモデルよりも規模拡張性が低くなります。
したがって、TF-Rankingのリリース以来、私たちのチームは、数値的特徴表現を使用したランキングでニューラルモデルを活用する最善の方法についての理解を大幅に深めてきました。これは、ICLR 2021の論文で説明されているData Augmented Self-Attentive Latent Cross(DASALC)モデルで最高潮に達しました。
これは、オープンLTRデータセットで強力なライバルであるLambdaMARTに対するニューラルランキングモデルの同等性、場合によっては統計的に有意な改善を最初に確立したものです。
この成果は、データ拡張、ニューラル特徴変換、ドキュメントの相互作用をモデル化するための自己注意、リストごとのランキング損失、GBDTのブースティングと同様のモデルアンサンブルなどの手法の組み合わせによって可能になります。DASALCモデルのアーキテクチャは、TF-Rankingライブラリを使用して完全に実装されました。
結論
総論として、新しいKerasベースのTF-Ranking バージョンにより、ニューラルLTR研究の実施と、製品としての使用に耐えるランキングシステムの展開が容易になると考えています。
最新バージョンを試して、githubで公開されている紹介例に従って実践的な体験をすることをお勧めします。この新しいリリースに非常に興奮していますが、私たちの研究開発の旅はまだ終わっていないので、ランク付け学習の問題についての理解を深め、これらの進歩をユーザーと共有していきます。
謝辞
このプロジェクトは、TF-Rankingチームの現在および過去のメンバーの尽力によってのみ達成可能でした。Honglei Zhuang, Le Yan, Rama Pasumarthi, Rolf Jagerman, Zhen Qin, Shuguang Han, Sebastian Bruch, Nathan Cordeiro, Marc Najork そして Patrick McGregor。
また、Tensorflowチームの協力者であるZhenyu Tan, Goldie Gadde, Rick Chao, Yuefeng Zhou, Hongkun Yu, 及びJing Liにも特に感謝します。
3.BERTとTF-Rankingを使ってランキングシステムの透明性と解釈可能性を向上(2/2)まとめ
1)ai.googleblog.com
Advances in TF-Ranking
2)research.google
Are Neural Rankers still Outperformed by Gradient Boosted Decision Trees?
3)github.com
tensorflow / ranking

