
1.DALL-E2やStable Diffusion等の拡散モデルの動作原理と説明がつかない事まとめ
・拡散モデルは画像に加えたノイズを除去して元画像を復元する事を学習をする
・学習済モデルは純粋なノイズから画像を復元できるようになりこれが画像生成
・学習時のノイズはガウスノイズの必要があると思われていたがそうではなかった
2.拡散モデルの動作原理とは?
以下、twitterのTom Goldstein(@tomgoldsteincs)さんの拡散モデルの動作原理に関する投稿の意訳です。昨日の調査をしている際に見つけた一連のtweetでわかりやすくとても興味深い解説でした。
アイキャッチ画像はstable diffusion
#DALLEや#StableDiffusionのような拡散モデルは画像生成の最先端ですが、それらがどのようにして動作しているかの理解はまだ始まったばかりです。このスレッドでは、拡散モデルがどのように機能するか、それらがどのように理解されているのか、そしてこの理解が破綻していると私が考える理由を紹介します。

拡散モデルはガウスノイズだけではなく動物化ノイズ(animorphosis:ランダムな動物の顔をノイズとして顔に加える処理)でも問題なく動作します。これは、従来の拡散モデルに関する理論に反しています。
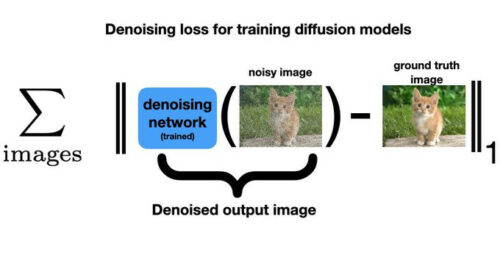
拡散モデルは強力な画像生成ツールですが、ガウス ノイズを追加して画像を劣化させる関数と、このノイズを除去するための単純な画像復元ネットワークという 2 つの単純な部品から構築されています。

きれいな画像にガウス ノイズを追加して、復元ネットワークのトレーニング データを作成します。モデルはノイズの多い画像を入力として受け入れ、ノイズを除去したクリーンな画像を出力します。
元の画像とノイズ除去された出力の間の L1 差を測定する損失を最小化することによってトレーニングします。
これらのノイズ除去ネットワークは非常に強力です。実際、それらは非常に強力なので、一連の単なる純粋なノイズ画像を渡しても、それを画像に復元します。
異なるノイズの並びを渡すたびに、異なる画像が返されます。これで、画像生成器ができました!
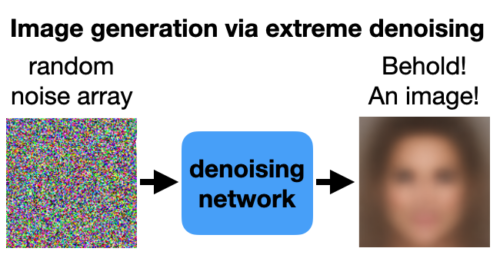
とはいえ、うーん…まあ…これは画像生成器…ですかね。
この生成器がうまく機能していないことに気付いたかもしれません。画像は本当にぼやけて見え、細部は見えません。しかしながら、L1 損失関数は重いノイズの除去には適していないため、この動作は予期されたものです。
以下が理由です。
モデルが重いノイズでトレーニングされると、(尖っている)先端部が画像内のどこにあるべきかを正確に判断できなくなります。間違った場所を先端部とすると、大きな損失が発生します。このため、あいまいな物体の境界を滑らかにし、細かい部分を削除することで、損失を最小限に抑える事をモデルは学習します。
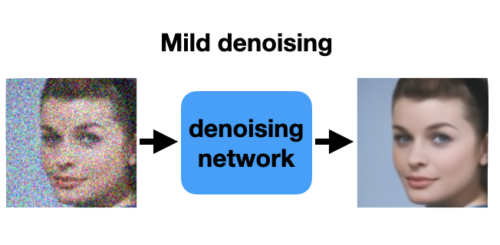
もちろん、この過剰に平滑化する度合は、トレーニング データのノイズの程度によって異なります。以下のようなマイルドなノイズ画像でトレーニングされたモデルは、物体の先端部がどこにあるかを正確に判断できます。シャープな先端部をぼかすのではなく復元することで、損失を最小限に抑えることを学習します。
では、どうすれば良い画像を生成できるのでしょうか?
まず、重いノイズを扱うモデルを使用して純粋なノイズをぼやけた画像に変換します。次に、このぼやけた画像を、シャープな画像を出力するマイルド ノイズ モデルに与えます。ただし、マイルド ノイズ モデルはノイズの多い入力を想定しているため、最初にぼやけた画像に更にノイズを追加します。
手順の詳細は次のとおりです。ノイズ除去モデルは純粋なノイズをぼやけた画像に変換します。次に、この画像にノイズを追加し、より低いノイズ レベルでトレーニングされたノイズ除去モデルに入力として与えます。
これにより、ぼやけの少ない画像が作成されます。ノイズを元に戻し、ノイズを除去します。そして何度もこれを繰り返します。
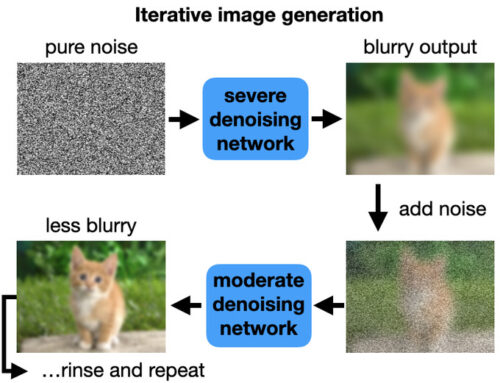
ノイズがゼロになるまで、ノイズレベルを徐々に下げてこのプロセスを繰り返します。これで、シャープな先端部と特徴を備えた洗練された出力画像が得られました。
この反復プロセスは、モデルがトレーニングされた Lp-norm損失の制限を回避します。

DALL-E や GLIDE、Stable Diffusion など、テキストの説明から画像を作成する創造的なモデルはどうでしょうか?
これらは同様のノイズ除去モデルを使用しますが、2 つの入力があります。トレーニング時に、通常どおり、クリーンなイメージを劣化させ、トレーニングのためにノイズ除去モデルに渡されます。
同時に、画像を説明する説明文が言語モデルを介して押し込まれ、embedded特徴に変換されます。これらは、ノイズ除去器への追加入力として提供されます。トレーニングと生成は以前と同じように進行しますが、ヒントを提供するテキスト入力があります。
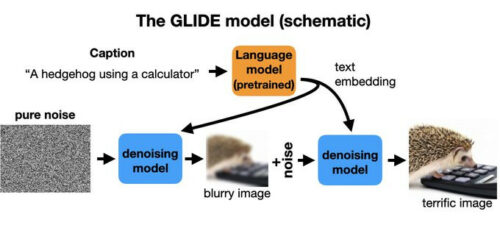
理論的には、拡散モデルはノイズを使用して画像分布を調査する方法として理解されます。ノイズ除去ステップは、ノイズの多い画像を取得し、画像密度関数の勾配上昇を使用して自然画像の多様性に近づけるための方法として解釈できます。
これらのノイズ除去ステップがノイズを追加するステップと交互になると、反復が画像分布の周りで跳ね返るランジュバン拡散(Langevin Diffusion)と呼ばれる古典的なプロセスが得られます。このプロセスが十分長く実行されると、反復は真の分布からのサンプルのように動作します。
では、なぜこの理解は破綻しているのでしょうか。拡散に関する既存の理論は、ガウス ノイズの特性(訳注:正規分布に従う)に大きく依存しています。また、「ホット」なノイズ フェーズから「コールド」な決定フェーズにゆっくりと押し進める画像生成器のランダム性の源も必要です。
しかし、私の研究室では最近、ノイズだけでなく、あらゆる画像劣化から生成モデルを構築できることを観察しました。これは、重い合成雪ノイズ(ImageNet-C から) を使用して画像を劣化させる例です。除雪と除雪を繰り返すことで、イメージを復元することができます。

合成雪ノイズと動物化ノイズ(上記)は面白い珍奇な例ですが、実務的には、ぼかし、ピクセル化、彩度の低下など、現実世界の画像の劣化を反転させるために拡散プロセスが必要になる場合があります。

これらの一般化された拡散処理はうまく機能しますが、既存のすべての拡散モデルに関する理論に違反しています。これらの理論は、その全てがガウス ノイズの使用に強く依存しています。上記のいくつかは、ランダム性をまったく必要としない「コールド」な拡散ですらあります。
Cold Diffusion https://arxiv.org/abs/2208.09392
付録: 詳細を知りたい場合は、拡散に関するトピックを扱った参考文献リストを参照してください。
画像生成のための反復ノイズ除去プロセス:
DDIM https://arxiv.org/abs/2010.02502
DDPM https://arxiv.org/abs/2006.11239
スコアマッチング https://arxiv.org/abs/2009.05475
Improved DDPM https://arxiv.org/abs/2102.09672
Image restoration https://arxiv.org/abs/2201.11793
拡散のためのニューラル アーキテクチャ:
Diffusion Models Beat GANs https://arxiv.org/abs/2105.05233
テキストから画像へのモデル:
分類器なしのガイダンス https://arxiv.org/abs/2207.12598
グライドモデル https://arxiv.org/abs/2112.10741
潜在拡散モデル https://arxiv.org/abs/2112.10752
理論的基礎:
Sohl-Dickstein らによる原論文 https://arxiv.org/abs/1503.03585
スコアベースのモデル https://arxiv.org/abs/2011.13456
データ分布の勾配 https://arxiv.org/abs/1907.05600
最後に、@arpitbansal297、@EBorgnia、Hong-Min Chu、Jie Li、@hamid_kazemi22、@furongh、@micahgoldblum、および@jonasgeiping
に感謝します。
余談
アイキャッチ画像をStable Diffusionに生成して貰う際に参照画像として与えた画像は実は以下です。

馬鹿な!

服の色以外、共通点は皆無ではないかーい!と思いましたが、純粋なノイズから画像を生成してしまうくらいの性能であればこんな事も不思議ではないのでしょうね。
以下、今日も500枚以上作って惜しいところまで来ている感はあるナウシカ画像をお楽しみください。全て、参照画像を与えた結果なので、詳しい方はどの場面か想像が出来るかもしれません。





実はクシャナ殿下の方が楽かもしれない説あります。鎧は正確でなくともそれっぽく見えるのと、おそらくネット上には鎧を描いた絵は沢山あります。
ナウシカの服装は帽子や腐海マスク等、人工知能にとっては未知で奇抜であり、肩の上のテトも惑わす原因となっているように見えます。
3.DALL-E2やStable Diffusion等の拡散モデルの動作原理と説明がつかない事関連リンク
1)twitter.com
@tomgoldsteincs

