
1.FRILL:TensorFlow-Liteを使用したオンデバイスで動作可能な音声特徴表現(2/2)まとめ
・FRILLはPixel 1スマートフォン上で推論時間8.5ミリ秒、TRILL比で40%のサイズ削減を達成
・10ミリ秒を超える応答速度では推論品質のパフォーマンス向上がより困難な事も判明
・量子化を意識したトレーニング、ボトルネックの圧縮、グローバル平均プーリングが貢献した
02.FRILLとTRILLの性能の違い
以下、ai.googleblog.comより「FRILL: On-Device Speech Representations using TensorFlow-Lite」の意訳です。元記事は2021年6月10日、Joel ShorさんとSachin Joglekarさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Michael Afonso on Unsplash
アーキテクチャの選択と最適化
応答速度と精度のバランスをとるために、さまざまなニューラルネットワークアーキテクチャと特徴表現を調査しました。パラメータが少ないモデルは通常、小さくて高速ですが、特徴表現力が低いため、一般的に有用でない特徴表現を生成します。
私達は144の異なるモデルをトレーニングしました。これらは全てMobileNetV3アーキテクチャに基づいていおり、様々なハイパーパラメータが設定されています。
(1)MobileNetV3のサイズと幅
MobileNetV3は、さまざまな環境で使用するためにさまざまなサイズでリリースされました。サイズは、使用したMobileNetV3アーキテクチャを示しています。幅は、アルファ(alpha)とも呼ばれ、各レイヤーのフィルターの数を比例して増減します。幅1.0は、元論文のフィルターの数に対応します。
(2)グローバル平均プーリング
MobileNetV3は通常、2次元の特徴表現マップのセットを生成します。
これらは平坦化され、連結されて、ボトルネック層に渡されます。ただし、このボトルネックは依然として大きすぎてすぐに計算できないことがよくあります。
私達はボトルネックレイヤーカーネルのサイズを削減しました。各出力の特徴表現マップのすべての「画素(pixels)」のグローバル平均を取得することによりこれを行いました。
私達の直感では、破棄された時間情報は、非意味的な音声特徴表現を学習するためにそれほど重要ではありません。これらの信号が時間の経過に関わらず安定しているという側面があるためです。
(3)ボトルネックの圧縮
生徒モデルの重みのかなりの部分がボトルネックレイヤーにあります。このレイヤーのサイズを縮小するために、ボトルネックの重み行列の低ランク近似を学習する特異値分解(SVD:Singular Value Decomposition)に基づく圧縮操作を適用します。
(4)量子化対応トレーニング
ボトルネック層にはほとんどのモデルの重みがあるため、量子化対応トレーニング(QAT:Quantization-Aware Training)を使用して、トレーニング中にボトルネックの重みを表現する数値の精度(桁)を徐々に下げます。QATを使用すると、トレーニングの終了後に量子化を導入した際にパフォーマンスを低下させる可能性がなく、トレーニング中にモデルをより低い精度に調整できます。
結果
Non-Semantic Speech Benchmark(NOSS)と2つの新しいタスクでこれらの各モデルを評価しました。話者がマスクを着用しているかどうかを検出する難しいタスクと、また、環境音分類データセット(Environment Sound Classification)のヒューマンノイズサブセットに含まれる「咳」や「くしゃみ」などです。
優れた代替モデルが存在するモデルを厳密に排除した後、品質対応答速度曲線に8つの「境界(frontier)」モデルが残ります。これらは、144モデルの中で、対応する品質しきい値または応答速度により高速で優れた代替案がなかったモデルです。以下に、これらの境界モデルのみ応答速度と品質の関係をグラフ化し、パフォーマンスが悪いモデルは無視します。
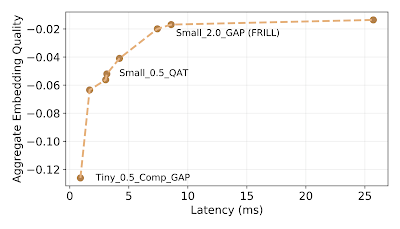
Embeddingの品質と応答速度のトレードオフの図
x軸は推論の待ち時間を表し、y軸はベンチマークデータセット全体で平均されたTRILLのパフォーマンスと精度の違いを示します。
FRILLは、最もパフォーマンスの高い10ミリ秒以下の推論モデルであり、Pixel 1スマートフォン上での推論時間は8.5ミリ秒(TRILLの約32倍高速)であり、TRILLの約40%のサイズでもあります。境界曲線は約10msの応答速度以降に平行になります。つまり、短い応答速度では、最小限の応答遅延コストではるかに優れた推論パフォーマンスが実現できますが、10msを超える応答速度では推論品質のパフォーマンスを向上させることはより困難です。
これは、私達の実験でハイパーパラメータを選択する際の支えとなります。FRILLのタスクごとのパフォーマンスを次の表に示します。
| FRILL | TRILL | |
| Size (MB) | 38.5 | 98.1 |
| Latency (ms) | 8.5 | 275.3 |
| Voxceleb1※ | 45.5 | 46.8 |
| Voxforge | 78.8 | 84.5 |
| Speech Commands | 81 | 81.7 |
| CREMA-D | 71.3 | 65.9 |
| SAVEE | 63.3 | 70 |
| Masked Speech | 68 | 65.8 |
| ESC-50 HS | 87.9 | 86.4 |
各分類タスクの精度(高いほど性能が良い値です)
※私たちの調査の結果は、内部プライバシーガイドラインに従ってフィルタリングされたVoxceleb1の小さなサブセットを使用しています。興味のある読者は、TensorFlowデータセットとオープンソース評価コードを使用して、完全なデータセットで調査を実行できます。
最後に、各ハイパーパラメータの相対的な寄与を評価します。私たちの実験では、
・量子化を意識したトレーニング
・ボトルネックの圧縮
・グローバル平均プーリング
により、結果のモデルの応答速度が最も短縮されたことがわかりました。同時に、ボトルネック圧縮は結果のモデルの品質を最も低下させましたが、プーリングはモデルのパフォーマンスを最も低下させませんでした。アーキテクチャの幅パラメータは、パフォーマンスの低下を最小限に抑えながら、モデルサイズを縮小する上で重要な要素でした。
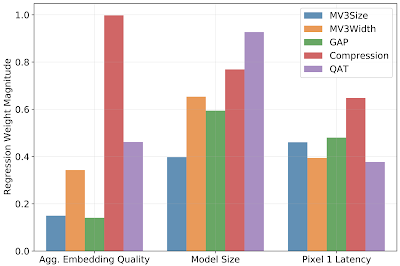
モデルの品質、応答時間、およびサイズを予測するための線形回帰の重みの大きさ。重みは、入力ハイパーパラメータを変更した場合に予想される影響を示します。重みの大きさが大きいほど、予想される影響が大きいことを示します。
私たちの研究は、音声機械学習研究のすべてのメリットをモバイルデバイスにもたらすための重要なステップです。また、パブリックモデル、対応するモデルカード、および評価コードを提供して、研究コミュニティがデバイス上の音声表現研究のためのさらに多くのアプリケーションを責任を持って開発できるようにします。
謝辞
論文の共著者であるJacob Peplinksi, Jake Garrison, そしてShwetak Patelに感謝します。このプロジェクトの技術サポートを提供してくれたAren Jansen、モデルのオープンソース化を支援してくれたFrançoise Beaufays、Tulsee Doshi、およびlogistical supportを提供してくれたGoogle Research Tokyoに感謝します。
3.FRILL:TensorFlow-Liteを使用したオンデバイスで動作可能な音声特徴表現(2/2)関連リンク
1)ai.googleblog.com
FRILL: On-Device Speech Representations using TensorFlow-Lite
2)arxiv.org
FRILL: A Non-Semantic Speech Embedding for Mobile Devices
3)github.com
google-research/non_semantic_speech_benchmark/distillation/
4)tfhub.dev
nonsemantic-speech-benchmark/frill

