
1.Apollo:コンピュータアーキテクチャのために機械学習を活用(2/3)まとめ
・本調査ではアーキテクチャ探索を4つの最適化戦略で実施して結果を比較した
・ランダム探索はランダムに、Vizierはベイズ最適化を用いて探索と開拓のバランスを取った
・進化的探索はアクセラレータ構成を遺伝子とし、P3BOは複数手法のアンサンブルを使用
2.4つのアーキテクチャ探索最適化戦略
以下、ai.googleblog.comより「Machine Learning for Computer Architecture」の意訳です。元記事の投稿は2021年2月4日、Amir Yazdanbakhshさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Brian McGowan on Unsplash
次の図は、ターゲットとなるMLアクセラレータの全体的なアーキテクチャ探索スペースを示しています。
アクセラレータには、処理要素(PE:processing elements)の2D配列が含まれています。それぞれは、単一命令複数データ(SIMD:Single Instruction Multiple Data)方式で一連の算術計算を実行します。各PEの主要なアーキテクチャコンポーネントは、SIMD操作用の複数の計算レーンを含むプロセッシングコアです。
各PEは、全てのコンピューティングコア間で共有されるメモリ(PEメモリ)があります。これは主にモデルのアクティブ化、部分的な結果、および出力を格納するために使用されますが、個々のコアは主にモデルパラメータを格納するために使用されるメモリを備えています。
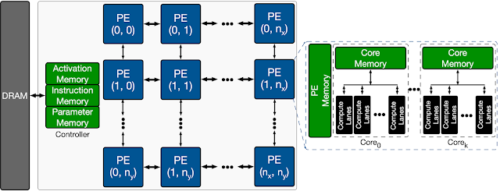
アーキテクチャ探索に使用されるテンプレートベースのMLアクセラレータの概要
最適化戦略
この調査では、アーキテクチャ探索を4つの最適化戦略で実施しました
(1)ランダム(Random):アーキテクチャ検索スペースをランダムに均一にサンプリングします。
(2)Vizier(訳注:辞書引く限り「イスラム王朝における「宰相」「大臣」などを意味するアラビア語」らしいのですが、製品名と思います。Google Cloud Platformで提供されているAI PlatformサービスにVizierというハイパーパラメータの調整を支援するブラックボックス最適化サービスがあります):目的関数の評価に費用がかかる探索空間(例えば、完了までに数時間かかる可能性のあるハードウェアシミュレーション)での探索にベイズ最適化を使用します。探索空間からサンプリングされた点のコレクションを使用して、ベイズ最適化は代理関数を形成します。これは通常、探索空間の多様体を近似するガウス過程で表されます。
代理関数の値に基づいて、ベイズ最適化アルゴリズムは、探索(exploration)と開拓(exploitation)のトレードオフを決定します。つまり、多様体の有望な領域からより多くをサンプリングするか(開拓)、探索空間のまだ見ぬ領域からより多くをサンプリングするか(探索)です。
次に、最適化アルゴリズムは、これらの新しくサンプリングされたポイントを使用し、代理関数をさらに更新して、ターゲットの探索空間をより適切にモデル化します。Vizierは、期待される改善をコア取得関数として使用しています。
(3)進化的(Evolutionary):k個体の母集団を使用して進化的探索を実行します。各個体のゲノムは、離散化されたアクセラレータ構成のシーケンスに対応します。新しい個体は、トーナメント選択を使用して母集団から2人の親を個体ごとに選択し、ゲノムをある程度のクロスオーバー率で再結合し、再結合したゲノムをある程度の確率で突然変異させることによって生成されます。
(4)母集団ベースのブラックボックス最適化(P3BO:Population-based black-box optimization):進化的およびモデルベースを含む最適化手法のアンサンブルを使用します。これにより、サンプルの効率と堅牢性が向上することが示されています。
サンプリングされたデータは、アンサンブル内の最適化手法間で交換され、オプティマイザーは、パフォーマンス履歴によって重み付けされて、新しい構成を生成します。私達の研究では、オプティマイザーのハイパーパラメーターが進化的探索を使用して動的に更新されるP3BOの変種を使用します。
アクセラレータ探索空間のEmbeddings
アクセラレータ探索空間を探索する際の各最適化戦略の有効性をより適切に視覚化するために、t-SNE(t-distributed stochastic neighbor embedding)を使用して、探索された最適化構成を2次元空間にマッピングします。
全ての実験目的(報酬)は、アクセラレータ領域毎のスループット(推論/秒)として定義されます。下の図で、x軸とy軸は、Embeddings空間のt-SNEコンポーネント(embedding1とembedding2)を示しています。星印と円形のマーカーは、それぞれ、実行不可能な(報酬がゼロ)および実行可能な設計ポイントを示し、実行可能なポイントのサイズはそれらの報酬に対応します。
予想どおり、ランダム戦略は均一に分散された方法で空間を検索し、最終的には設計空間で実行可能なポイントをほとんど見つけません。
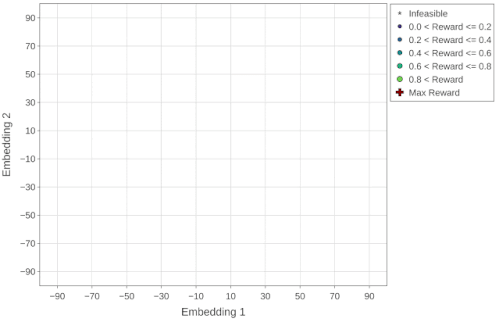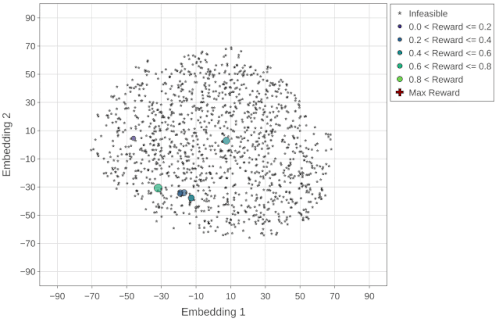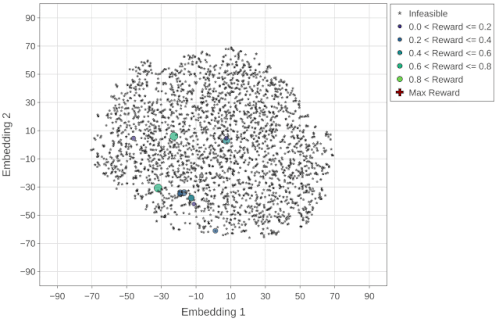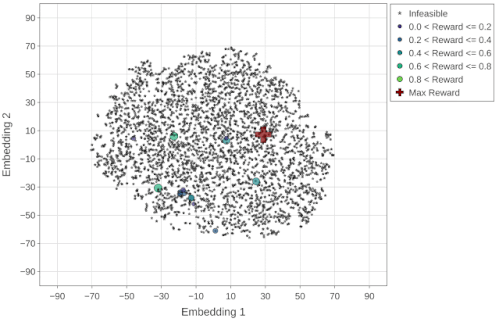
ランダム最適化戦略(最大報酬=0.96)によって探索された設計ポイント(~4K)のt-SNE視覚化。最大報酬ポイント(赤十字マーカー)は、アニメーションの最後のフレームで強調表示されます。
3.Apollo:コンピュータアーキテクチャのために機械学習を活用(2/3)関連リンク
1)ai.googleblog.com
Machine Learning for Computer Architecture
2)arxiv.org
Apollo: Transferable Architecture Exploration
