
1.Big Transfer(BiT):視覚タスクで大規模な事前トレーニングを活用(3/3)まとめ
・標準的な視覚タスクベンチマークでBiT-Lを評価し少数セット設定でなくとも効果的である事が判明
・タスク毎にハイパーパラメータを調整をせずBiT-HyperRuleでハイパーパラメータを設定した
・学習済みモデルも公開されておりImageNetの便利な代替手段としてBiTモデルを利用可能
2.ObjectNetを使った評価
以下、ai.googleblog.comより「Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision」の意訳です。元記事の投稿は2020年5月21日、Lucas BeyerさんとAlexander Kolesnikovさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by michael schaffler on Unsplash。
Oxford PetsやOxford Flowers、CIFARなどのいくつかの標準的なコンピュータービジョンベンチマークでBiT-Lを評価しました。これにより微調整時にある程度の量のデータが利用可能な場合でも、大規模な事前トレーニングを行ってシンプルに転移するこの戦略が効果的である事が示されました。
全てのベンチマークで、BiT-Lは最先端のスコアと同等、またはそれを上回るスコアを出しました。
最後に、BiTをRetinaNetのバックボーンとして使用し、MSCOCO-2017検出タスクで性能を評価しました。こういった構造化出力タスクでも、大規模な事前トレーニングがかなり役立つ事が確認できました。
| BiT-L | Generalist SOTA | |
| ILSVRC-2012 | 87.54 ± 0.02 | 86.4 |
| CIFAR-10 | 99.37 ± 0.06 | 99 |
| CIFAR-100 | 93.51 ± 0.08 | 91.7 |
| Pets | 96.62 ± 0.23 | 97.1 |
| Flowers | 99.63 ± 0.03 | 97.7 |
| Backbone | Pre-training | AP |
| ResNeXt-101 | ILSVRC-2012 | 40.8 |
| BiT-S | ILSVRC-2012 | 41.7 |
| BiT-M | ImageNet-21k | 43.2 |
| BiT-L | JFT-300M | 43.8 |
上図:様々な標準的な視覚タスクベンチマークで従来の汎用最先端モデルとBiT-Lの精度を比較
下図:MSCOCO-2017でRetinaNetのバックボーンとしてBiTを使用した場合の平均精度(AP)
検証した全ての異なる下流タスクにおいて、タスク毎にハイパーパラメータを調整を実行せず、BiT-HyperRuleに頼ってハイパーパラメータを設定した事が非常に重要です。
論文で示したように、十分に大きな検証データでハイパーパラメーターを調整することで、更に良い結果を得ることができます。
ObjectNetを使った評価
更に困難なシナリオでBiTの堅牢性を評価するために、最近発表されたObjectNetデータセットでILSVRC-2012で微調整したBiTモデルを評価します。
このデータセットは、物体が様々な視点、回転状態、変則的な状況で出現するため、現実世界で起こり得るシナリオに良く似ています。
興味深いことに、BiT-Lモデルは80.0%という前例のないtop-5精度を達成しました。これは従来の最先端技術よりもほぼ25%の絶対的改善で、データとアーキテクチャの規模を拡大するのメリットが更に明白となりました。
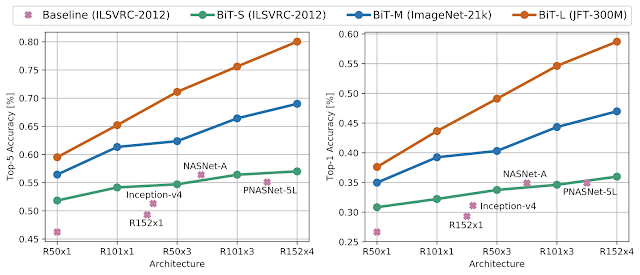
ObjectNetによるBitの評価の結果
左:top-5の精度、右: top-1精度
まとめ
大量の一般的な画像データを使って事前トレーニングしたシンプルな転移学習戦略が、印象的な結果につながることを示しました。微調整用に大規模なデータセットが利用可能なタスクでも、クラスごとに1つしかイメージが無い程非常にデータ少ないタスクでもパフォーマンスを高める事が可能です。
ImageNet-21kで事前トレーニングしたR152x4のBiT-Mモデルを、Jax、TensorFlow2、およびPyTorchで転移を行うcolabsとともにリリースしました。コードのリリースに加えて、BiTモデルの使用方法に関するTensorFlow2を用いたチュートリアルもblog.tensorflow.orgで紹介しています。
機械学習の実践者や研究者が、従来使用されてきたImageNetの事前トレーニング済みモデルの便利な代替手段としてBiTモデルを見出す事を希望しています。
謝辞
BiTの論文を共同執筆し、その開発の全ての面に携わったXiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly 及び Neil Houlsbyに加えて、チューリッヒのGoogle Brainチームに感謝します。また、入力パイプラインのデバッグに力を貸してくれたAndrei Giurgiuにも感謝します。 このブログ記事で使用されているアニメーションを作成してくれたTom Smallに感謝します。
最後に、本研究に関心をもった読者に関連する2つのアプローチを紹介します。Google Researchの同僚が行った「Self-training with Noisy Student improves ImageNet classification」、及び本研究と非常に関連性の高いFacebook Researchによる「Exploring the Limits of Weakly Supervised Pretraining」です。
3.Big Transfer(BiT):視覚タスクで大規模な事前トレーニングを活用(3/3)関連リンク
1)ai.googleblog.com
Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision
2)arxiv.org
Big Transfer (BiT): General Visual Representation Learning
Group Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Weight Standardization
Self-training with Noisy Student improves ImageNet classification
Exploring the Limits of Weakly Supervised Pretraining
3)www.image-net.org
Large Scale Visual Recognition Challenge 2012 (ILSVRC2012)
4)objectnet.dev
ObjectNet
5)github.com
google-research/big_transfer
6)blog.tensorflow.org
BigTransfer (BiT): State-of-the-art transfer learning for computer vision


コメント