
1.MaX-DeepLab:デュアルパストランスフォーマーを使ってパノプティックセグメンテーションを直接実行(1/2)まとめ
・パノプティックはセマンティックとインスタンスの両セグメンテーションを統合したもの
・従来の最高手法は画像から直接求めるのではなく段階的にパノプティックを算出した
・MaX-DeepLabはTransformerを使う事でクラスラベル付きマスクを直接予測する事が可能
2.MaX-DeepLabとは?
以下、ai.googleblog.comより「MaX-DeepLab: Dual-Path Transformers for End-to-End Panoptic Segmentation」の意訳です。元記事の投稿は2021年4月21日、Huiyu WangさんとLiang-Chieh Chenさんによる投稿です。
パノプティック(panoptic)は「総括的な」とも訳せますが、要は「すべてが一目で見渡せる」の意でパノラマ写真のPanoramaと通じているらしいので、アイキャッチ画像は(横が見切れてしまうのであまりわかりませんが)イギリスの風景を撮ったパノラマ写真でクレジットはPhoto by Raphael Andres on Unsplash
パノプティックセグメンテーションは、セマンティックセグメンテーション(画素単位で種別を表すクラスラベルを割り当てる。個々の実体は区別しないが、画素レベルでマスクするため境界は細かい)とインスタンスセグメンテーション(各実体を検出して画面内の位置を特定する。境界ボックス等を使う為に境界指定は粗い)を統合するコンピュータービジョンタスクです。
実世界で役立つアプリケーションを実現する際の主要タスクであるパノプティコンセグメンテーションは、重複しないマスクのセットを、対応するクラスラベル(つまり、「車」、「信号機」、「道路」などの物体のカテゴリ)とともに予測します。
そして、一般的に、パノラマセグメンテーションの目標を近似する複数の代替サブタスク(例えば、ボックス検出方法)を使用する事で実現されます。

Cityscapesデータセットのサンプル画像とそのパノプティックセグメンテーションマスク
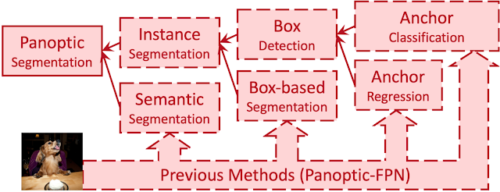
従来の手法は、代替サブタスクをツリー形状に段階的に実行する事でパノプティックセグメンテーションを近似していました。
この代替タスクツリー上の各代替サブタスクは、「アンカーデザインルール(anchor design rules)」、「ボックス割り当てルール(box assignment rules)」、NMS(Non-Maximum Suppression、同じ実体に複数の境界ボックスが割り当てられた際に1つのボックスにまとめる処理)、モノのマージ(thing-stuff merging、人や物などの実体のあるモノと空や地面などの実体のないモノを同じように扱えるようにする処理)など、手動設計された追加作業を行います。
個々の代替サブタスクとモジュールは個別のタスクとして実行するのであれば優れた結果を出せます。しかし、これらのサブタスクがパノプティコンセグメンテーションを実現するためのパイプラインとして実行されると、特に困難な状況で、望ましくない人工物(artifacts)が入り込んでしまいます。(例えば、似た境界ボックスを持つ2人に対してNMSが実行されると一方のマスクは失われてしまいます)。
DETRなどの以前の取り組みでは、ボックス検出サブタスクを段階的操作ではなく直接操作に単純化することでこれらの問題のいくつかを解決しようとしました。これにより、計算効率が向上し、不要な人工物が少なくなります。
ただし、トレーニングプロセスは依然としてボックス検出機能に大きく依存しており、パノプティコンセグメンテーションのマスクベースの定義と一致していません。
別の従来手法では、パイプラインから境界ボックスを完全に削除します。これには、関連するモジュールとそれが生み出す人工物とともに代替サブタスク全体を削除できるという利点があります。
例えば、Axial-DeepLabは、事前定義された「実体の中心」から画素単位で境界線を予測しますが、高度に変形可能な物体(例:猫など)や物体同士の中心が近くにある際(例:数の椅子に座っている犬)に課題に直面します。

犬と椅子の中心が互いに近い場合、Axial-DeepLabはそれらを1つの物体として併合して認識してしまいます。
CVPR 2021で発表される「MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers」では、パノプティコンセグメンテーションパイプラインの初の完全直接実行(End-to-End)アプローチを提案します。
Transformerアーキテクチャをこのコンピュータビジョンタスクに拡張することにより、クラスラベル付きマスクを直接予測します。
Mask Xformerを使用してAxial-DeepLabを拡張するため、MaX-DeepLabと呼ばれるこの手法では、グローバルメモリパスを導入するデュアルパスアーキテクチャを採用し、任意の畳み込み層との直接通信を可能にします。その結果、MaX-DeepLabは、困難なCOCOデータセットのボックスフリーレジームで7.1%のパノプティック品質(PQ:Panoptic Quality)の大幅な向上を示し、ボックスベースの手法とボックスを使わない手法のギャップを初めて埋めました。MaX-DeepLabは、テスト時間を追加する事なしに、COCOテスト開発セットで最先端の51.3%PQを達成します。
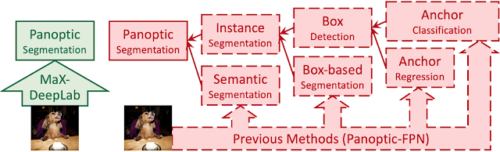
MaX-DeepLabは段階的に処理されるのではなく、完全に直接実行されます。画像から直接パノプティックセグメンテーションマスクを予測します。
エンドツーエンドで実行されるパノプティコンセグメンテーション
DETRに触発されて、私たちのモデルは、重複しないマスクのセットとそれに対応するセマンティックラベルを直接予測します。具体的にはPQを向上する目的で最適化された出力マスクとクラスを使用します。
このアイディアは、「認識品質(予測されたクラスが正しいかどうか)」に「セグメンテーション品質(予測されたマスクが正しいかどうか)」を掛けたものとして定義される評価基準であるPQに触発されました。これとまったく同じ方法で、2つのクラスラベル付きマスク間の類似性基準を定義します。
モデルは、真のマスクと予測マスクの間のこの類似性を1対1のマッチングによって最大化することにより、直接トレーニングされます。パノプティコンセグメンテーションのこの直接モデリングにより、エンドツーエンドのトレーニングと推論が可能になり、既存のボックスベースおよびボックスフリーの手法では必要になる手作業でコーディングされた事前情報が不要になります。
MaX-DeepLabは、CNNとマスクトランスフォーマーを使用して、N個のマスクとN個のクラスを直接予測します。
3.MaX-DeepLab:デュアルパストランスフォーマーを使ってパノプティックセグメンテーションを直接実行(1/2)関連リンク
1)ai.googleblog.com
MaX-DeepLab: Dual-Path Transformers for End-to-End Panoptic Segmentation
2)arxiv.org
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers

