
1.Axial-DeepLab:パノプティックセグメンテーション用にattentionを改良(1/2)まとめ
・CNNは局所的であり大域的な空間関係を把握する必要があるモデリングは困難
・axial-attentionはattentionを2ステップに分け縦軸と横軸にattentionを適用する手法
・このアプローチの効率性により広い領域にattentionを向けることができるようになる
2.axial-attentionとは?
以下、ai.googleblog.comより「Axial-DeepLab: Long-Range Modeling in All Layers for Panoptic Segmentation」の意訳です。元記事の投稿は2020年8月26日、Huiyu WangさんとYukun Zhuさんによる投稿です。
Axialは軸の意味ですが、格子状の絵はあまり面白みがなかったので、線路の画像をアイキャッチ画像に選んだのですが、軸に沿って遠くにAttentionを届けるイメージで割と良い画像なのではないかと自画自賛です。クレジットはPhoto by Dan Dennis on Unsplash
2021年4月追記)後続研究であるMaX-DeepLabが発表されています。
畳み込みニューラルネットワーク(CNN:convolutional neural networks)の成功は、主に畳み込みの2つの特性によります。つまり畳み込み処理の同変性(equivariance)と局所性(locality)に由来します。
同変性は厳密ではありませんが、モデルが画像内の異なる位置にある物体や異なるサイズの画像に対して適切に機能することを保証します。
局所性は効率的な計算を保証します。しかし、大きな画像のパノプティックなセグメントは局所的ではなく、大域的な空間関係な空間関係を把握する必要があるため、モデリングが困難になってしまういう犠牲を伴います。
例えば、大きな物体を切り出すためには、物体の形状をモデリングする必要があります。大きな物体は、非常に大きな画素領域を占めている可能性があり、物体の切り出しに役立つ可能性のある情報は、遠く離れた画素が持っている可能性があります。
このような場合、畳み込みカーネルから離れた画素の持つ情報をモデルに通知できないと、パフォーマンスに悪影響を与える可能性があります。沢山の研究が、局所性の制限を解決し、CNNで大域的な相互作用を可能にするアプローチを論じてきました。
受容野(receptive field、畳み込み処理の入力となる画像領域)をいくらか拡大するアトロス畳み込み(atrous convolutions)、またはイメージピラミッドを採用しているものもありますが、それでも小さな局所的領域に限定されます。
別の研究方針では、self-attentionのメカニズムを採用しています。例えば、局所的な畳み込みとは対照的に、受容野が入力画像全体をカバーできるようにする非局所的ニューラルネットワークなどです。残念ながら、このようなアプローチは、特に大きな入力の場合、計算コストがかかります。
最近の研究によれば、完全なattentionモデルを構築できますが、非局所的ニューラルネットワークに局所制約を適用するという犠牲が伴います。これらの制限は、特に高解像度画像などでセグメンテーションを行う際に有害となるような受容野を持つようにモデルを制限してしまいます。
最近のECCV 2020の論文「Axial-DeepLab:Stand-Alone Axial-Attention for Panoptic Segmentation」では、完全attentionモデルで大きな受容野を回復するaxial-attention(またはcriss-cross attention)を採用することを提案します。
中心となるアイデアは、二次元のattentionを2つのステップに分け、縦軸と横軸に一次元のattentionを順番に適用することです。
このアプローチの効率性により、広い領域にattentionを向けることができ、広い範囲、または大域的に相互作用を学習するモデルも可能になります。
さらに、self-attentionモジュールの新しい定式化を提案します。このself-attentionモジュールは、わずかなコストで、大きな受容野に存在する関連情報の位置に対してより敏感に反応できます。
Panoptic-DeepLabに適用することにより、パノプティックセグメンテーションを使って位置に敏感なaxial-attentionを評価しました。Panoptic-DeepLabは、パノプティックセグメンテーションのためのシンプルで効率的な手法です。
私達のモデルの有効性は、ImageNet、COCO、Cityscapesで実証されています。Axial-DeepLabは、パノプティックセグメンテーションとセマンティックセグメンテーションに関する最先端の結果を達成し、Panoptic-DeepLabを大幅に上回っています。
Axial-Attentionの構造
Axial-DeepLabは、Axial-ResNetのバックボーンとPanoptic-DeepLabの出力ヘッドで構成され、パノプティックセグメンテーションを結果として生成します。
私達のAxial-ResNetはResNetアーキテクチャに基づいて構築されており、ResNetのボトルネックブロック内の全ての3 x 3の局所的な畳み込みが、今回提案する大域的な位置に敏感なaxial-attentionによって置き換えられるため、大きな受容野と正確な位置情報の両立が可能になります。
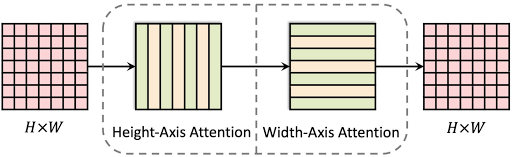
axial-attentionブロックは、縦方向と横方向の両軸に沿って順番に動作する、2つの位置に敏感なaxial-attentionレイヤーで構成されます。
Axial-DeepLabの縦方向のaxial-attentionレイヤーは、1次元のself-attentionを大域的に提供し、個々の列内に情報を伝播します。しかし、列間では情報は伝播しません。2番目の一次元アテンションレイヤーが横方向に動作するため、列と行の両方の情報を取得できます。
この分離により、self-attentionの複雑さが二次元(2D)から線形(1D)に減少します。
これにより、すべてのレイヤーではるかに大きな(従来の3×3に対して65×65)、または大域的な情報を使用することが可能になり、パノプティックセグメンテーションにおける広範囲モデリングが実現されます。
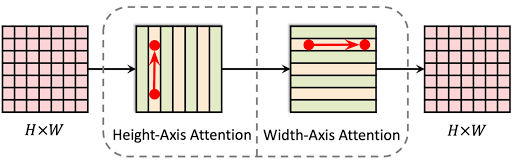
メッセージは2ステップで大域的に伝える事ができます。
(x1, y1)のメッセージまたは特徴表現ベクトルは、常に二次元平面上の任意の位置(x2, y2)に大域的に伝える事ができます。高さ軸に1回移動し(x1, y1 → x1, y2)、幅軸にもう一回移動(x1, y2 → x2, y2)を行う事で達成できます。
このようにして、1つの残差ブロックで二次元の長距離関係をモデル化できます。このaxial-attentionの設計により、複雑さが2次から線形に削減され、モデルのすべての層で大域的な受容野が可能になります。
3.Axial-DeepLab:パノプティックセグメンテーション用にattentionを改良(1/2)関連リンク
1)ai.googleblog.com
Axial-DeepLab: Long-Range Modeling in All Layers for Panoptic Segmentation
2)arxiv.org
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Stand-Alone Self-Attention in Vision Models

