1.画素レベルの画像認識を実現するDeepLab-v3+が公開まとめ
・画素レベル(semantic image segmentation)の画像認識ができるDeepLab-v3+が公開
・従来の境界ボックスレベルより厳密に境界特定が出来るので応用範囲が広い
・スマホ写真の背景を変えるアプリも同様な技術を応用したものである
2.Semantic image segmentationとは?
2020年2月追記:Open ImageV6データセットの登場の際には「Semantic image segmentation」は「Instance segmentation」という表記になっており、後者の方が主流の呼び方になっていると思います。
2020年7月追記:すいません、こちら間違っていました。「Semantic image segmentation」と「Instance segmentation」は別物です。
「Instance segmentation」は「実体のセグメンテーション」であり、実体を区別します。↓のbounding box-level segmentationも実体を区別しているので「Instance segmentation」の一種になります。しかし、↓のSemantic image segmentationを見ての通り、Semantic segmentationは個々の実体を区別せず「人が写っている画素」であるかどうかのみを判別します。
この辺りは「Panoptic-DeepLab:総括的に風景を理解する新手法(1/2)」に詳しいです。また、人工知能/機械学習関連用語集の方にも整理しています。
人工知能による画像認識、つまり画像に写っている物体が何なのかを特定する性能は近年大きな進化を遂げているが、境界の認識は四角形で囲まれた境界ボックスレベル(bounding box-level)に留まっていた。
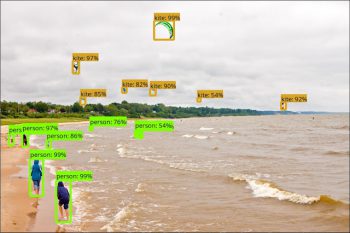
しかし、近年は画素レベルで境界を特定する技術の発展が目覚ましい。既に紹介したスマホのリアルタイムレンダリングも同様な技術で、物体をピクセル単位で特定できたために実現した機能。今回、画像に写っている物体の画素単位での特定(semantic image segmentation model)を実現するDeepLab-v3+がTensorFlowのライブラリとしてオープンソースで公開された。同時にオープンデータで学習済みのモデルも公開されている。

DeepLab-v3+は、3年前に開発されたDeepLabに数々の改良を施し、改良された畳み込みニューラルネットワークとencoder-decoder手法により、画素単位での特定に成功している。
3.Semantic image segmentationの日本語訳の難しさ
英語だと「Semantic Image Segmentation」なのですが、直訳すると「意味による画像分割」となります。「境界ボックス単位ではなく個々の画素の示す意味を理解し、意味単位で分割している」って事だと思うのですが、説明が非常にわかりにくくなるので「画素単位での画像分割」としました。良い日本語訳があればコメント頂ければと思います。
4.画素レベルの画像認識を実現するDeepLab-v3+が公開関連リンク
1)research.googleblog.com
Semantic Image Segmentation with DeepLab in TensorFlow
Supercharge your Computer Vision models with the TensorFlow Object Detection API
2)github.com
models/research/deeplab/

