
1.arxiv.orgの人工知能の論文を分類したい(5)
・Computer Vision and Pattern Recognitionの概要に対象を絞って単語の数を数えてみる
・sklearn.feature_extraction.textやNLTKを使うと楽だがそれでも個別の精査は必要
・エルボー法で確かめてみるとそれなりに有効そうである事がわかった
2.arxiv.orgからクロールした2017年12月登録論文の出現キーワードランキング
前回の調査で論文の規模感がかなり異なる事がわかったので、PDFの中身ではなく、arxivの論文詳細ページにある概要(Abstract)を対象にしてみる事にした。概要は論文内容を説明した文章で、長さがほぼ同じ。また、PDFのように画像として貼られていて文字が抽出できない事もないので想定外の片寄を減らせるだろうとの予測。
下記が何のツールも使わない単純単語出現数上位100位ランキングの結果
|
No |
word | 出現回数 | 注目 |
| 1 | the | 4517 | |
| 2 | of | 3018 | |
| 3 | and | 2601 | |
| 4 | a | 2328 | |
| 5 | to | 2218 | |
| 6 | in | 1325 | |
| 7 | for | 1256 | |
| 8 | is | 1114 | |
| 9 | on | 953 | |
| 10 | that | 940 | |
| 11 | we | 802 | |
| 12 | with | 796 | |
| 13 | We | 586 | |
| 14 | this | 585 | |
| 15 | by | 546 | |
| 16 | from | 543 | |
| 17 | are | 522 | |
| 18 | as | 502 | |
| 19 | image | 479 | ◎ |
| 20 | The | 475 | |
| 21 | an | 446 | |
| 22 | In | 432 | |
| 23 | can | 410 | |
| 24 | our | 409 | |
| 25 | which | 369 | |
| 26 | network | 352 | |
| 27 | be | 346 | |
| 28 | using | 334 | |
| 29 | proposed | 331 | |
| 30 | learning | 327 | |
| 31 | method | 319 | |
| 32 | images | 318 | ◎ |
| 33 | propose | 287 | |
| 34 | model | 287 | |
| 35 | data | 279 | |
| 36 | training | 262 | |
| 37 | deep | 252 | ◎ |
| 38 | results | 248 | |
| 39 | show | 247 | |
| 40 | neural | 243 | ◎ |
| 41 | based | 227 | |
| 42 | methods | 225 | |
| 43 | performance | 221 | |
| 44 | different | 206 | |
| 45 | detection | 201 | |
| 46 | This | 200 | |
| 47 | 3D | 198 | ◎ |
| 48 | approach | 197 | |
| 49 | or | 196 | |
| 50 | have | 193 | |
| 51 | at | 190 | |
| 52 | also | 188 | |
| 53 | state-of-the-art | 186 | ◎ |
| 54 | novel | 180 | ◎ |
| 55 | two | 179 | |
| 56 | such | 179 | |
| 57 | it | 179 | |
| 58 | has | 175 | |
| 59 | not | 174 | |
| 60 | Our | 170 | |
| 61 | object | 164 | |
| 62 | new | 162 | |
| 63 | classification | 162 | |
| 64 | used | 160 | |
| 65 | both | 159 | |
| 66 | convolutional | 157 | ◎ |
| 67 | networks | 156 | |
| 68 | video | 152 | ◎ |
| 69 | between | 152 | |
| 70 | features | 150 | |
| 71 | paper | 146 | |
| 72 | segmentation | 145 | |
| 73 | problem | 143 | |
| 74 | more | 143 | |
| 75 | these | 139 | |
| 76 | information | 139 | |
| 77 | demonstrate | 138 | |
| 78 | Deep | 132 | |
| 79 | To | 131 | |
| 80 | adversarial | 128 | ◎ |
| 81 | than | 127 | |
| 82 | dataset | 127 | |
| 83 | visual | 124 | |
| 84 | Learning | 124 | |
| 85 | models | 122 | |
| 86 | been | 121 | |
| 87 | large | 120 | |
| 88 | over | 119 | |
| 89 | only | 119 | |
| 90 | A | 119 | |
| 91 | framework | 118 | |
| 92 | existing | 118 | |
| 93 | use | 117 | |
| 94 | each | 117 | |
| 95 | However | 116 | |
| 96 | recognition | 115 | |
| 97 | trained | 114 | |
| 98 | feature | 114 | |
| 99 | input | 113 | |
| 100 | semantic | 112 |
まず真っ先に目を引いたのは53位、「state-of-the-art(最先端の)」。君等、この表現好きすぎだろっと笑ってしまったけど、確かに人工知能関連では色々な箇所で見る表現ではある。TensorFlowのチュートリアルなどでも、「ここで学ぶ事はstate-of-the-artではないけれども~」と書いてあって、チュートリアルでそんな高度な事を期待する人なんていないだろ!と一人突っ込みしたのも思い出す。
上位陣はいわゆる一般的な英単語、どんな文章でも出てくるだろうからこれらは特徴量とは言えない。sklearn.feature_extraction.textを利用すると一括で省けるようになるのだけど、省けない単語もあるので結局は一つ一つ見る事が必要になってくる。
19のimageと32のimagesは、同じ単語だけど、これらはNLTK(Natural Language ToolKit)を使うとステミング(stemming)と言って、語形の変化をまとめてくれるそうなのだけど、こちらも専門的な言い回しが多いせいなのか100%ではなく細かく見る必要がありそう。
しかし、例えばdeepとかneuralは、人工知能関連文書とそうでない文書をわけるためには有効と思うけど、人工知能関連の論文のクラスタリングには有効でない気もする。また、例えばframeworkは違いが出そうな気はするけど、論文をクラスタリングと言う意味ではTensorFlowだろうがChainerだろうが、実行ツールの違いで研究内容には関係はない気がする。などなど、500強の論文に対して700以上の単語を当初は細かく見ていたが、段々と混乱してきて面倒になり、エイヤと目をつぶって削除して特徴量50をMAXとしてエルボー法を適用したのが下記。
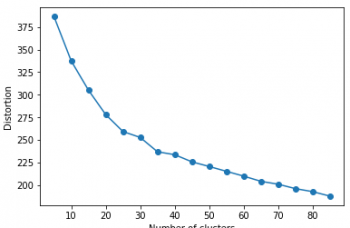
初回の何も考えずに単語カウントしてsklearnに突っ込んだのが下記。
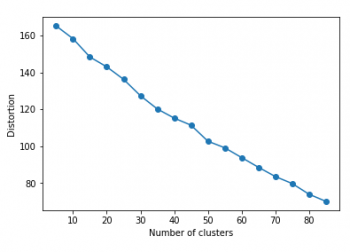
おぉ~、明らかに20クラスタ近辺までグッと下がってエルボー(肘)っぽい形に少し近づいた。って事はこれは丁寧に単語を見る価値はありそう。

コメント