
1.Menger:大規模な分散型強化学習(3/3)まとめ
・Reverbが提供する水平分割機能を使用して通信スループットを向上させた
・Mengerは複数のBorgセルにまたがる数千人の行為者に効率的に拡張できた
・大規模チップ配置タスクにおいて既存手法の所要時間8.6時間を1時間に短縮できた
2.Mengerの性能
以下、ai.googleblog.comより「Massively Large-Scale Distributed Reinforcement Learning with Menger」の意訳です。元記事の投稿は2020年10月2日、Amir YazdanbakhshさんとJunchaeo Chenさんによる投稿です。
アイキャッチ画像のクレジットはwikipediaよりNiabot
分散設定でのリプレイバッファの効率をよりよく理解するために、16MBから512MBまでの様々な転送データサイズと16から2048まで行為者(actor)数を変化させて平均書き込み待ち時間を評価しました。
リプレイバッファと行為者は同じBorgセルに配置します。行為者の数が増えると、平均書き込み待ち時間も大幅に増加します。行為者の数を16から2048に拡張すると、平均書き込み待ち時間は、転送データサイズが16MBと512MBの場合、それぞれ約6.2倍と約18.9倍に増加します。この書き込み待ち時間の増加は、データ収集時間に悪影響を及ぼし、全体的なトレーニング時間の非効率につながります。
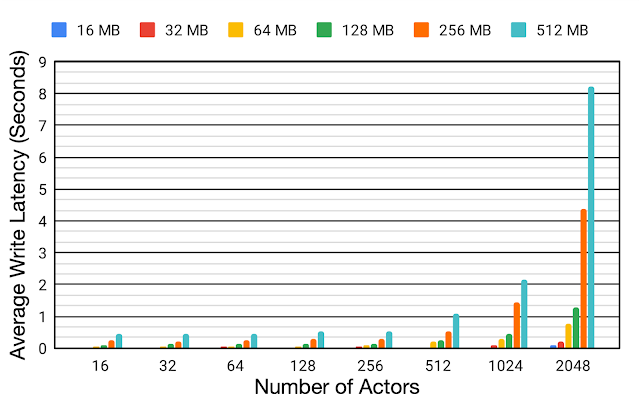
行為者とリプレイバッファーが同じBorgセルに配置されている場合の、様々な転送データサイズ(16MB~512MB)と様々な数の行為者(16~2048)に対する単一のReverbリプレイバッファーへの平均書き込み待ち時間
これを軽減するために、Reverbが提供する水平分割機能(Sharding)を使用して、行為者、学習者(learner)、およびリプレイバッファーサービス間のスループットを向上させます。
水平分割は、単一のリプレイバッファーサーバーを調整するのではなく、複数のリプレイバッファーサーバーにまたがる多数の行為者からの書き込み負荷を分散し、各リプレイバッファーサーバーの平均書き込み待ち時間を最小限に抑えます(同じサーバーを共有する行為者が少ないため)。
これにより、Mengerは複数のBorgセルにまたがる数千人の行為者に効率的に拡張できます。
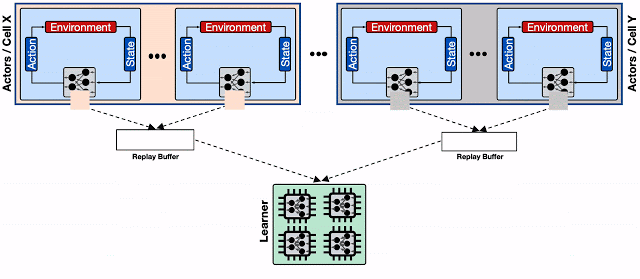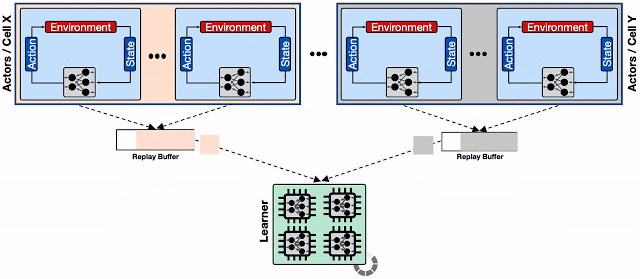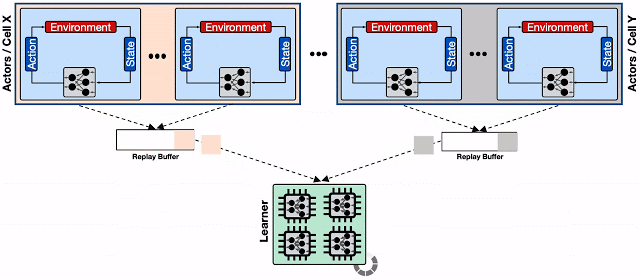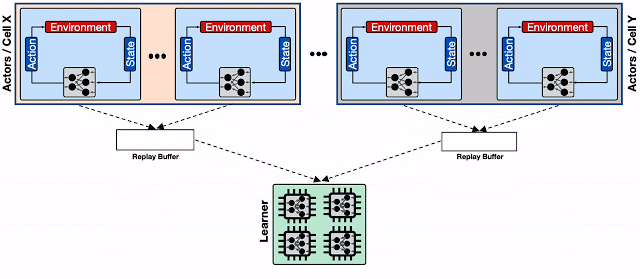
Shardingされたリプレイバッファを備えた分散RLシステム
各リプレイバッファサービスは、通常同じBorgセルにある行為者の集り専用のデータストレージです。更に、水平分割されたリプレイバッファー構成は、アクセラレータコアにより高いスループットの入力パイプラインを提供します。
ケーススタディ:チップの配置
大規模なチップ配置の設計という複雑なタスクにおけるMengerの利点を調査しました。Mengerは512個のTPUコアを使用して、比較対象とした強力な手法と比較して、トレーニング時間を大幅に改善しました(最大8.6倍、トレーニング時間を最大8.6時間から最速の構成でわずか1時間に短縮)。MengerはTPU用に最適化されていますが、このパフォーマンス向上の重要な要素はアーキテクチャであり、GPUでの使用に合わせて調整すると、同様の性能向上が見られると予想されます。
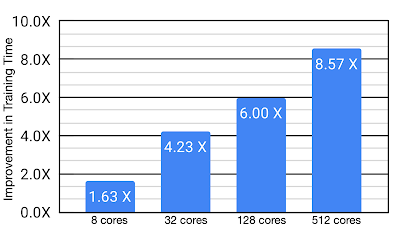
チップ配置タスクで基準手法と比較したMengerを使用したトレーニング時間の改善
Mengerと、チップ配置の複雑なタスクにおけるその有望な結果は、チップ設計サイクルをさらに短縮する革新的な道筋を示していると信じています。また、チップ設計プロセスのさらなる革新を可能にするだけでなく、他の挑戦的な現実世界のタスクも可能にする可能性があります。
謝辞
ほとんどの作業は、Amir Yazdanbakhsh, Junchao Chen, Yu Zhengによって行われました。また、Robert Ormandi, Ebrahim Songhori, Shen Wang, TF-Agents team, Albin Cassirer, Aviral Kumar, James Laudon, John Wilkes, Joe Jiang, Milad Hashemi, Sat Chatterjee, Piotr Stanczyk, Sabela Ramos, Lasse Espeholt, Marcin Michalski, Sam Fishman, Ruoxin Sang, Azalia Mirhosseini, Anna Goldie, Eric Johnsonの支援とサポートに感謝します。
3.Menger:大規模な分散型強化学習(3/3)関連リンク
1)ai.googleblog.com
Massively Large-Scale Distributed Reinforcement Learning with Menger
2)github.com
deepmind / reverb

