
1.pQRNN:射影とクラスタリングで一部のNLPタスクを効率化(2/2)まとめ
・pQRNNは前世代のモデルであるPRADOを更に改良したNLPモデルで3要素で構成
・pQRNNは事前処理を一切行わず、テキスト入力だけから文脈表現を学習可能なネットワーク
・130万のパラメータのpQRNNは1億1000万パラメータのBERTに匹敵する性能を示した
2.pQRNNとは?
以下、ai.googleblog.comより「Advancing NLP with Efficient Projection-Based Model Architectures」の意訳です。元記事の投稿は2020年9月21日、Prabhu Kaliamoorthiさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Isi Parente on Unsplash
PRADOの改良
PRADOの成功に基づいて、pQRNNと呼ばれる改良されたNLPモデルを開発しました。
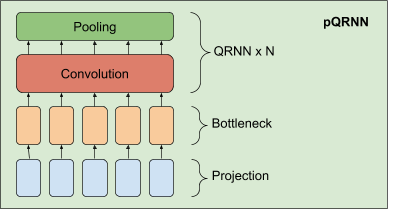
このモデルは、3つの要素
・射影レイヤー(projection layer)
・密なボトルネックレイヤー
・QRNNエンコーダーのスタック
から構成されています。
pQRNNで使用している射影レイヤーの実装は、PRADOで使用されるものと同じであり、モデルを定義するための固定のパラメーターセットなしで最も関連性の高いトークンを学習するのに役立ちます。
最初にテキスト内のトークンから指紋を採り、単純なマッピング関数を使用してそれを3次元の特徴表現ベクトルに変換します。これにより、テキストを一意に表し、分散もバランスが取れている3次元ベクトルの並びが生成されます。
しかし、この特徴表現は、対象タスクを解決するために必要な情報がなく、ネットワークがこの特徴表現を制御できないため、直接的には役に立ちません。これを密なボトルネックレイヤーと組み合わせて、ネットワークが現在のタスクに関連する単語毎の特徴表現を学習できるようにします。
ボトルネックレイヤーから生じる特徴表現は、まだ単語の文脈を考慮に入れていません。双方向QRNNエンコーダーのスタックを使用して、文脈表現を学習します。その結果、事前処理を一切行わず、テキスト入力だけから文脈表現を学習できるネットワークが実現します。
パフォーマンス
Civil_commentsデータセットでpQRNNを評価し、同じタスクでBERTモデルと比較しました。
「モデルのサイズはパラメータの数に比例する」という単純な理由により、pQRNNはBERTよりもはるかに小さくなります。ただし、更に、pQRNNのパラメータを量子化すると、モデルサイズは更に4分の1に縮小されます。
公的に利用可能な事前トレーニング済みバージョンのBERTは比較対象としたタスクのパフォーマンスが低いため、可能な限り最高のパフォーマンスを実現するために、いくつかの異なる関連する多言語データソースで事前トレーニングしたBERTと比較しました。
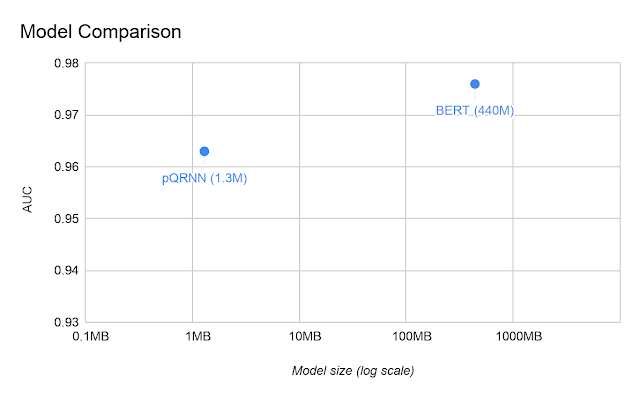
2つのモデルの曲線下面積(AUC:Area Under the Curve)の視覚化
事前トレーニングを一切行わず、教師ありデータでトレーニングしただけの条件で、130万の量子化(8ビット)パラメータを使用してpQRNNは0.963のAUCを達成します。
いくつかの異なるデータソースを使った事前トレーニングと教師ありデータを使った微調整、及び1億1000万の浮動小数点パラメータを使用したBERTモデルのAUCは0.976です。
結論
前世代のモデルPRADOを、次世代の最先端の軽量テキスト分類モデルの基盤として使用する方法を示しました。そのようなモデルの1つとしてpQRNNを提示し、この新しいアーキテクチャが300倍少ないパラメータと教師有りデータのみでトレーニングされているにもかかわらず、BERTに匹敵するレベルのパフォーマンスをほぼ達成できることを示しました。この分野のさらなる研究を促進するために、私たちはPRADOモデルをオープンソースとして公開しました。コミュニティが新しいモデルアーキテクチャの出発点としてこれを使用することを奨励しています。
謝辞
オープンソース化の取り組みに貢献し、モデルの改善に貢献してくれたYYicheng Fan, Márius Šajgalík, Peter Young 及びArun Kandoorに感謝します。Amarnag Subramanya, Ashwini Venkatesh, Benoit Jacob, Catherine Wah, Dana Movshovitz-Attias, Dang Hien, Dmitry Kalenichenko, Edgar Gonzàlez i Pellicer, Edward Li, Erik Vee, Evgeny Livshits, Gaurav Nemade, Jeffrey Soren, Jeongwoo Ko, Julia Proskurnia, Rushin Shah, Shirin Badiezadegan, Sidharth KV, Victor Cărbune 及び the Learn2Compress teamのサポートにも感謝します。
この研究プロジェクトを後援してくれたAndrew TomkinsとPatrick Mcgregorに感謝します。
3.pQRNN:射影とクラスタリングで一部のNLPタスクを効率化(2/2)関連リンク
1)ai.googleblog.com
Advancing NLP with Efficient Projection-Based Model Architectures
2)www.aclweb.org
PRADO: Projection Attention Networks for Document Classification On-Device(PDF)
3)blog.floydhub.com
Tokenizers: How machines read
4)github.com
models/research/sequence_projection/
