
1.オフライン強化学習における未解決の課題への取り組み(2/3)まとめ
・D4RLは現実的なアプリケーションを念頭に作られたベンチマークである事が特徴
・タスクの目的と違う目的を実行した記録から学習する能力などが試される
・タスクと標準化されたデータセットをPythonパッケージにまとめている
2.D4RLに含まれるタスク
以下、ai.googleblog.comより「Tackling Open Challenges in Offline Reinforcement Learning」の意訳です。元記事の投稿は2020年8月20日、George TuckerさんとSergey Levineさんによる投稿です。
Franka kitchenタスクはレシピ本やレシピビデオを元にオフライン強化学習で料理を学習していく家庭用お料理ロボットがもうすぐそこまで来てる事を感じさせますね。現時点でもカレーぐらいだったら出来てしまうのだろうな、と感じます。
アイキャッチ画像のクレジットはPhoto by Jilbert Ebrahimi on Unsplash
広く使用されているMuJoCo(Multi-Joint dynamics with Contact)移動タスクとは別に、D4RLにはより複雑なタスクのデータセットが含まれています。
例えば、Adroit領域のタスクはハンマーを使用するために現実的なロボットハンドを操作する必要があります。このタスクには、人間による実演に制限が加わった状況で行われる課題がありますが、こういったタスクは非常に困難です。
従来の研究「Behavior Regularized Offline Reinforcement Learning」では、既存のデータセットを使った比較では様々な手法を区別できないことが判明しましたが、Adroitタスクを使うとそれらの手法間の明確な欠陥が明らかになりました。
現実世界のタスクを強化学習で実現する際に考えられるもう1つの一般的なシナリオは、トレーニングに使用可能なデータセットが、トレーニングの目的と直接関係しないケースです。
つまり、対象のタスクに関連しているが目的は一致していない他の様々な行動を実行するエージェントから収集された履歴を使用するシナリオです。
例えば、人間の運転手の運転履歴データは、車をうまく運転する方法を示しているかもしれませんが、必ずしも特定の目的地に到達する方法を示す必要はありません。
この場合、オフラインのRLを使用して、運転データセット内のルートの一部を「stitch(スティッチ:縫い合わせる)」する事で、実際にはデータに存在しないタスク(つまり、ナビゲーション)を実行できます。
説明的な例として、下の図で「A」と「B」のラベルが付けられた道順が与えられた場合、オフラインRLは道順を再混合して道順Cを生成できるはずです。
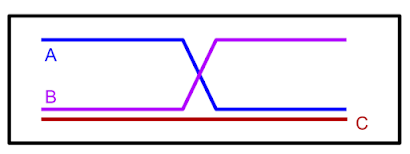
道順AとBのみを観察した時、
それらを組み合わせて最短経路Cを形成できます。
この「stitch」機能を実行するために、次第に困難になる一連のタスクを作成しました。 以下に示す迷路環境では、一連の迷路内の場所に移動するために2つのロボット(単純なボール型または蟻型ロボット)が必要です。

D4RLの迷路ナビゲーション環境
データセット内になかった新しいナビゲーション目標を達成するために道順を「stitch」する事が必要になります。
より複雑な「stitch」シナリオには、Franka kitchen領域のタスク(キッチンシミュレータでMuJoCoを使用するためにadept_envsを利用)があります。
VRインターフェースを使用した人間によるデモンストレーションがマルチタスクデータセットで構成され、オフラインRLメソッドはこのデータを再度「再混合」する必要があります。

Franka kitchen領域のタスクでは、シミュレートされたキッチンで様々なタスクを実行する人間のデモデータを使用する必要があります。
最後に、D4RLには、既存のドライビングシミュレータに基づく2つのタスクが含まれています。
これらのタスクは現実世界のアプリケーションに対するオフラインRLの使用可能性をより正確に反映するはずです。
1つは、Intelが開発し、広く使用されているCARLAシミュレーターを利用した一人称運転のデータセットで、現実的な運転目線で写真のような画像を提供します。
もう1つは、カリフォルニア大学バークレー校のFLOWの交通流制御シミュレーターからのデータセットで、効果的な交通の流れを促進するために自律車両を制御する必要があります。
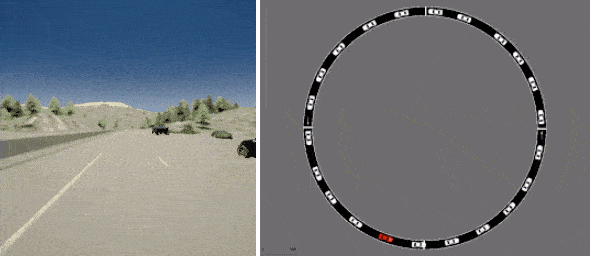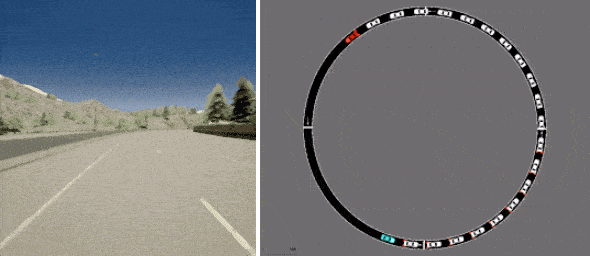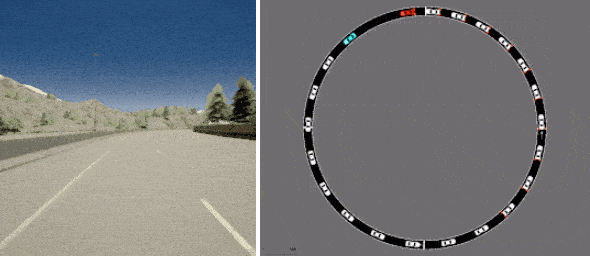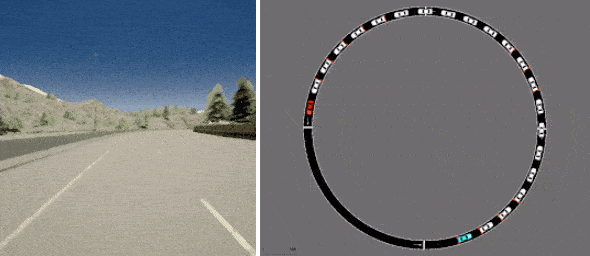
D4RLには、CARLAを使用した運転(左)およびFLOWを使用した交通管理(右)のための既存の現実的なシミュレーターに基づくデータセットが含まれています。
これらのタスクと標準化されたデータセットを研究を加速するために、使いやすいPythonパッケージにパッケージ化しました。更に、新しいアプローチのベースラインとして、関連する従来の手法(BC、SAC、BEAR、BRAC、AWR、BCQ)を使用した全てのタスクのベンチマーク番号を提供します。
オフラインRLのベンチマークを提案するのは私たちが最初ではありません。これまでの多くの研究で、実行中のRLアルゴリズムに基づく単純なデータセットが提案されています。そして、最近のいくつかの研究では、画像観測やその他の機能を備えたデータセットが提案されています。
ただし、D4RLのより現実的なデータセット構成は、関連分野での進歩を促進する効果的な方法になると考えています。
3.オフライン強化学習における未解決の課題への取り組み(2/3)関連リンク
1)ai.googleblog.com
Tackling Open Challenges in Offline Reinforcement Learning
2)sites.google.com
Datasets for Deep Data-Driven Reinforcement Learning
CONSERVATIVE Q-LEARNING FOR OFFLINE RL
3)arxiv.org
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Behavior Regularized Offline Reinforcement Learning
4)github.com
google-research / relay-policy-learning / adept_envs
