
1.RWRL:強化学習の課題に取り組むための一連のシミュレーション(2/2)まとめ
・RWRLは現在のRLが抱える9つの異なる課題のうち8つに関連する実験を行う機能を提供
・複数の課題と難易度レベルを組み合わせた環境でアルゴリズムをテストする事が可能
・RWRLは将来のRLアプリケーションを製品展開させるために必要な進展を加速すること
2.RWRLでサポートされている課題
以下、ai.googleblog.comより「A Simulation Suite for Tackling Applied Reinforcement Learning Challenges」の意訳です。元記事の投稿は2020年8月12日、Daniel J. MankowitzさんとGabriel Dulac-Arnoldさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Adam Winger on Unsplash
サポートされている課題
RWRLスイートは、現在のRLアルゴリズムを応用システムに適用することを困難にしている9つの異なる課題のうち8つに関連する実験を行う機能を提供します。
(1)サンプル効率(sample efficiency)
(2)システム遅延(system delays)
(3)高次元状態空間とアクション空間(high-dimensional state and action spaces)
(4)制約(constraints)
(5)部分的な観測可能性(partial observability)
(6)確率性と非定常性(stochasticity and non-stationarity)
(7)複数の目的(multiple objectives)
(8)リアルタイム推論(real-time inference)
(9)オフラインログからのトレーニング(training from offline logs)
RWRLは、説明可能性の課題(explainability challenge)を除外します。この課題は、抽象的であり、定義するのが簡単ではないためです。
サポートされている実験は網羅的ではありませんが、研究者や実践者に、各課題に関して対処するエージェントの能力を分析する機能を提供します。サポートされている課題の例は次のとおりです。
・システム遅延
ほとんどの現実世界のシステムでは、センサー、動力、または報酬フィードバックのいずれかに遅延が発生します。RWRLスイートではこれら全てに関して遅延を設定し、任意のタスクに適用できます。
以下のグラフは、D4PGエージェントのパフォーマンスを示しています。アクション(左)、観測(中央)、 そして報酬(右)はX軸が右に行くにつれて遅延しています。
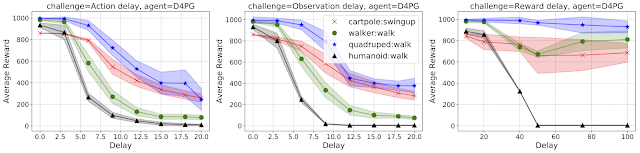 4つのMuJoCo(Multi-Joint dynamics with Contact)ドメインの最新のRLエージェントで、アクション(左)、観察(中央)、および報酬(右)の遅延をそれぞれ増加させています。
4つのMuJoCo(Multi-Joint dynamics with Contact)ドメインの最新のRLエージェントで、アクション(左)、観察(中央)、および報酬(右)の遅延をそれぞれ増加させています。グラフからわかるように、研究者または実践者は、どのタイプの遅延がエージェントのパフォーマンスに最も影響を与えているかについて、すぐに洞察を得ることができます。これらの遅延を組み合わせて、その効果を観察することもできます。
・制約
ほとんど全ての応用システムは、何らかの形で制約を持ちます。これらの制約は(例えばシステムに負荷をかけすぎないように速度に一定の範囲の制限をする等)応用システムが目的を達成するために必要な事ですが、こういった制約は、ほとんどのRL環境では一般的ではありません。
RWRLスイートは、制約付きRLの研究を容易にするために、様々な困難を伴う各タスクに一連の制約を実装します。角速度が速くなりすぎないように制約を課している例は、以下のビデオで視覚化されています。

カートポールタスクが制約違反をしている例
画面が赤くなった瞬間は角速度に関する制約違反が発生したことを示しています。
・非定常性
ユーザーは、環境パラメーターをわずかに変更する事によって非定常性に対するテストを実施できます。これらのわずかな変更(摂動)は、教師あり深層学習の研究で最近人気を得ている画素レベルの敵対的な摂動とは対照的です。
例えば、ヒューマンウォーカー領域では、トレーニング中に「頭のサイズ」や「地面の摩擦」を変更して、どのような状態変化が起こるかをシミュレートできます。
RWRLスイートでは、最先端の学習アルゴリズムの学習機能にハンディを与えるために慎重に定義された、複数のデフォルトパラメータ摂動とともに、様々なスケジューラーを使用できます。
詳細については、githubのrealworld_env.pyを参照してください。

非定常な摂動
このスイートは、頭のサイズ(中央)や接触時の摩擦(右)の変更など、エピソード全体で環境パラメータの摂動をサポートします。
・オフラインログデータを使った学習
ほとんどの応用システムでは、実験を実際に実行するのは時間も費用もかかります。多くの場合、以前行った実験のログデータがポリシーのトレーニングに利用可能です。
ただし、データが制限されている、分散が小さい、または品質が低いため、本番環境で以前のモデルよりも性能を発揮することが難しい場合があります。
これに対処するために、RWRLベンチマークの課題を組み合わせたオフラインデータセットを生成しました。これは、オフラインデータセットのリリースの一環として利用可能にしたものです。
詳細については、コラボ(rwrl_d4pg.ipynb)をご覧ください。
結論
ほとんどのシステムでは課題が一つしかない事はめったにありません。私達は、複数の課題と難易度レベル(簡単, 普通, 難しい)が組み合わさった環境でアルゴリズムがどのようにこれらの課題に対処できるかを見て興奮しています。
私達は、研究コミュニティがこれらの課題に挑戦してみる事を強くお勧めします。これらの課題を解決することで、製品や現実世界のシステムへの強化学習をより広範囲に適用出来るようになると信じているからです。
今回発表したRWRLスイートの機能と実験の初版は、現在のRLシステムと応用システム間のギャップを埋めるための出発点となりますが、まだやらなければならないことがたくさんあります。
サポートされている実験は網羅的ではなく、RLエージェントの機能をよりよく評価するために、より広いコミュニティからの新しいアイデアを歓迎します。このスイートの主な目標は、応用製品及びシステムで強化学習アルゴリズムの有効性を制限する主な問題に関する研究を浮き上がらせ、研究を奨励し、将来のRLアプリケーションの有効化に向けた進展を加速することです。
謝辞
中心的な貢献者であり、共著者でもあるNir Levineの貴重な支援に感謝します。また、共同執筆者のJerry Li, Sven Gowal, Todd Hester, Cosmin Paduraru, Robert Dadashi, the ACME team, Dan A. Calian, Juliet Rothenberg, Timothy Mannの貢献にも感謝します。
3.RWRL:強化学習の課題に取り組むための一連のシミュレーション(2/2)関連リンク
1)ai.googleblog.com
A Simulation Suite for Tackling Applied Reinforcement Learning Challenges
2)arxiv.org
Challenges of Real-World Reinforcement Learning
3)github.com
google-research/realworldrl_suite
google-research/realworldrl_suite/realworld_env.py
deepmind/deepmind-research/rwrl_d4pg.ipynb

