
1.自己教師学習で音声特徴表現と個人専用モデルを改善(2/2)まとめ
・同じ音声のembeddingは、別の音声のembeddingよりembedding空間内で近い場所に位置するはず
・これを利用しBERTと同様なデータ自体の構造にのみ依存した自己教師学習で特徴表現を学習した
・TRILLはMobileNetに基づいているため高速で従来の特徴表現と比べても高い性能を発揮するモデル
2.TRILLとは?
以下、ai.googleblog.comより「Improving Speech Representations and Personalized Models Using Self-Supervision」の意訳です。元記事は2020年6月18日、Joel ShorさんとOran Langさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Talles Alves on Unsplash
TRILL:非セマンティックスピーチ分類における最先端のテクニック
1つのデータセットからembeddingを学習し、それを他のタスクに適用することは、文章や画像を対象としている研究ほど、音声分野では一般的ではありません。
ただし、あるタスクからのデータを使用して(必ずしもembeddingではない)別のタスクを支援するより一般的な手法である転移学習には、パーソナライズした音声認識や少数のサンプルから音声を模倣するテキスト音声変換など、魅力的なアプリケーションがいくつかあります。
以前に提案された音声特徴表現は多数ありますが、これらのほとんどは、小規模で多様性の低いデータでトレーニングされているか、主に音声認識でテストされています。
様々な環境やタスクで役立つデータから派生した音声特徴表現を作成するために、約2500時間の音声を含む大規模で多様なデータセットであるAudioSetから始めました。
次に、メトリック学習に関するこれまでの研究から導き出された、自己教師で計測した距離に基づいてembeddingモデルをトレーニングします。つまり、同じ音声から作られたembeddingは、別の音声から作られたembeddingよりもembedding空間内で近い場所に位置するはずであり、この性質を利用します。
BERTおよびその他のテキストembeddingと同様に、自己教師損失関数はラベルを必要とせず、データ自体の構造にのみ依存します。
そのため、この形式の自己教師は、非セマンティック音声(NOSS:NOn-Semantic Speech)に最も適しています。非セマンティック音声の音声特性は、自動音声認識等で使われる1秒未満の音声特性よりも時間的に安定しているためです。この単純な自己教師による判定基準は、下流タスクで活用される多数の音響特性を取得できます。
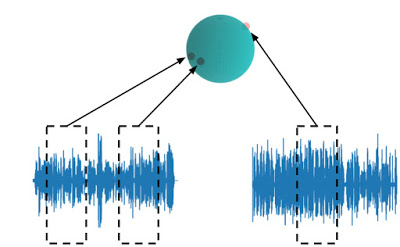
TRILLの損失
同じ音声からのembeddingは、異なる音声からのembeddingよりもembedding空間内で近くになります。
TRILLアーキテクチャはMobileNetに基づいているため、迅速な応答が求められるモバイルデバイスで実行するのに十分な速度です。この小さなアーキテクチャで高精度を達成するために、パフォーマンスを低下させることなく、より大きなResNet50モデルからembeddingを抽出しました。
ベンチマーク結果
TRILLのパフォーマンスを、他のディープラーニングによる特徴表現と比較しました。これらの特徴表現は音声認識に重点を置いていませんが、同様に多様なデータセットでトレーニングされています。
更に、TRILLを人気のあるOpenSMILE特徴抽出器やランダムに初期化されたネットワーク等と比較しました。これらはディープラーニングが主流になる前の時代のテクニック(フーリエ変換係数、時系列のピッチ測定を使用した「ピッチトラッキング」など)を使用したネットワークも含まれますが、強力な比較対象モデルとなる事が示されています。
異なるパフォーマンス特性を持つタスクのパフォーマンスを集約するため、まず、特定のタスクとembeddingで少数の単純なモデルをトレーニングし、最良の結果を選択しました。
次に、特定のembeddingが全てのタスクに与える影響を理解するために、モデルとタスクの両方を説明変数として、計測された精度に対する線形回帰を計算します。
モデルが精度に与える影響は、回帰モデルに関連付けられた係数です。
特定のタスクで、あるモデルから別のモデルに変更する場合、結果として生じる精度の変化は、下図のy値の違いになると予想されます。
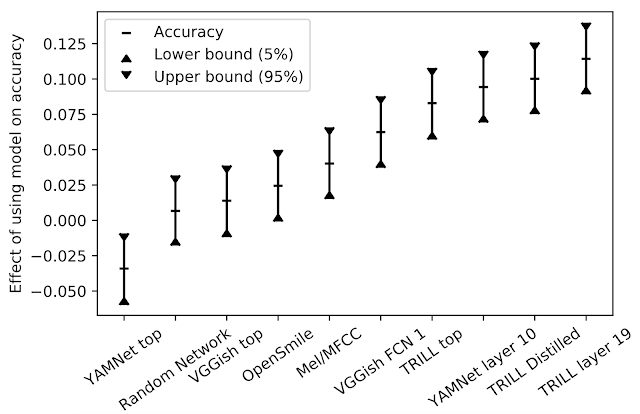
モデルが精度に与える影響
TRILLは、私達の研究では他の特徴表現よりも優れています。
TRILLの成功に寄与した要素は、トレーニングデータセットの多様性、大きなコンテキストウィンドウを持つネットワーク、早い段階で特定の側面に焦点を合わせるのではなく、音響特性を広く維持するTRILLのトレーニング損失の一般性です。
多くの場合、中間ネットワーク層から得た特徴表現がより一般的に役立ちます。 中間表現はより大きく、時間的粒度がより細かく、分類ネットワークの場合、それらは訓練されたクラスに固有ではないより全般的な情報を保持します。
全般的に有用なモデルのもう1つの利点は、新しいタスクでモデルを初期化するために使用できることです。新しいタスクの学習用データが小さい場合、既存のモデルを微調整した方が、モデルを最初からトレーニングするよりも良い結果が得られる場合があります。データセット固有のハイパーパラメータ調整を行わなかったにもかかわらず、この手法を使用して、6つのベンチマークタスクのうち3つで新しい最先端のスコアを達成しました。
私達の新しい特徴表現をテストするために、Interspeech 2020 Computational Paralinguistics Challenge(ComParE)で行われたマスクサブチャレンジに挑戦しました。この課題では、モデルは話し手がマスクを着用しているかどうかを予測する必要がありました。マスクの着用が音声に与える影響はわずかな場合があり、オーディオクリップの長さはわずか1秒でした。TRILLの線形モデルは、従来のスペクトルや深層学習を含むさまざまな種類の特徴を融合した最良のベースラインモデルよりも優れていました。
まとめ
非セマンティック音声(NOSS:NOn-Semantic Speech)を評価するコードはGitHubから利用できます。データセットはTensorFlow Datasetsから利用でき、TRILLモデルはAI Hubから利用できます。
NOSSベンチマークは、研究者が、パーソナライゼーションや小さなデータセットの問題など、様々な状況で役立つ音声embeddingsを作成するのに役立ちます。私達は、TRILLモデルをembeddingsの性能測定の際の比較対象基準モデルとして研究コミュニティに提供します。
謝辞
この研究の中心チームには、Joel Shor, Aren Jansen, Ronnie Maor, Oran Lang, Omry Tuval, Felix de Chaumont Quitry, Marco Tagliasacchi, Ira Shavitt, Dotan Emanuel 及び Yinnon Havivが含まれます。
また、技術的なガイダンスを提供してくれたAvinatan HassidimとYossi Matiasにも感謝します。
3.自己教師学習で音声特徴表現と個人専用モデルを改善(2/2)関連リンク
1)ai.googleblog.com
Improving Speech Representations and Personalized Models Using Self-Supervision
2)arxiv.org
Towards Learning a Universal Non-Semantic Representation of Speech
3)github.com
google-research/non_semantic_speech_benchmark/
4)aihub.cloud.google.com
nonsemantic-speech-benchmark
5)www.tensorflow.org
TensorFlow Datasets
