
1.AttentionAgent:重要度が低い情報を無視する強化学習エージェント(1/2)まとめ
・人間は選択的注意の仕組みにより膨大な情報を圧縮し意思していると考えられている
・強化学習エージェントは逆に全視覚情報に加えて将来予測まで情報として受け取っている
・注意に制約を課してエージェントの視覚情報を軽減するとパフォーマンスが向上するのではないか?
2.AttentionAgentとは?
以下、ai.googleblog.comより「Using Selective Attention in Reinforcement Learning Agents」の意訳です。元記事の投稿は2020年6月18日、Yujin TangさんとDavid Haさんによる投稿です。
久々にGoogle Research, Tokyo所属の皆さんの投稿で、David Haさんは過去にAdam Gaierさんと共に本能をヒントにした強化学習WANNの投稿もされてました。
アイキャッチ画像は今まさに選択的注意を実行してそうな兎でクレジットはPhoto by Gavin Allanwood on Unsplash
非注意性盲目(Inattentional blindness)は、明確な視界の中で見落としが発生する原因となりますが、重要でない細部に気を取られる事なく、重要な部分に集中し続けることを可能にする「選択的注意(selective attention)」の結果です。
訳注:非注意性盲目は、視覚障害などの影響ではなく純粋に注意力の欠如で見落としが発生する現象で、以下のハーバード大学の動画実験などが有名です。お題を絶対間違えない気概で超集中して以下の動画をご覧ください。
人間は、この選択的注意の仕組みにより、広範囲から絶え間なく受け取る感覚情報をコンパクトに圧縮し、将来の意思決定に使用できるようにしていると考えられています。
これは制限のように思えるかもしれませんが、自然界に見られるこのような「ボトルネック」は機械学習システムの設計にも影響を与えます。機械学習システムは、自然界の生物の効率性と完成度を模倣出来るようになる事を期待されているからです。
例えば、強化学習(RL:Reinforcement Learning)の文献に示されているほとんどの手法では、エージェントは全ての視覚入力にアクセスできます。予測した視覚情報を受け取る、つまり、次に入力される視覚情報を予測するモジュールを組み込むことさえもできます。
注意の仕組みに制約を課してエージェントが受け取る視覚情報を軽減する事は、もしかしたらエージェントのパフォーマンスに有益なのではないでしょうか?
最近の発表したGECCO 2020の論文「Neuroevolution of Self-Interpretable Agents」(AttentionAgent)では、「自己注意のボトルネック(self-attention bottleneck)」を組み込んだエージェントの特性を調査します。
従来の方法と比較して学習可能なパラメーターを1000倍減らしましたが、難しい視覚タスクを解決できました。また、単に「詳細を見ない」特性を持つため、タスク実行の際に混乱を引き起こする可能性がある微細な変更に対する一般化にも優れています。
更に、エージェントがどこに注意を向けているかを見る事により、意思決定プロセスを視覚的に解釈できます。以下の図は、エージェントが注意のボトルネックに対処する方法を示しています。

AttentionAgentは、視覚入力の重要な領域に注意を向ける事を学習しました。
車運転ゲーム(CarRacing、上の行)では、エージェントは主に道路の境界に注意を向けていますが、方向を変える前に回転(turn)に注意を移します。火の玉をかわすゲーム(DoomTakeCover、下の行)では、エージェントは火の玉と敵のモンスターに焦点を合わせています。
左:エージェントに与えられる視覚的入力
中央:視覚的入力にエージェントの注意を重ね合わせた結果。白枠の範囲はエージェントが注意を集中している箇所を示します。
右:エージェントの意志決定に繋がった視覚的きっかけ
人工的な注意メカニズムを汲み込んだエージェント
強化学習エージェントに制約を課す事の有用性を探るいくつかの研究がありますが、AttentionAgentは、「非注意性盲目(Inattentional blindness)」関連する概念から発想を得ています。
すなわち、脳は注力を必要とするタスクを実行している場合、その注意能力のほとんどをタスクに関連する要素にのみに割り当て、他のタスクに関わらない信号に対して一時的に盲目になります。
私達はこれと同等な機能を実現するために、入力画像を細かい範囲に分割しました。次に自己注意アーキテクチャを変更し、範囲間で投票を行い、重要と見なされる範囲を選択できるようにします。
重要と見なされる対象範囲は各タイムステップで選択され、一度決定されると、AttentionAgentは残りの範囲を無視して、選択範囲のみを参照して意思決定を行います。
視覚的な入力から主要な要素を抽出することに加えて、これらの要素が時間とともに変化するときにこれらの要素を継続的に追跡する機能も同様に重要です。
例えば、野球の試合の打者は、ボールの位置を予測して打つことができるように、視覚信号を継続的に使用してボールの位置を追跡する必要があります。
AttentionAgentでは、Long Short-term Memory(LSTM)モデルが重要な範囲の情報を受け取り、各タイムステップでアクションを生成します。LSTMは入力情報の変化を追跡できるため、この情報を利用して、重要な要素が時間とともにどのように変化するかを追跡できます。
ニューラルネットワークを最適化する際は誤差逆伝播法(Backpropagation)を使用するのが一般的です。 ただし、AttentionAgentには、重要な範囲を生成する際に並び替えや分割などの操作が含まれており、これらは微分不可能な操作であるため、誤差逆伝播法を適用することは簡単ではありません。
この困難を克服するために、私達は微分演算が不要な最適化アルゴリズムに目を向けます。
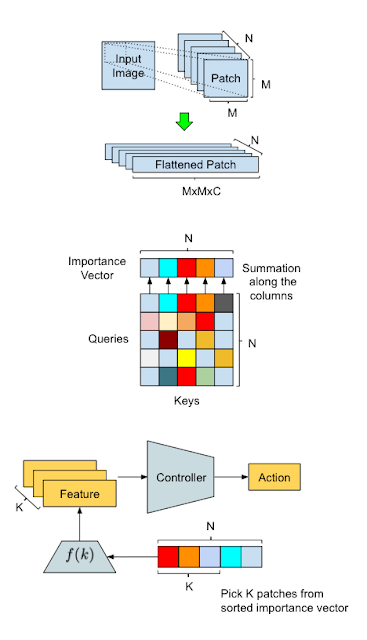
私達の手法の概要とAttentionAgentのデータ処理フロー図
上図:入力変換。スライディングウィンドウは、入力画像を小さな範囲に分割し、それらを将来の処理のために「平坦化」します。
中央:範囲の選択。変更した自己注意モジュールは、各範囲の重要度を保持するベクトルを生成するために範囲間で投票を実施します。
下図:アクション生成。AttentionAgentは最も重要な範囲を選択し、対応する特徴表現を抽出して、それらに基づいて決定を行います。
3.AttentionAgent:重要度が低い情報を無視する強化学習エージェント(1/2)関連リンク
1)ai.googleblog.com
Using Selective Attention in Reinforcement Learning Agents
2)attentionagent.github.io
Neuroevolution of Self-Interpretable Agents
3)github.com
google / brain-tokyo-workshop / CarRacingExtension


コメント