
1.ロボットが地形を見て適切な歩き方を選択できるようになる(2/2)まとめ
・最初にセマンティックセグメンテーションモデルを学習させる事で学習を効率化
・速度ポリシーからの指令に基づいて歩行スタイルを計算するようにした
・登山同を従来手法より早く安全に踏破可能な4足ロボットが実現できた
2.初見の地形でも適切な歩行スタイルを選択
以下、ai.googleblog.comより「Learning to Walk in the Wild from Terrain Semantics」の意訳です。元記事は2022年9月9日、Yuxiang Yangさんによる投稿です。
アイキャッチ画像はstable diffusion
2つ目の重要な設計上の選択は、学習方法です。
ディープニューラルネットワーク、特に高次元の視覚入力を伴うものは、通常、学習に多くのデータを必要とします。実世界で必要な学習データの量を減らすために、まずRUGD(ロボットに搭載したカメラで撮影した画像に似ている不整地走行データセット)上でセマンティックセグメンテーションモデルを事前学習し、モデルがカメラ画像内の各画素について意味クラス(草、泥など)を予測するようにします。
そして、モデルの中間層から意味embeddingを抽出し、それをロボット上での学習用の特徴量として使用します。あらかじめ学習させた意味embeddingを用いることで、30分以内の実環境データを用いて効率的に速度ポリシーの学習を行うことができ、手間を大幅に削減することができました。
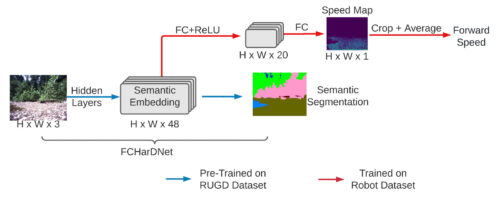
セマンティックセグメンテーションモデルを事前学習させ、ロボットデータ上で微調整するための意味embeddingを抽出します。
歩行スタイル選択とモータ制御
パイプラインの次のコンポーネントである歩行スタイルセレクタは、速度ポリシーからの速度指令に基づいて適切な歩行スタイルを計算します。ロボットの歩行スタイルは踏み込み頻度、振れ幅、底面高さなど、ロボットが異なる地形を踏破する能力に大きく影響します。
科学的な研究により、動物は速度によって異なる歩行スタイルを切り替えることが分かっており、この結果は4足歩行ロボットでさらに検証されています。そこで、速度ごとに堅牢な歩行スタイルを計算するように歩行スタイルセレクタを設計しました。すべての速度で固定歩行スタイルを使用する場合と比較して、歩行スタイルセレクタは不整地地形でのロボットの操作性能をさらに高めることがわかりました(詳細は論文に記載)。
パイプラインの最後のコンポーネントは、モーターコントローラで、速度と歩行スタイルのコマンドをモーター出力に変換します。これまでの研究と同様、私達は遊脚と立脚に別々の制御戦略を用いています。スキル学習とモータ制御のタスクを分離することで、スキルポリシーは望みの速度のみを出力すればよく、低レベルの運動制御を学習する必要がないため、学習プロセスを大幅に簡略化することができます。
実験結果
A1型4足歩行ロボットに本フレームワークを実装し、草地、砂利道、アスファルトなど、ロボットにとって難易度の異なる複数の地形が存在する屋外の登山道で実験を実施しました。例えば、深い草むらでは足が引っかからないように足の振りを大きくしてゆっくり歩く必要がありますが、アスファルトでは足の振りを小さくして速く歩くことでエネルギー効率を高めることができます。
このような違いを捉え、深い草むらでは低速(0.5m/s)、砂利道では中速(1m/s)、アスファルトでは高速(1.4m/s)と、それぞれの地形に適したスキルを選択するフレームワークを実現しました。平均速度0.8m/s(つまり時速1.8マイル、2.9km)で、全長460mの登山道を9.6分で完走することができるのです。一方、非適応ポリシー(non-adaptive policies)は、安全に登山道を完走できないか、著しく遅い速度(0.5m/s)で歩きます。これは、認識した環境に応じて運動能力を適合させることの重要性を示しています。
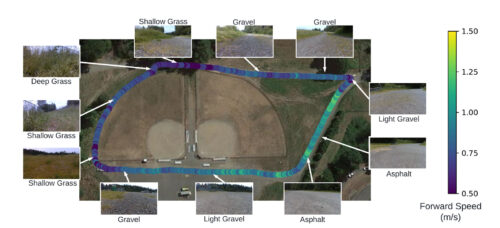
このフレームワークは、登山道の状況に応じて異なる速度を選択します。
また、汎用性を検証するために、訓練時には見られない多くのコースにロボットを配備しました。ロボットはそれらすべてを失敗なく踏破し、地形の持つ意味に基づいて運動スキルを調整します。一般に、スキルポリシーは、硬い地形や平坦な地形ではより速いスキルを選択し、変形しやすい地形や凹凸のある地形ではより遅い速度を選択します。本稿執筆時点で、ロボットは6km以上の屋外登山道を故障することなく踏破しています。

このフレームワークにより、訓練時には見られなかった屋外のさまざまな地形でも安全に歩行することができるようになりました。
まとめ
本研究では、不整地走行のための意味を考慮した移動スキルを学習する階層的フレームワークを提示します。
30分以内の人間のデモデータを用いて、このフレームワークは、知覚された環境の持つ意味に基づいて、ロボットの速度と歩行スタイルを調整する事を学習します。その結果、ロボットは様々な不整地の地形を安全かつ効率的に歩行することができるようになりました。
このフレームワークの限界の1つは、標準的な歩行を行うための運動技能のみを調整し、間隙やハードルのあるより困難な地形を横断するために不可欠なジャンプなど、より機敏な行動をサポートしないことです。
また、本フレームワークでは、希望する経路を辿ってゴールに到達するために、現状では手動による操舵コマンドが必要であることも制約の一つです。将来的には、より機敏な動作を実現するために、高レベルのスキルポリシーと低レベルのコントローラをより深く統合することを検討し、操作と経路計画をフレームワークに組み込んで、ロボットが困難な不整地環境において完全に自律的に動作できるようにする予定です。
謝辞
本論文の共著者に感謝します。
Xiangyun Meng, Wenhao Yu, Tingnan Zhang, Jie Tand そして Byron Boots。
また、議論とフィードバックをいただいたGoogleのロボティクスチームメンバーに感謝します。
3.ロボットが地形を見て適切な歩き方を選択できるようになる(2/2)関連リンク
1)ai.googleblog.com
Learning to Walk in the Wild from Terrain Semantics
2)arxiv.org
Learning Semantics-Aware Locomotion Skills from Human Demonstration

