
1.Big Transfer(BiT):視覚タスクで大規模な事前トレーニングを活用(2/3)まとめ
・BERTと同様にBiTも事前トレーニング済みのモデルを下流タスク用データで微調整をして転移学習する
・事前トレーニングで使用する画像の量とモデルの容量を増やすと微調整後モデルの性能が大幅に向上
・VTABを使った試験でも以前の最先端技術と比べて5.8%の絶対的なスコア改善を達成した
2.BiTのパフォーマンス
以下、ai.googleblog.comより「Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision」の意訳です。元記事の投稿は2020年5月21日、Lucas BeyerさんとAlexander Kolesnikovさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by michael schaffler on Unsplash。
転移学習
BERTによって自然言語領域で確立された転移学習手法に従いました。すなわち、事前トレーニング済みのBiTモデルを、実行したい様々な「下流」タスク用のデータを使って微調整するのです。
これらの下流タスクには、利用可能なラベル付けされたデータがほとんどない場合がありますが、事前トレーニング済みモデルは事前学習によって既に視覚を用いた世界をよく理解しているため、この単純な微調整戦略は非常にうまく機能します。
微調整の際は、学習率(learning-rate)や重みの減衰(weight decay)など、多くのハイパーパラメータを選択する必要があります。
私達は、これらのハイパーパラメータを選択する際に使用できる発見的なルールとして、「BiT-HyperRule」を提案します。BiT-HyperRuleは、画像の解像度やラベル付けされたデータの数など、データセットの特性に基いて設定されます。私達はBiT-HyperRuleを自然画像から医療画像に至るまで、20を超えるさまざまなタスクに適用しました。

BiTモデルを事前トレーニングした後、使用可能なラベル付きデータがほとんどない場合でも、任意の視覚タスク用に微調整できます。
非常に少数のデータしか微調整時に利用できないでタスクにBiTを転移する時、「事前トレーニング時に使用する一般的な画像データの量」と「モデルの容量」を同時に増やすと、微調整後モデルが新しいデータに適応する能力が大幅に向上することがわかりました。
下図では、CIFARを使った1ショット設定(1回だけ微調整)と5ショット設定(5回だけ微調整)で転移学習のパフォーマンスを調査しています。ILSVRC(緑の曲線)で事前トレーニングすると、モデル容量が増加してもパフォーマンスの向上は限られています。
しかし、より大きなデータセットであるJFTで大規模な事前トレーニングを行うと、モデル容量を増えるにつれて、大きなパフォーマンスの向上(茶色の曲線)が得られます。最終的に最も容量の大きいBiT-Lモデルで1ショット設定で64%、5ショット設定で95%の精度を達成します。
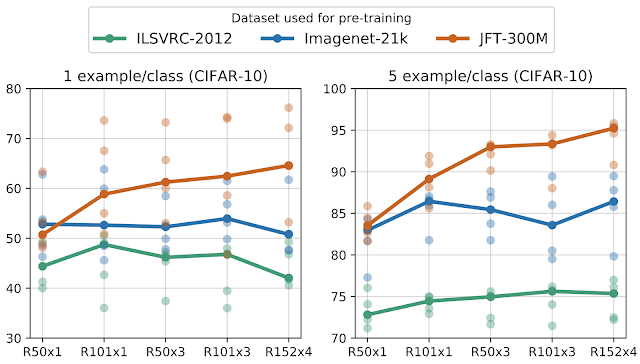
曲線は、5回の独立したテスト結果(薄い○)の中央値を示しています。各クラス毎に1つまたは5つの画像(トータルで10または50画像)を使ってCIFAR-10に転移学習しています。
大規模なデータセットで事前トレーニングされた大規模なアーキテクチャは、データ効率が大幅に向上する事が明らかです。
この結果がより一般的であることを確認するために、VTAB-1kを使ってBiTを評価しました。VTAB-1kは、19の多様なタスクの集合であり、タスクごとにラベル付けされた例は1000のみです。
19全てのVTABタスクにBiT-Lモデルを適用し、全体で76.3%のスコアを達成しました。これは、以前の最先端技術と比べて5.8%の絶対的な改善になります。
3.Big Transfer(BiT):視覚タスクで大規模な事前トレーニングを活用(2/3)関連リンク
1)ai.googleblog.com
Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision
2)arxiv.org
Big Transfer (BiT): General Visual Representation Learning
Group Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Weight Standardization
Self-training with Noisy Student improves ImageNet classification
Exploring the Limits of Weakly Supervised Pretraining
3)www.image-net.org
Large Scale Visual Recognition Challenge 2012 (ILSVRC2012)
4)objectnet.dev
ObjectNet
5)github.com
google-research/big_transfer
6)blog.tensorflow.org
BigTransfer (BiT): State-of-the-art transfer learning for computer vision
