
1.Dreamer:長期視点で考える事が出来る強化学習(2/3)まとめ
・強力な世界モデルでさえ、正確に予測できる範囲が限られており多くは近視眼的だった
・Dreamerは、バリューネットワークとアクターネットワークでこの制限を克服
・Dreamerは、計画と行動を切り離すことによりPlaNetが持つ高価な検索コストを回避
2.DreamerとPlaNetの違い
以下、ai.googleblog.comより「Introducing Dreamer: Scalable Reinforcement Learning Using World Models」の意訳です。元記事の投稿は2020年3月18日、Danijar Hafnerさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Dakota Corbin on Unsplash
PlaNet世界モデルを使用する利点は、画像の代わりにコンパクトなモデル状態を使用して事前に予測することにより、計算効率が大幅に向上することです。これにより、モデルは単一のGPUで数千の可能性を並列に予測できます。
また、このアプローチは一般化を促進し、長期視点での正確なビデオ予測を可能にします。モデルがどのように機能するかについての洞察を得るために、DeepMind Control SuiteのタスクおよびDeepMind Lab環境のタスクを使って調査しました。以下に示すように、コンパクトなモデル状態をデコードして画像に戻すことで予測を視覚化できます。
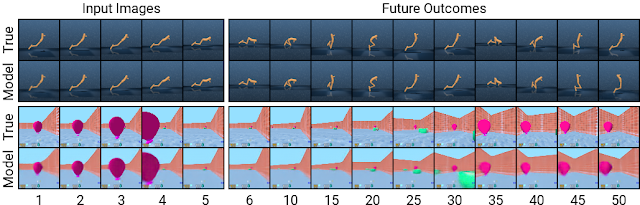
コンパクトなモデル状態を使用して予測をすると、複雑な環境での長期予測が可能になります。ここでは、エージェントが以前に遭遇したことのない2つの状況を示しています。5つの入力画像が与えられると、モデルはそれらを再構成し、タイムステップで50先までの将来の画像を予測します。
効率的な行動学習
以前に開発されたモデルベースのエージェントは通常、多くのモデル予測を通じて計画するか、ワールドモデルをシミュレータの代わりに使用して既存のモデルフリーモデル用のテクニックを再利用することにより、アクションを選択していました。どちらの設計も計算負荷が高く、学習した世界モデルを完全に活用していません。さらに、強力な世界モデルでさえ、正確に予測できる範囲が限られているため、以前のモデルベースのエージェントの多くは近視眼的でした。Dreamerは、世界モデルの予測による逆伝播を介してバリューネットワークとアクターネットワークを学習することにより、これらの制限を克服します。
Dreamerは、アクターネットワークを効率的に学習して、成功アクションを予測します。モデルの状態を連続して予測し、最終的に得られる報酬を逆方向に伝播することにより、これを達成します。これはモデルフリーなアプローチでは不可能です。
これにより、Dreamerはアクションのわずかな変更が将来の報酬の予測にどのように影響するかがわかるので、報酬を最も増加させる方向にアクターネットワークを改良できます。予測期間を超えた報酬を考慮するために、バリューネットワークは各モデルの状態の将来の報酬の合計を推定します。次に、報酬と価値を逆伝播して、アクターネットワークを改良し、改善されたアクションを選択します。

Dreamerは、モデルの状態を連続して予測し、長期視点で行動を学習します。
最初に各状態の長期値(v2–v3)を学習し、次に連続して予測した状態を介してアクターネットワークに逆伝播することにより、高い報酬と値につながるアクション(â1–â2)を予測します。
Dreamerはいくつかの点でPlaNetと異なります。環境内の特定の状況に対して、PlaNetは様々な連続するアクションを予測し、その中から最適なアクションを検索します。
対照的に、Dreamerは、計画と行動を切り離すことにより、この高価な検索コストを回避します。
一度、アクターネットワークが予測された一覧の行動について学習すると、追加の検索なしで環境と対話するためのアクションを計算できます。更に、Dreamerは、バリュー関数を使用して計画期間を超えた報酬を考慮し、効率的な計画のために逆伝播を活用します。
制御タスクのパフォーマンス
20の多様な標準ベンチマークタスクでDreamerを評価しました。これらのタスクは画像による入力と連続的な行動が必要になるタスクで、物体のバランスを取ったり物体をキャッチするタスク、及び様々なシミュレーションロボットの移動が含まれます。
タスクは、強化学習(RL)エージェントに様々な課題を与えるように設計されています。これらの課題にはpredict collisions(衝突の予測:ハードウェアを使って衝突を避ける事を学習させようとすると学習が完了する前にロボットが衝突で壊れる可能性があり困難なタスク), sparse rewards(疎な報酬:迷路探索のようにある道を進む事がゴールに向かっていると言えるのか明確でないため適切なタイミングで報酬が与える事が難しいタスク), chaotic dynamics(カオスな動きの制御), small but relevant objects(小さいが重要な目標:シミュレーションゲームにおける敵弾のような小さく目立たないけれども重大な結果を招く物体が含まれるタスク)、 high degrees of freedom(非常に自由度が高く色々な事ができてしまう環境), そして3D perspectives(三次元視点)などが含まれています。

ドリーマーは、20の挑戦的な連続制御タスクを画像入力で解決することを学びます。上記は、そのうちの5例です。エージェントが環境から受信するものと同じ64×64画像を表示しています。
3.Dreamer:長期視点で考える事が出来る強化学習(2/3)関連リンク
1)ai.googleblog.com
Introducing Dreamer: Scalable Reinforcement Learning Using World Models
2)github.com
google-research/dreamer

コメント